一组Mongodb复制集,就是一组mongod进程,这些进程维护同一个数据集合。复制集提供了数据冗余和高等级的可靠性,这是生产部署的基础。
复制集的目的
前面说了,保证数据在生产部署时的冗余和可靠性,通过在不同的机器上保存副本来保证数据的不会因为单点损坏而丢失。能够随时应对数据丢失、机器损坏带来的风险,牛逼到不行。
换一句话来说,还能提高读取能力,用户的读取服务器和写入服务器在不同的地方,而且,由不同的服务器为不同的用户提供服务,提高整个系统的负载,简直就是云存储的翻版...
简单介绍
一组复制集就是一组mongod实例掌管同一个数据集,实例可以在不同的机器上面。实例中包含一个主导,接受客户端所有的写入操作,其他都是副本实例,从主服务器上获得数据并保持同步。
主服务器很重要,包含了所有的改变操作(写)的日志。但是副本服务器集群包含有所有的主服务器数据,因此当主服务器挂掉了,就会在副本服务器上重新选取一个成为主服务器。
每个复制集还有一个仲裁者,仲裁者不存储数据,只是负责通过心跳包来确认集群中集合的数量,并在主服务器选举的时候作为仲裁决定结果。
基本架构
一个包含3个mongod的复制集架构如下所示:
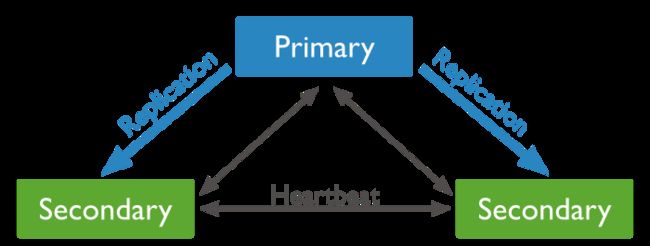
如果主服务器失效,会变成:

如果加上可选的仲裁者:
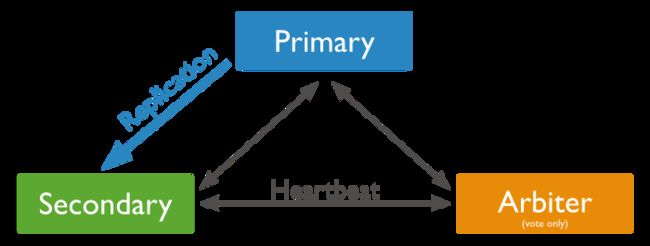
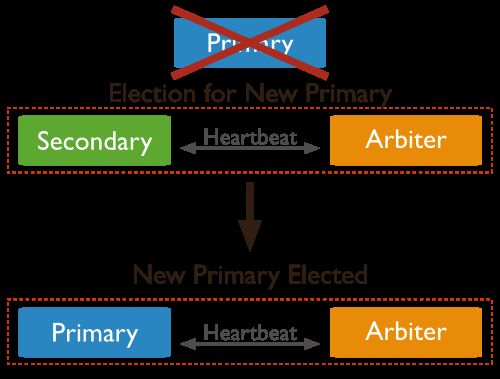
如果主服务器失效:
简单部署
下面简单部署一个含有3个实例的单机复制集测试。
建立三个节点目录。
mkdir /mtest
mkdir /mtest/node1
mkdir /mtest/node2
mkdir /mtest/node3
分别启动三个shell去运行mongod。当然也可以再一个shell上运行,通过在最后面加上 & 使其转入后台运行。
mongod --dbpath /mtest/node1 --port 10001 --nojournal --replSet test
mongod --dbpath /mtest/node1 --port 10002 --nojournal --replSet test
mongod --dbpath /mtest/node1 --port 10003 --nojournal --replSet test
这个时候还没有经过配置,连接mongod:
> rs.initiate({"_id" : "test","members" : [
... {"_id" : 1,"host" : "127.0.0.1:10001"},
... {"_id" : 2,"host" : "127.0.0.1:10002"},
... {"_id" : 3,"host" : "127.0.0.1:10003"},
... ]})
可以看到配置成功,查看状态
rs.status()
此时副本节点还无法读取数据,在副本节点设置可读:
rs.slaveOk()
其他命令可以参考官方文档:http://docs.mongodb.org/manual/reference/replication/
参考资料:
http://docs.mongodb.org/manual/administration/replica-set-deployment/
http://www.ttlsa.com/mongodb/mongodb-replica-set/
http://gong1208.iteye.com/blog/1558355
http://f.dataguru.cn/thread-171386-1-1.html
2、sharding
Mongodb的sharding是用来满足数据库系统负载均衡的,方式是分片。
分片就是指将数据拆分,分散到不同的服务器上,从而处理更大的负载,存储大数据。
当数据增大到一定程度时,查询数据会变的很慢,难以忍受的地步,严重影响用户体验。往往就会根据业务对大表大数据库进行分表分库操作。人为的按照某种协定好的策略将若干不同的数据存储到不同的数据库服务器上,应用程序管理不同服务器上的不同数据,每台服务器上的连接都是完全独立的。
这种分表分库可以很好的工作,弊端就是非常难以维护,调整数据分布和服务器负载,添加或减除节点非常困难,变一处而动全身。
mongodb支持自动分片,集群自动的切分数据,做负载均衡。避免上面的分片管理难度。mongodb分片是将集合切合成小块,分散到若干片里面,每个片负责所有数据的一部分。这些块对应用程序来说是透明的,不需要知道哪些数据分布到哪些片上,甚至不在乎是否有做过分片,应用程序连接mongos进程,mongos知道数据和片的对应关系,将客户端请求转发到正确的片上,如果请求有了响应,mongos将结果收集起来返回给客户端程序。
