前言
目前spark sql 主要应用在structure streaming、etl 和 machine learning 的场景上, 它能对结构化的数据进行存储和操作,结构化的数据可以来自HIve、JSON、Parquet、JDBC/ODBC等数据源。由于部门对数据的准确性,一致性和维护等等要求等业务特点,我们选择mysql使用jdbc的方式作为我们的数据源,spark 集群用yarn做为资源管理,本文主要分享我们在使用spark sql 过程中遇到的问题和一些常用的开发实践总结。
运行环境:spark :2.1.0,hadoop: hadoop-2.5.0-cdh5.3.2 (yarn 资源管理,hdfs),mysql:5.7 ,scala: 2.11, java:1.8
spark on yarn
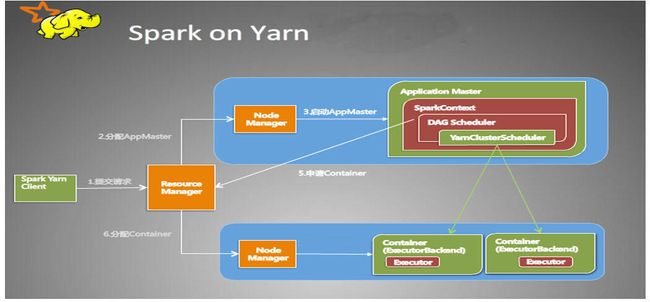
我们先来了解一下spark on yarn 任务的运行机制。yarn 的基本思想是将JobTracker的两个主要功能(资源管理和任务调度/监控)分离成单独的组件:RM 和 AM;新的资源管理器ResourceManager(RM)实现全局的所有应用的计算资源分配,应用控制器ApplicationMaster(AM)实现应用的调度和资源的协调;节点管理器NodeManager(NM)则是每台机器的代理,处理来自AM的命令,实现节点的监控与报告;容器 Container 封装了内存、CPU、磁盘、网络等资源,是资源隔离的基础,当AM向RM申请资源时,RM为AM返回的资源便是以Container表示,如上图,spark master分配的 executor 的执行环境便是containner。目前我们使用yarn 队列的方式,可以进一步的对应用执行进行管理,让我们的应用分组和任务分配更加清晰和方便管理。
开发实践
1. 读取mysql表数据
import com.test.spark.db.ConnectionInfos;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import java.util.Arrays;
public class SparkSimple01 {
public static void main(String[] args) {
// 创建spark会话,实质上是SQLContext和HiveContext的组合
SparkSession sparkSession = SparkSession.builder().master("local[*]").appName("Java Spark SQL basic example").getOrCreate();
// 设置日志级别,默认会打印DAG,TASK执行日志,设置为WARN之后可以只关注应用相关日志
sparkSession.sparkContext().setLogLevel("WARN");
// 分区方式读取mysql表数据
Dataset predicateSet = sparkSession.read().jdbc(ConnectionInfos.TEST_MYSQL_CONNECTION_URL, "people",
(String[]) Arrays.asList(" name = 'tom'", " name = 'sam' ").toArray(), ConnectionInfos.getTestUserAndPasswordProperties());
predicateSet.show();
}
}
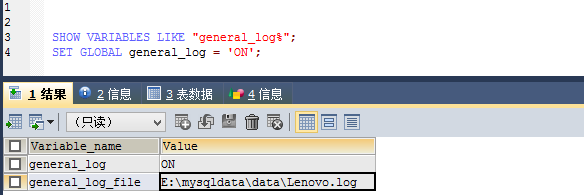
为了确认该查询对mysql发出的具体sql,我们先查看一下mysql执行sql日志,
#mysql 命令窗口执行以下命令打开日志记录
