在看本章之前可以先看看上一篇:
Flink的基石 : Chandy Lamport Algorithm
如上篇文章所述“在Flink中实现语义“Exactly once”,采用的是checkpoint,使用的是Asynchronous barrier snapshots 算法,而该算法是根据Chandy Lamport Algorithm进行了一些轻微的变种.",所以研究“Exactly once”执行语义,其实就是研究理解ABS算法。
Flink的计算模型,分为三部分Source Operator 、Transformation Operators 、Sink Operator ,如下图,分别代表了
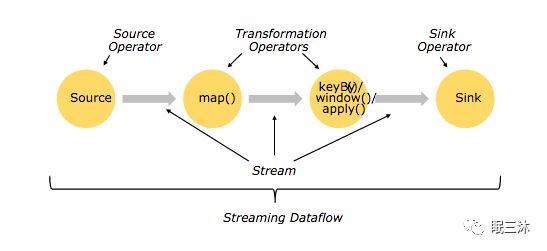
数据来源接入操作器、数据转换处理操作器、数据输出操作器,在接下来介绍论文算法的时候会引入计算模型的关键词,这样能增加对Flink计算模型的理解。
在ABS中使用Barrier来代替Chandy Lamport Algorithm算法中的marker。先上论文中的图。

在图中
src =Source Operator
count=Transformation Operators
print =Sink Operator
流程:
1、由协调中心,周期性的往所有数据源中插入Barriers,当Source Operator接收到一个Barrier,source将启动快照记录当前的状态,如图中"a"
2、source将Barrier广播到它连接的所有Transformation Operator,当Transformation Operator接受到来自一个source发送来的Barrier之后它将阻塞当前这个source(如图“b”下半边,src-1的barrier先到达,然后阻塞src-1,等待src-2的barrier到达),然后等到所有的Source Operator的这个Barrier到达之后,启动快照记录当前的状态(如图“b”上半边)。请研究一下“b”-->"c"的状态转移。
3、当Transformation Operator处理完成之后,他也会像Source Operator将他这个Operator的Barrier广播到它连接的所有sink Operator。如图“d”。当所有sink Operator 接收到它所有连接的Transformation Operator的这个Barrier之后,此次快照的处理就结束。
附上论文精简代码



总结一下ABS的改进,在原来的基础上引入了Barrier对齐操作,使用Barrier对齐,达到了Exactly once执行语义,但是同时也带来了性能损耗,因为在对齐的时候,operator是阻塞了先到达的Barrier的input channel的输入。如果网络发生抖动,有的input channel的Barrier 迟迟未到,此时系统的吞吐量将急剧下降。
当然Exactly once是Flink提供的最高执行语义,你可以关闭Exactly once,开启at least once语义,这个语义的实现其实就是关闭了Barrier对齐。
这个算法讲到这里,基本已经解析完成,但是你觉得有什么问题吗?
在现在这个算法的基础上来讲“Exactly once”语义其实是属于Flink内部系统的,他可以保证flink内部“Exactly once”,但是当Sink Operator将数据输出的时候,他是如何保证成功的呢?
举列:
比如说Flink实时处理一个用户使用APP的次数,最后将数据直接输出到Redis。
1、当数据输出到redis,但是在给返回的时候超时,这个时候Flink回滚到最近的checkpoint,最近的Barrier处,再重新计算,但是此时数据已经输出到了redis,该怎么办。
2、如图中“d”,print1 输出成功,但是print2再输出到redis 的时候失败,这个时候Flink回滚到最近的checkpoint,然而print1的数据已经输出了redis,此时又该怎么办。
其实这是一个"End-to-End Exactly-Once”端到端精确执行一次的问题,为了解决这个问题,Apache Flink 1.4.0 引入了事物控制的二阶段提交。提供了一个抽象类TwoPhaseCommitSinkFunction,实现其中的方法即可处理。而TwoPhaseCommitSinkFunction 提供了4个抽象方法。
1、beginTransaction() 开启事物
2、preCommit() 预提交事物
3、commit() 提交事物
4、abort() 失败回滚事物
我们可以讨论一个简单的列子,将最后sink operator的数据输出到文件中。这样我们需要实现已上的4个方法。
1、beginTransaction
首先开启事物,然后在我们目标输出系统上建立一个临时的文件temp-A,然后我们将输出的数据写入到这个临时文件temp-A中。
2、preCommit
在 pre-commit 中,我们将刷新temp-A并且关闭对temp-A的写入,我们可以开启一个新的事物,为后写入后面checkpoint的数据。
3、commit
在commint阶段,系统自动的将temp-A移动到最终存放数据的的文件夹中形成destination-A,请注意这个的操作增加了数据输出的延迟。
4、abort
我们将删除temp-A文件,然后回滚到上一个checkpoint,重新执行。
这里引入两阶段提交,但是又引入了两阶段提交的问题。当preCommit了,但是在commit阶段 Flink 系统宕机失败,或者是转移文件的时候失败。总之就是preCommit成功了,commit阶段失败,此时FLink将不会走abort 而是重新commit,直到commit 成功。关于回滚简单总结:
1、在preCommit之前失败,将abort删除临时文件,然后回滚到上一个checkpoint出重新执行。
2、在preCommit成功之后,任务将状态调至preCommit成功,然后继续执行。这里就有可能带来重复执行问题,所有需要做好幂等操作。这也是二阶段提交的问题所在。
总结:
1、ABS算法实现Exactly once执行语义,使用了Barrier对齐,此种做法的好处是带来了Exactly once语义,但是坏处也很明显,对齐需要同步阻塞它影响了吞吐量,在网络差系统性能不好的时候会极其严重。
2、Exactly once 其实在Flinlk框架中,很长一段时间内,只是针对框架内实现了语义,但是在end-to-end 却没有实现。Apache Flink 1.4.0 引入了二阶段事物提交,对实现整体Exactly once 提供了可能。
最后,我举的列子
Flink实时处理一个用户使用APP的次数,最后将数据直接输出到Redis。
出现的两种情况,TwoPhaseCommitSinkFunction能解决吗?
为了方便再贴一下:
1、当数据输出到redis,但是在给返回的时候超时,这个时候Flink回滚到最近的checkpoint,最近的Barrier处,再重新计算,但是此时数据已经输出到了redis,该怎么办。
2、如图中“d”,print1 输出成功,但是print2再输出到redis 的时候失败,这个时候Flink回滚到最近的checkpoint,然而print1的数据已经输出了redis,此时又该怎么办。
欢迎关注公众号讨论。
https://data-artisans.com/blog/end-to-end-exactly-once-processing-apache-flink-apache-kafka
好了,算法已经讲完,你是否有兴趣去看看原文呢。
欢迎关注公众号“眠三沐”
回复“ABS”获取