分片适用场景:
服务器磁盘不够用
单个mongod不能满足日益频繁写请求
将大量数据存放于内存中提高性能
建立分片需要三种角色:
- shard server
保存实际数据容器。每个shard可以是单个的mongod实例,也可以是复制集,即使片内又多台服务器,只能有一个主服务器,其他的保存相同数据的副本。为了实现每个shard内部的auto-failover,强烈建议为每个shard配置一组Replica Set。
2.config server
为了将一个特定的collection 存储在多个shard 中,需要为该collection 指定一个shardkey,shardkey 可以决定该条记录属于哪个chunk。Config Servers 就是用来存储:所有shard 节点的配置信息、每个chunk 的shardkey 范围、chunk 在各shard 的分布情况、该集群中所有DB 和collection 的sharding 配置信息。
- route server
集群前端路由,路由所有请求,然后将结果聚合。客户端由此接入,询问config server需要到哪些shard上查询或保存数据,再连接到相应的shard进行操作,最后将结果返回给客户端。客户端只需要将原先发送给mongod的请求原封不动的发给mongos(即route server)即可,不必知道数据分布在哪个shard上。
shard key:设置分片时,需要从集合中选一个键,作为数据拆分的依据,这个键就是shard key。
shard key的选择决定了插入操作在片之间的分布。
shard key保证足够的不一致性,数据才能更好的分布到多台服务器上。同时保持块在一个合理的规模是非常重要的,这样数据平衡和移动块不会消耗大量的资源。
sharding 快速配置
如前面介绍复制时一样,本节会在单台服务器上快速建立一个集群。首先,使用--nodb选项启动mongo shell:
$ mongo --nodb
使用ShardingTest类创建集群:
> cluster = new ShardingTest({"shards" : 3, "chunksize" : 1})
再打开一个shell用来连接到集群的mongos:
> db = (new Mongo("localhost:30999")).getDB("test")
插入一些输入:
> for (var i=0; i<100000; i++) {
... db.users.insert({"username" : "user"+i, "created_at" : new Date()});
... }
> db.users.count()
100000
运行sh.status()可以看到集群的状态:分片摘要信息、数据库摘要信息、集合摘要信息。
要对一个集合分片,首先要对这个集合的数据库启用分片,执行如下命令:
> sh.enableSharding("test")
现在就可以对test数据库内的集合进行分片了。
对集合分片时,要选择一个片键(shard key)。片键是集合的一个键,MongoDB根据这个键拆分数据。例如,如果选择基于"username"进行分片,MongoDB会根据不同的用户名进行分片:"a1-steak-sauce"到"defcon"位于第一片,"defcon1"到"howie1998"位于第二片,以此类推。选择片键可以认为是选择集合中数据的顺序。它与索引是个相似的概念:随着集合的不断增长,片键就会成为集合上最重要的索引。只有被索引过的键才能够作为片键。
在启用分片之前,先在希望作为片键的键上创建索引:
> db.users.ensureIndex({"username" : 1})
现在就可以依据"username"对集合分片了:
> sh.shardCollection("test.users", {"username" : 1})
使用explain来看数据属于哪个shard:
> db.users.find({username: "user12345"}}).explain()
参考资料:
http://www.ttlsa.com/mongodb/the-architecture-of-mongodb-mongodb-fragment-cluster-and-simple-construction-scheme/
Mongodb权威指南(第二版)