《DAX圣经》第六章:DAX实例
------PowerBI非官方 简体精简笔记
计算比率与百分比
百分比:用一种度量的部分值去除以同一度量的总值。
第一种:销售占总销售额的百分比
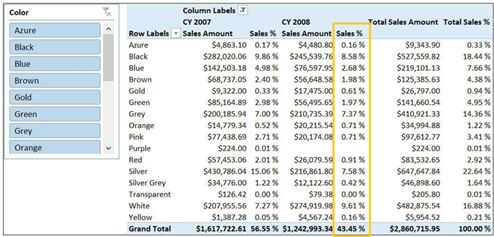
包含百分比的典型报告如图6-1所示,图6-1一个典型的百分比报告,包含销售额,显示的是绝对值和百分比。
在图6-1,显示的百分比是针对总值的百分比,即在当前列Year和行Color条件下对总计的百分比计值。表达这种度量的规范方法是使用DIVIDE将要计算的两个值分别作为分子分母:
[Sales %] := DIVIDE([Sales Amount],
CALCULATE( [Sales Amount],ALLSELECTED() ))
该公式包含需要计算的两个度量:一个是元度量[Sales Amount](作为分子),一个是通过元度量加上ALLSELECTED()条件(受透视表行、列、筛选器影响)的分母度量。分母处,由CALCULATE配合ALLSELECTED函数创建了一个新列表模型,维护了所有原始筛选(切片器和筛选器以及在透视表中的任何筛选器)。
第二种:有时,不仅仅是计算销售占总销售额的百分比。
可能希望颜色列显示在每个年份总数中所占的百分比,以便生成如图6-2所示的报告。图6-2 在本报告中,所显示的百分比是相对于年份的总数,而不是总计。
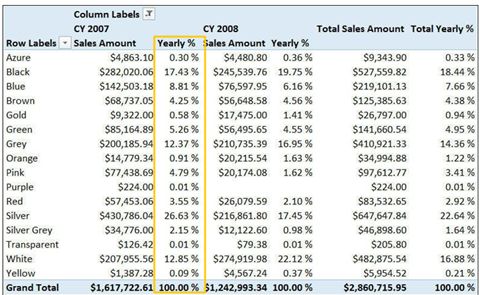
这时候需要的分母度量是:计算每年的总计。跟上一个公式不同的是,只需要改变分母度量的列表筛选,以便能包含对应的每一年,都包含当前可见的产品计算。我们可以通过添加Values函数轻松地完成这一任务:
VALUES函数返回当前在列表筛选中可见的所有唯一值的列值:
[Yearly %] := DIVIDE([SalesAmount],
CALCULATE([Sales Amount],ALLSELECTED(), VALUES(Date[CalendarYear] )))
值得注意的是,整个CALCULATE([SalesAmount],ALLSELECTED()),就是前面公式的分母,其实就是一个度量值列表。我们只是在该度量的基础上,加了一个VALUES ( Date[CalendarYear]列表筛选条件而已。其实际是一个简洁版的CALCULATE(度量+筛选),因为与上一个公式只是分母不同。可将分母定义成度量的简写公式:
[Sales %01]=[Sales Amount] (ALLSELECTED())
则前面的公式也可简写为:
[Yearly %]:=DIVIDE([Sales Amount],
[Sales %01] ( VALUES( Date[CalendarYear] )//度量+筛选。
当CaⅠcuⅠate的第一参数引用己存在的某个度量时,可以省略CaⅠcuⅠate。
通过VALUES()筛选后,返回正确的结果。唯一的例外是列的总计:本例中的每一行,VALUES()的结果返回了两个可见的年份(2007与2008)。到目前,我们使用了两种模式来计算百分比的分母:(1)使用ALLSELECTED(),还原原始筛选器筛选;(2) 重新在被还原的原始筛选中定义任何新的筛选器(例如,限于当前年份等)。
第三种:也可以应用反向筛选模式。
