本文参考整理了Coursera上由NTU的林轩田讲授的《机器学习技法》课程的第二章的内容,主要介绍了Hard Margin SVM Dual的基本概念和求解方法、支撑向量的几何含义等,文中的图片都是截取自在线课程的讲义。
欢迎到我的博客跟踪最新的内容变化。
如果有任何错误或者建议,欢迎指出,感激不尽!
对偶问题的动机
原来的SVM如果要进行非线性变换,需要在转换后的Z空间(假设为d~维度)内进行linear SVM的求解,则在Z空间里的线性分类对应到原来的X空间可能就是一个non-linear的复杂边界。
问题:Z空间的QP问题有d+1个变量、N个约束。如果d非常大甚至无穷大,就很难甚至不可能求解。
目标:让SVM模型的求解不再依赖转换后的空间维度d~,以能够使用非常多的、非常复杂的特征转换。
将original问题转换为dual(对偶)问题,该问题与原问题等价即可。

基本工具: Lagrange Multipliers
将Lagrange Multipliers当做变量求解,SVM中的每一个条件都会对应一个Lagrange Multiplier,所以共有N个变量。
注意:在SVM的文献中通常把Lagrange Multipliers的λ叫做α。
出发点
将有约束优化问题转换为无约束的优化问题。
原始问题:

定义Lagrange Function:
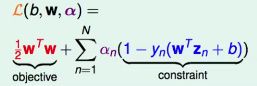
则原始问题等价于
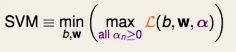
如何证明两个问题的解一样?
考虑两种情况:
- 如果某个(b,W)不满足原始问题的N个条件之一,即某个1-yn(W’Zn+b)>0,则内部的Max操作会将αn推向无穷大,在min操作中会被淘汰。
- 如果某个(b,W)满足原始问题的所有约束,则内部Max将所有的αi都推向0,即内部的max结果就是目标的1/2W’W的值,在外部的min操作中就会取得满足条件的(b,W)中目标函数最小的组合,和原始问题一样。
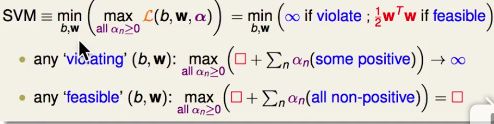
本质上就是把条件藏在了max操作里面,不满足条件的(b,W)一定不会被选择。
现在我们有了新的问题,它有哪些性质呢?
对于任何确定的α'【满足每一个元素α'n>=0】,则有
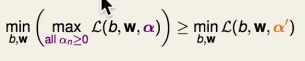
因为对于某一个(b,W),内部的max(L)始终大于等于L,则左边的最低点也一定大于等于右边的最低点。
简单地说,因为max>=any。
因为对于任何α'都有上式成立,所以

因为最大的是任意的α'中的某一个。
观察发现,只不过是把min和max操作交换了顺序,称该问题为Lagrange对偶问题。
只要我们解决了Lagrange Dual Problem,就得到了original problem的一个下限。
对偶性的强弱

- '>=':弱对偶性(weak duality)
- '=': 强对偶性(strong duality)
由最优化理论可得:
对于QP问题,如果满足:
- 原始问题是凸型的 convex primal
- 原始问题是有解的(如果Φ转换后数据点是线性可分的,则成立) feasible primal
- 线性约束条件
称为 '条件资格' (constraint qualification)。
则对偶问题是强对偶问题,即存在原始-对偶最优解(b,W,α)在两侧都能最优。
化简对偶问题
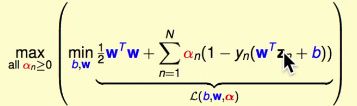
inner problem:里面的问题,即min操作,是没有条件约束的,因此在最优点上,满足:
因此,加上该条件的最优解不变。
加上该条件,可以把变量b消去。
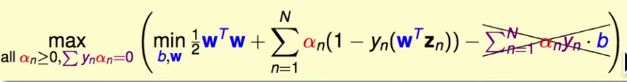

同理,对W进行类似的处理:

把最优解的条件加在对偶问题上:
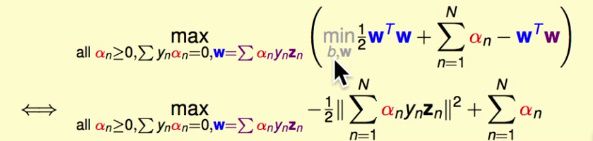
求解b和W
现在最佳化问题只有变量α了,其他变量b和W根据和α的关系被α所表示。
求得α后,再根据这些关系求出b和W。
这些关系,我们一般叫做KKT最优条件(KKT Optimality Conditions)
KKT是三个做最优化的研究者的名字首字母(Karush-Kuhn-Tucker)。
如果原始-对偶最优解(b,W,α):

其中第4个条件,一般称为互补松弛条件(complementary slackness)
以上的推导说明KKT条件是最优解的必要条件[necessary],但也可以证明对于我们的问题来说,它也是充分的[sufficient]。
因此我们可以利用KKT条件根据最优的α来求解(b,W)。
Standard Hard-Margin SVM dual

再做一些微小的改写:
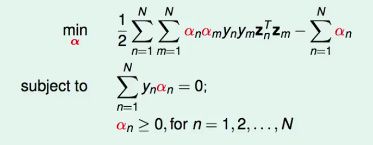
该问题称为“标准硬边界SVM的对偶问题”。
该问题仍然是一个QP凸问题,有N个变量(α1..N),N+1个条件(一个=0,N个>=0)。
仍然使用QP Solver求解。
QP系数

注意:很多QP程序可以很方便的直接特殊处理等式(A>=、A<=)或者边界类条件(an>=0),这样可以保证它们的数值稳定性
Q矩阵中的元素q(n,m)一般非0,是稠密矩阵(dense),且N大时,Q矩阵很大。
因此需要特殊的求解QP的程序(专门为SVM设计的),不存储整个Q矩阵,或者利用SVM的一些特殊条件来加速求解。
因此在实践中,我们通常最好使用特别为SVM设计的QP求解算法。
获得b和W
利用KKT条件:
得到W:
得到b:
和b有关的约束
只能告诉我们一个b的范围
如果某个αn>0 ==> (1 - yn(W’Zn + b)) = 0
两边都乘上yn,得
(yn - (W’Zn + b)) = 0
即
b = yn - W’Zn
上式告诉我们 yn(W’Zn + b) = 1,说明该点在胖胖的边界上,即是一个支撑向量(Support Vector)。
支撑向量的确切定义
我们把αn>0的点(Zn,yn)叫做support vectors,即支撑向量。
它一定在胖胖的边界上,但不是所有在胖胖的边界上的点都是SV,它们都是support vectors candidate。
即
SV的性质
计算W和b时,只需要用到支撑向量SV的点。
所以SVM是一种利用求解对偶问题的最优解,找出支撑向量来学习出最胖的分隔超平面的过程。
最胖分隔超平面的表示形式
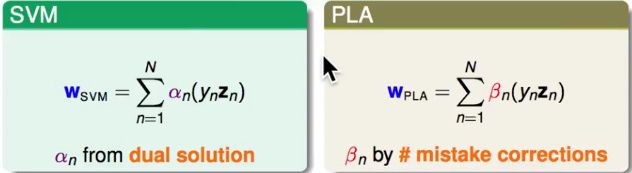
即W是ynZn的线性组合。
这对于当W0=0时,使用GD/SGD的LogReg或者LinReg也成立。
称作 W 能够被 数据点 所表示(represented)。
SVM: 只需要SV就可以线性表示出W。
PLA: 只需要犯错的点就可以线性表示W。
Hard-Margin SVM的两种形式

两者最终都是得到最优的假设函数:
我们真的做到脱离d~了吗?
其实没有,计算Q矩阵时,每个q(n,m)都需要计算Zn'Zm,这是一个在R(d)空间中的两个向量的内积,需要时间至少为O(d)。
因此我们要想办法避开计算转换后的高维空间中向量的内积。
这部分内容需要利用kernel function的威力,我们在下一讲进行探讨。
Mind Map Summary

有关Kernel SVM及更多机器学习算法相关的内容将在日后的几篇文章中分别给出,敬请关注!