SHOW VARIABLES LIKE "general_log%";
SET GLOBAL general_log = 'ON';
打开Lenovo.log得到以上代码在mysql上的执行情况:
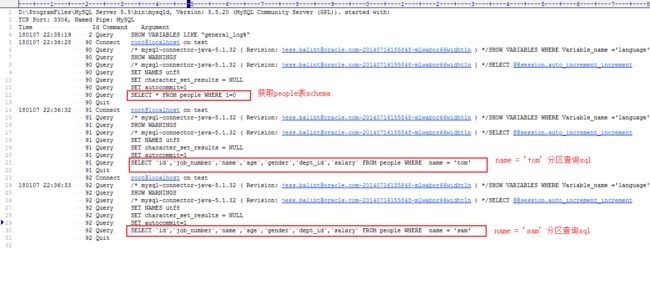
通过分区查询获取表数据的方式有以下几个优点:
- 利用表索引查询提高查询效率
- 自定义sql条件使分区数据更加均匀,方便后面的并行计算
- 分区并发读取可以通过控制并发控制对mysql的查询压力
- 可以读取大数据量的mysql表
spark jdbc 读取msyql表还有直接读取(无法读取大数据量表),指定字段分区读取(分区不够均匀)等方式,通过项目实践总结,以上的分区读取方式是我们目前认为对mysql最友好的方式。
分库分表的系统也可以利用这种方式读取各个表在内存中union所有spark view得到一张统一的内存表,在业务操作中将分库分表透明化。如果线上数据表数据量较大的时候,在union之前就需要将spark view通过指定字段的方式查询,避免on line ddl 在做变更时union表报错,因为可能存在部分表已经添加新字段,部分表还未加上新字段,而union要求所有表的表结构一致,导致报错。
2. Dataset 分区数据查看
我们都知道 Dataset 的分区是否均匀,对于结果集的并行处理效果有很重要的作用,spark Java版暂时无法查看partition分区中的数据分布,这里用java调用scala 版api方式查看,线上不推荐使用,因为这里的分区查看使用foreachPartition,多了一次action操作,并且打印出全部数据。
import org.apache.spark.sql.{Dataset, Row}
/**
* Created by lesly.lai on 2017/12/25.
*/
class SparkRddTaskInfo {
def getTask(dataSet: Dataset[Row]) {
val size = dataSet.rdd.partitions.length
println(s"==> partition size: $size " )
import scala.collection.Iterator
val showElements = (it: Iterator[Row]) => {
val ns = it.toSeq
import org.apache.spark.TaskContext
val pid = TaskContext.get.partitionId
println(s"[partition: $pid][size: ${ns.size}] ${ns.mkString(" ")}")
}
dataSet.foreachPartition(showElements)
}
}
还是用上面读取mysql数据的例子来演示调用,将predicateSet作为参数传入
new SparkRddTaskInfo().getTask(predicateSet);
控制台打印结果

通过分区数据,我们可以看到之前的predicate 方式得到的分区数就是predicate size 大小,并且按照我们想要的数据分区方式分布数据,这对于业务数据的批处理,executor的local cache,spark job执行参数调优都很有帮助,例如调整spark.executor.cores,spark.executor.memory,GC方式等等。
这里涉及java和Scala容器转换的问题,Scala和Java容器库有很多相似点,例如,他们都包含迭代器、可迭代结构、集合、 映射和序列。但是他们有一个重要的区别。Scala的容器库特别强调不可变性,因此提供了大量的新方法将一个容器变换成一个新的容器。