也就是说,可以直接从原关系列表模型开始,而不是使用原始筛选器,然后重新应用筛选,结果也将相同。例如,再现图6 - 1中的报告,可以恢复在[Color]以及[CalendarYear]列上的筛选,而不会影响其他筛选,针对需要维护的列分别使用ALLSELECTED如:
[Yearly %] :=DIVIDE([Sales Amount],
CALCULATE([Sales Amount],
ALLSELECTED( Product[Color] ),
ALLSELECTED( Date[CalendarYear] )))
还可以使用以下代码获得图6-2的度量,这将只从[Color]中删除筛选器,保持该列的筛选器不受影响:
[Yearly %-2] := DIVIDE ([SalesAmount],
CALCULATE([SalesAmount],ALLSELECTED (Product[Color] )))
这些度量作为示例显示在透视表时,它们都返回相同的值。但是,它们之间有很大的差别。事实上,这个[Yearly %]的后一版本恢复了Color上的原始筛选器,但是保留了任何其他位置的筛选器。如果筛选的列只有年份,则结果是相同的,但是,一旦通过日历表中添加更多筛选器列表时,则两个度量返回不同的值,如图6-3所示:
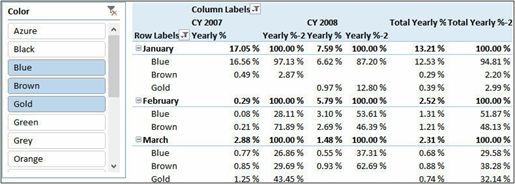
图6-3如果向透视表添加更多筛选器列表,两种度量将返回不同的值。
正如所看到的,Yearly%返回相对于当年的销售百分比,而Yearly%-2则返回相对于月份的销售百分比,这是因为我们将月份添加到透视表中。但这并不表示这两个计算一个正确一个错误,它取决于希望计算的数值。
这里需要记住的重要一点是:
每当计算百分比时,需要非常清楚分母是什么,以及当用户向透视表或报表添加的更多筛选器是什么。
计算累计总数
另一种使用频率较高的模式,可能是累积总数模式。每当有一组事务处理,并且我们有兴趣在某个序列(通常是时间)上累积它们的值时,都会讨论累积总计。例如:
(1)计算一个产品在所有时间内的总销售额,以此作为累计总额;
(2)计算一段时间内不同客户的总数,来作为累计值等。
让我们从分析一个简单的透视表开始,该透视表显示了一段时间内销售的产品数量。可以在图6 - 4中看到它:
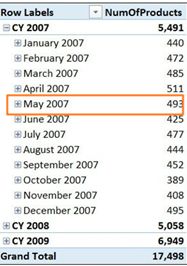
图6-4这个透视表显示了每年和每个月销售的产品总数。度量非常简单:
[NumOfProducts] := SUM( Sales[Quantity] )
我们知道:此度量值计算Sales中的Quantity列数量之和。它是一个元度量(即在整个数据模型下计算)。因为时期表与销售表具有一对多的关系,如果选取May 2007的值,它将筛选销售表,得到May 2007的销售额。这很容易。
关键是,如果要计算May 2007的累积总数,我们需要一个新的列表筛选条件:即筛选2007年底之前的所有期间(用于累计),而不是仅筛选May 2007。 这句话虽然很简单,但却隐藏了较大的复杂性。将条件分解一下:
(1)确定当前日期的结束时期,如表示2007年底的示例;
(2) 使用该值,创建一个筛选器,并显示2007年底之前的所有日期。
隐藏的复杂性在于:
(1)新的列表筛选基于当前的列表筛选;
(2)新的列表筛选必须大于原始筛选,因为它将包含2007及更早的所有日期。
图6-5中,可以看到需要检索的日期集,以便计算销售产品的累积数量:
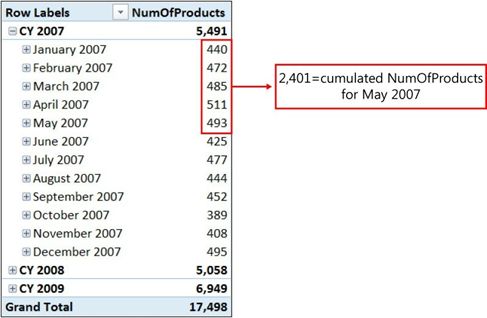
图6-5所售产品的累计数量需要考虑到当前产品在结束前的所有日期。
考虑到算法,现在是研究解决方案公式的时候了:
[CumulativeProducts]:=
CALCULATE(SUM(Sales[Quantity]),
FILTER(ALL('Date'),
'Date'[Datekey]<=MAX('Date'[Datekey])))
这是一个标准的列表关系+筛选+条件的DAX公式,很容易解释该公式:该度量由CALCULATE构建的列表数据模型是:
(1)SUM ( Sales[Quantity]计算列表 + ALL('Date' ) 列表 + 'Date'[Datekey]<=MAX('Date'[Datekey])(条件列表),后两个列表构成新的筛选列表(通过时期关系列表),筛选出计算列表计算。如下简易关系图:
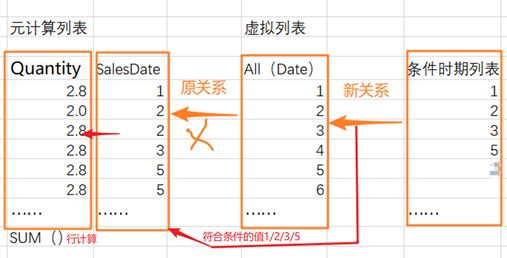
(2)这里关键是要理解条件:'Date'[Datekey]<=MAX ('Date'[Datekey])。回忆一下MAX的确切含义“当前筛选列表DateKey列的最大值”。
一方面,因为表达式是计算筛选的一部分,所以它仍然回到原始列表筛选中工作。例如,如果筛选May 2007,那么,对应的最大日期是2007年的最后一天;
另一方面,左边表达式Date[DateKey] 是一个列,意思是“当前行筛选下的DateKey中的列值”,该列值再构成由FILTER创建的“当前列表筛选”。因此,该表达式表示为:“筛选所有低于或等于(<=)May 2007最后一天的日期。这正是我们需要的条件。你可以在图6-6中看到实际的公式计算的结果:
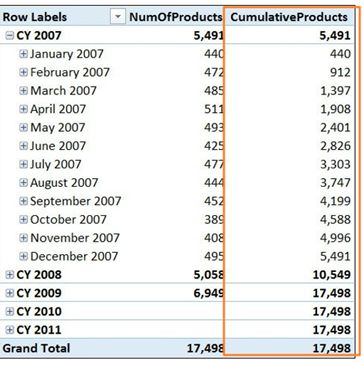
图6-6 CumulativeProducts将值加到当前日期。
还有一个问题是,这个公式。实际上显示了2010年及以后的数据,而数据库中并没有2010的数据。而且未来所有时期的数据都将会显示。这种行为是正确的,因为我们计算的就是:今后销售的产品的累计数量=迄今为止销售的总数。尽管如此,你可能不想显示这些数字(这种业务场景是常见的)。这可以通过用空白替换不需要的行来删除它们:
(1)通过透视表表默认隐式所有值为空的行(同样也适用于列);
(2)要隐藏不需要的行,可使用IF函数检查当前筛选中是否存在Sales销售,如下代码所示。
[CumulativeProducts] :=IF(COUNTROWS( Sales ) >0,
CALCULATE ( SUM( Sales[Quantity] ),
FILTER(ALL( 'Date' ),
'Date'[Datekey] <=MAX( 'Date'[Datekey]))))
该度量中,我们基于这样一个事实:即IF的Else分支如果缺失,将返回一个空白。
计算每天与工作日的销售额
另一个常用的业务场景是如何在工作日内执行计算的例子。这是相对于时间智能计算来说的一个简单的场景。
如图6-7所示。希望生成一个报告:
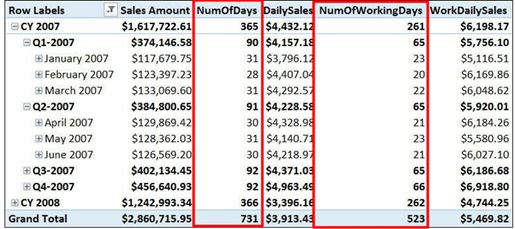
图6-7在这个透视表中,可以看到销售额分别除以天数以及工作日天数。
所显示的数字分别包含不同的含义:
(1) [endif]Sales Amount--销售是该期间的总销售额;
(2) [endif]DailySales-- 每日销售是每天的平均销售。
WorkDailySales是按工作日销售的平均销售,以及它与非工作日销售的比例,以预计这些工作日会不会产生盈利。这些度量的定义如下:
[NumOfDays] := COUNTROWS(Date)
[NumOfWorkingDays] :=CALCULATE( [NumOfDays], Date[WorkingDay] ="WorkDay")
[Sales Amount] :=SUMX( Sales, Sales[Quantity] * Sales[Unit Price] )
[DailySales] : =DIVIDE( [Sales Amount], [NumOfDays] )
[WorkDailySales] :=DIVIDE( [SalesAmount], [NumOfWorkingDays]) --工作日天数销售占比
这些度量很简单,但包含了一些我们必须解决的问题。事实上,在前一张图表中,我们只筛 选了两年:2007和2008。这些数字符合计算。为更清楚地显示出多个年份,我们移除筛选器。如图6-13所示。
图6-13这个透视表的总计显示了错误的值。
如果查看DailySales和WorkDailySales的总计,会立即发现数字是错误的。并不是行中显示的值的平均值。该问题应该很容易理解:因为在透视表中显示的是正常天数和工作天数。按总计计算时,计算的是没有销售的期间,而且由于天数位于分母,因而最终值低于预期。我们先不看最后正确的公式,展示几个错误解决方案对问题的影响。
因为这两项措施都有相同的问题,所以让集中讨论DailySales,公式正确后,同时会适用于NumOfWorkingDays度量。
第一次试验:
你可能想到:清除掉那些没有销售的天数(即反利用条件,该情况在实际中经常出现,但这里只是提起该概念,该示例里是假反利用条件),这很容易,可以为NumOfDays尝试IF处理: [NumOfDays] := IF([Sales Amount] >0,COUNTROWS(Date))
此更新公式使得没有销售的行从其中消失,看起来好了一些。但它不会修正总计行。因此,这不仅是错误的,也具有很大的误导性,而且使问题不容易发现,如图6-8所示。
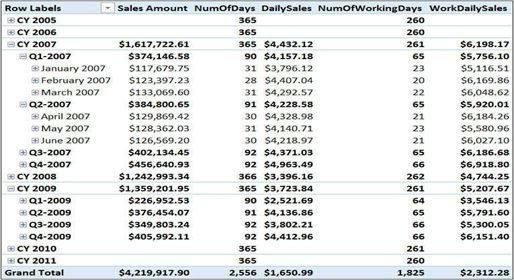
图6-8 没有销售的期间行消失了,但总计仍然是错误的,
正如所看到的,总计仍然是错误的,即使没有销售的所有行都从透视表中消失了。是的,它 们消失了:
(1)一方面,将NumOfDays设置为Blank,透视表将不显示这些行;
(2)另一方面,在总计销售额中,因为销售额大于零,所以我们的公式仍然考虑了所有的日期。
结论是:第一次实验显然走错了方向。
这一度量存在一个明显的问题:我们称之为“粒度不匹配”。如果仔细看结果,在月和年两个时期粒度上都是正确的,只是在总计上是错误的。原因是:有多个年份并没有销售,这些没有销售的年份是不需要计算的。因此,我们说,在年份粒度时,数字是正确的,而在总体粒度上数字是错误的。
所以,需要解决的问题是:
(1) 需要以正确的粒度计算公式;
(2) 然后将结果合并为单个值;
(3) 并能在更高的粒度上计算这种度量。
这就产生了一个问题:这个正确的粒度是什么?
第二次试验:
需要的时期粒度在年,月,日上都有可能,这取决于实际需要,虽然我们已发现总计的错误,但我们仍然对年度值感到满意,因此,可以使用以下新公式将粒度设置在年份级别:
[DailySales] :=DIVIDE([Sales Amount],
SUMX(VALUES('Date'[Calendar Year] ),
IF([Sales Amount] >0, [NumOfDays])))
该公式定义的分母检查在特定年份是否有销售。如果存在,则IF函数返回存在的天数,否则,返回一个空白,并且不会影响分母的总数。值得记住的是:公式里包含的分子分母的两种度量--Sales Amoun和NumOfDays都会正常,因为存在DAX自动隐式存在的CALCULATE。如果没有这种CALCULATE,公式就不能正确工作。
两个隐式行筛选:
(1)[Sales Amount]度量值列表隐式行筛选,即CALCULATE(SUM([Sales Amount])); (2)SUMX,迭代函数自带的隐式行筛选;
在图6-9中,可以看到结果现在是正确的,即使在总计上也是如此:
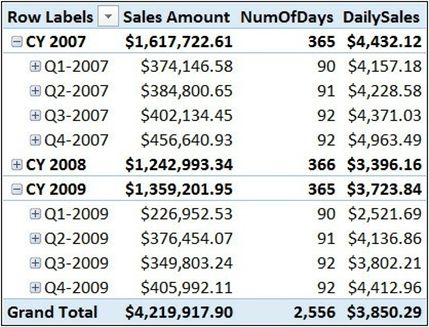
图6-9添加了多年份的迭代计算,并固定了总计。实际上,在用于这些测试的数据库中,所有这些年都有记录数据,这意味着从1月1日到12月31日都存在数据记录。
但在实际需求中,你可能希望生成在几年内的不完全填充数据的报告。例如:在生成8月份报告时,只有到8月为止的那些数据,而没有8月以后并没有的那些月的信息。
本例中,该度量仍将报告不正确的数字。因此,这项度量尚未最后确定。图6-10中,我们希望删除掉2009年8月8之后(没有)的销售:
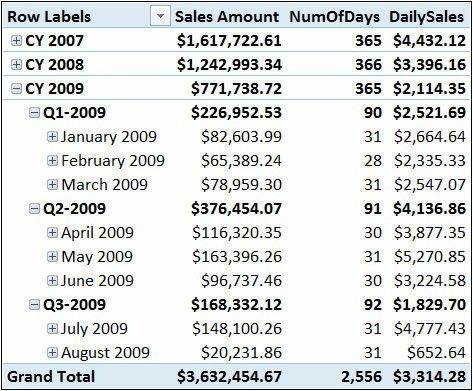
图6-10当一年没有完成时,度量仍然报告不正确的结果,
可以看到,8月是最后一个月(顺便说一句,它是不完整的),所有高于它的总数(即季度、年份和总计)都报告了错误的数字。当然这种行为是我们(有意)在代码中使用了错误的粒度,因为正确的粒度不是年份,而是月份。我们使用这个年度粒度,是因为在年度水平上度量似乎是正确的。
但是,即使我们确定了总计的公式,在年的粒度级一旦该年度里的某几个月一消失,就会遇到同样的问题。既然问题在于粒度筛选不对,那么。我们有了:
第三次试验:
也就是,正确的度量表述式需要同时考虑到年份和月份,如:
[DailySales] :=DIVIDE([Sales Amount],
SUMX(VALUES( Date[Calendar Year] ),
SUMX(VALUES( Date[Month] ),
IF([Sales Amount] >0, [NumOfDays]))))
现在,分母在年份和月份上执行两个迭代,它分别检查每对(年份、月份组合)是否存在该月份的销售额,并正确地聚合出当前存在销售的月份的天数。图6-11中结果:
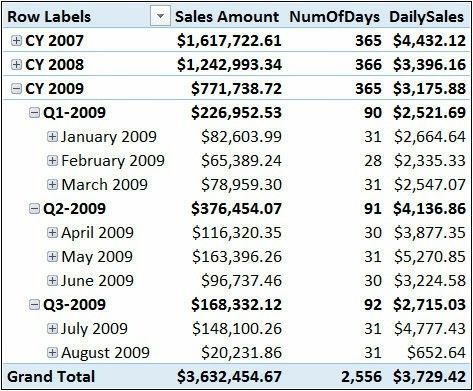
图6-11一旦正确设置了粒度后,公式就会报告正确的数字。
第四次试验:
使用CROSSJOIN表达式,可以更优雅一些:
[DailySales] :=DIVIDE([Sales Amount],
SUMX(CROSSJOIN(
VALUES( Date[Calendar Year] ), VALUES( Date[Month] )),
IF([SalesAmount] >0, [NumOfDays])))
注意:粒度不匹配问题经常出现在多个模型设计(业务场景)中。
如果某些度量只能在定义的粒度上计算,则需要迭代定义该粒度的列,最后聚合该粒度部分的结果。建议详细研究这个示例,因为它将在多个数据模型中有用。
值得注意的是,在最近(最后)那个月里仍有一个小问题:NumOfDays的天数结果并没有考虑到最后一个月可能不完整的情况。例如,如果在8月15日提交了一份报告,就不应该考虑到其未来的日子,因为这时候的销售显然是不存在的。如果还希望在最后一个月也产生此正确的结果,需要进一步限制日期表,方法是在前面公式的后面加上一个筛选条件:删除最后一次销售之后的所有日期。
最后正确的度量:
[DailySalesCorrected]:=
CALCULATE(DIVIDE([Sales Amount],
SUMX(
CROSSJOIN(VALUES( Date[Calendar Year] ),VALUES( Date[Month] )),
IF( [Sales Amount] >0, [NumOfDays] ))), FILTER('Date', 'Date'[Date] <=MAX(Sales[OrderDate] ) ))
计算工作日差异
接下来是是一个非常简单单却非常有用的例子,因为它阐述了一种使用DAX计算值的方式,这在其他分析引擎中并不常见(比如Analysis Services多维引擎)。
考虑在事实表中,对于每个订单,有两个这样的日期:
(1)OrderDate是下订单的日期;(订货时期)
(2)ShipDate 是订单发运的日期(发货时期)
业务场景:计算处理订单业务所需的天数。
这很容易做到,这要归功于DAX存储日期的方式。实际上,执行一个简单的减法即可:ShipDate-OrderDate就足够能计算天数了。话虽如此,一些更有实际有用的数值计算是:
(1)两个日期之间的业务日天数:
(2)排除假日期间的工作:
(3)非公司工作时的工作日天数(比如加班天数)等。
本例,使用工作日而不是非工作日来计算处理订单的时期要公平得多。
事实证明,这比简单的减法更具挑战性。与前面的示例一样,日历表包含一个列,该列定义出特定的日期:是否为工作日。我们需要找到一种方法来使用该列,以计算这两个日期之间的差异(以工作日表示)。
在数据模型中,Calendar表用于按订单日期、年份等对订单进行切片。日历和事实表之间的关系基于订单日期。为了解决这种情况,需要停止将Calendar表视为维度(只用于筛选数据表),并认为Calendar表只是一个表。使用它以不同的方式计数,而不是仅仅是维度筛选等。
例如,可以在OrderDate和ShipDate之间计算Calendar表中的行数,这些行同时也是工作日。如果以这种方式表示该算法,它将非常快地通过DAX定义出计算列:
Sales[WorkinDaysHandling] = COUNTROWS(
FILTER(Date,
AND( AND(Date[Date] >= Sales[OrderDate],Date[Date] <= Sales[ShipDate]),
Date[Working Day] ="WorkDay"))) --并接第一个AND
相同算法的一种更优雅的度量方式如下:
Sales[WorkinDaysHandling] =
CALCULATE(COUNTROWS ( Date ),
ALL(Date),
DATESBETWEEN( Date[Date], Sales[OrderDate],Sales[ShipDate]),
Date[WorkingDay] ="WorkDay")
后一个公式使用了DATESBETWEEN函数构建时期筛选:即订货时期与发货时期之间的所有日期,结果是一个表,然后使用它作为筛选器参数来筛选计算,以更改现有的WorkDay选择。
计算静态移动平均值
移动平均线是另一个常见的模式。本例提供一个如何以静态方式计算移动平均值的示例。例如,使用包含某些股票价格的股票数据模型,想要计算过去50至200个期间的平均价格。因为在股票市场上,一种常见的交易技巧是:观察移动速度较快的平均线(超过50个周期)何时穿过移动到较慢的平均线(200个时段),以确定买入和卖出点。
此示例还要求,由于数据库中的节假日和遗漏日(如未确定股票价格的天数等),50个时间段与固定天数不相对应。这就需要考虑数据库中的遗漏日,并始终确保平均50个点的股票覆盖有一个定义的价格。
本示例使用的数据模型非常简单,仅包含一个日历表和另一个包含股票收盘价的表,如图6 -12所示,其中没有1月6 - 7日两天的价格:
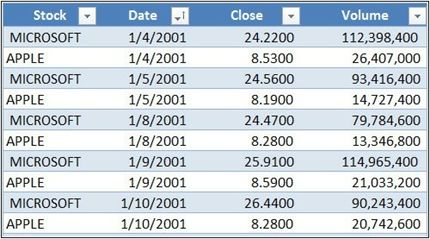
图6-12对于假期和其他非工作日,股票价格有几个遗漏。
为了计算平均值,可以添加计算列。
主要原因是想要在图表上显示这个平均值,这意味着DAX需要计算数百个值来绘制线条。由于计算这么多平均值的点可能是一个缓慢的操作,所以,可以将这些计算合并到计算列中,以便生成更快的图表。
这需要定义好移动平均值起始日期,这些日期可能因股票而异。我们来解决这个问题:
第一步:给表中的每一行分配一个数字。
这个数字随每个股票单而增加。因此,为第一个Microsoft的价格指定一个数字:1,数字2代表Microsoft的第二个价格,以此类推。对Apple等每个唯一值的行都执行同样的操作。结果可见于图6-19。
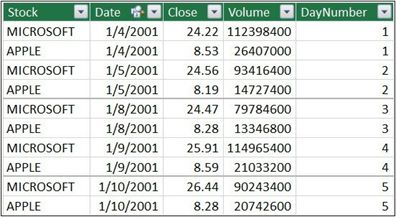
图6-13 DayNumber列是股票价格的频次数字。
该计数只需:对与当前行相同的每一行时期计数即可,使用EARLIER:
Prices[DayNumber] =
COUNTROWS(FILTER(Prices, // FILTER()表AND(Prices[Date] <=EARLIER( Prices[Date]),
Prices[Stock] =EARLIER( Prices[Stock] )))) // 同时满足的两个条件筛选
第二步:计算移动平均值。
既然每一行都有一个索引符,就很容易确定50或200个周期的边界:只需取当前DayNumber--天数,减去要考虑的期间数,然后取确定行的日期就足够了。
可以使用两种不同的技术来构建这个计算列。第一个方案更容易理解,即使代码不是最优的;第二个解决方案比较优雅一些,最大的优点是遵循了前面概述的非常简单的DAX计值算法规律:
Prices[MovingAverage200] =
CALCULATE ( AVERAGE(Prices[Close]),
FILTER(ALL(Prices[Date]),
AND(Prices[Date]>=LOOKUPVALUE(Prices[Date],Prices[Stock],EARLIER(Prices[Stock]),Prices[DayNumber],
EARLIER(Prices[DayNumber]) –200),
Prices[Date]<=EARLIER(Prices[Date]))),
ALLEXCEPT( Prices,Prices[Stock]))
该公式的核心是最内部的条件,它筛选当前的日期与DayNumber-200之间的日期。外部ALLEXCEPT需要将计算限制为同一股票的行。
该公式的第二个版本是一个更好的解决方案:
Prices[MovingAverage200]=
CALCULATE (
CALCULATE ( AVERAGE(Prices[Close]),
Prices[DayNumber]>=VALUES(Prices[DayNumber])- 200,Prices[DayNumber]<=VALUES(Prices[DayNumber])),
ALLEXCEPT( Prices,Prices[Stock],Prices[DayNumber]))
同样,定义出:Prices[MovingAverage50] 度量(200改为50即可)
这个移动平均值使用了两个嵌套CALCULATE。这里略过原内容,其实使用DAX的万能公式模式:关系+筛选+条件很好理解,如图:

事实上,第一个红框内:第二个CALCULATE定义的是一个度量值列表,两个条件筛选下的求平均值的度量,该度量做为第一个CALCULATE的第一个参数,然后再放置了一个关系列表筛选条件(它针对ALLEXCEPT()定义的其中两列与第二个CALCULATE()度量列表构成新关系的计算列集,参与计算)。
三个度量很容易定义出来:
[AVG 200] := AVERAGE( Prices[MovingAverage200] )
[AVG 50] := AVERAGE ( Prices[MovingAverage50] )
[AVG Close]:= AVERAGE ( Prices[Close] )
最后,使用度量来显示某个图表,该图表为每只股票指示移动平均线交点处的买卖点,如图6-20所示:
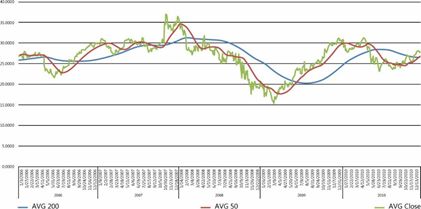
图6-20移动平均线是有用的,以显示一个股票的随着时间的推移方向。