在Scala内部,这些转换是通过一系列“包装”对象完成的,这些对象会将相应的方法调用转发至底层的容器对象。所以容器不会在Java和Scala之间拷贝来拷贝去。一个值得注意的特性是,如果你将一个Java容器转换成其对应的Scala容器,然后再将其转换回同样的Java容器,最终得到的是一个和一开始完全相同的容器对象(这里的相同意味着这两个对象实际上是指向同一片内存区域的引用,容器转换过程中没有任何的拷贝发生)。
3. sql 自定义函数
自定义函数,可以简单方便的实现业务逻辑。
import com.tes.spark.db.ConnectionInfos;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.DataTypes;
public class SparkSimple02 {
public static void main(String[] args) {
SparkSession sparkSession = SparkSession.builder().master("local[*]").appName("Java Spark SQL basic example").getOrCreate();
sparkSession.sparkContext().setLogLevel("WARN");
Dataset originSet = sparkSession.read().jdbc(ConnectionInfos.TEST_MYSQL_CONNECTION_URL, "people", ConnectionInfos.getTestUserAndPasswordProperties());
originSet.cache().createOrReplaceTempView("people");
// action操作 打印原始结果集
originSet.show();
// 注册自定义函数
sparkSession.sqlContext().udf().register("genderUdf", gender -> {
if("M".equals(gender)){
return "男";
}else if("F".equals(gender)){
return "女";
}
return "未知";
}, DataTypes.StringType);
// 查询结果
Dataset peopleDs = sparkSession.sql("select job_number,name,age, genderUdf(gender) gender, dept_id, salary, create_time from people ");
// action操作 打印函数处理后结果集
peopleDs.show();
}
}
执行结果:
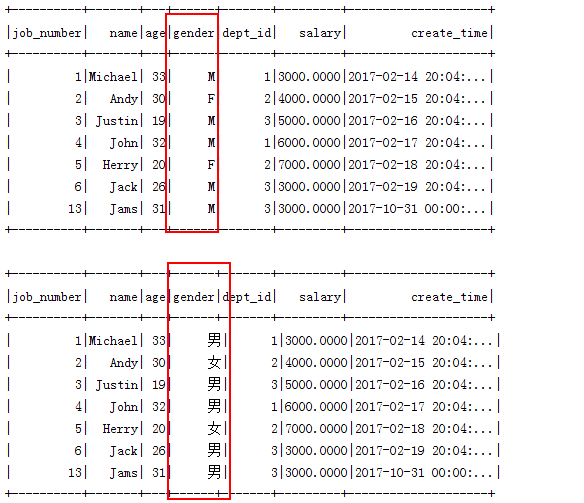
在sql中用使用java代码实现逻辑操作,这为sql的处理逻辑能力提升了好几个层次,将函数抽取成接口实现类可以方便的管理和维护这类自定义函数类。此外,spark也支持自定义内聚函数,窗口函数等等方式,相比传统开发实现的功能方式,使用spark sql开发效率可以明显提高。
4. mysql 查询连接复用
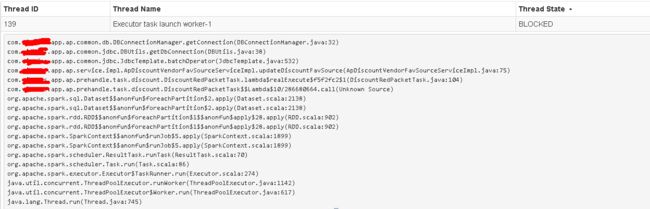
最近线上任务遇到一个获取mysql connection blocked的问题,从spark ui的executor thread dump 可以看到blocked的栈信息,如图:
查看代码发现DBConnectionManager 调用了 spark driver注册mysql driver 使用同步方式的代码
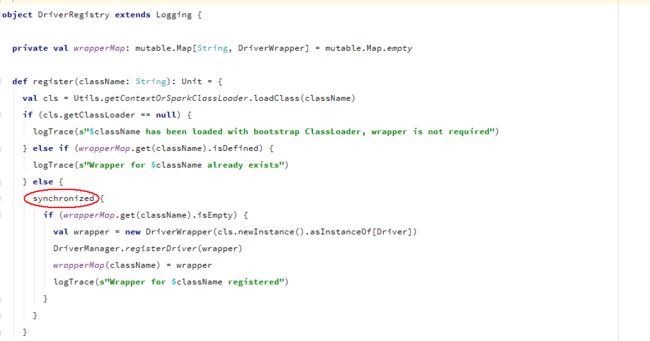
看到这里我们很容易觉得是注册driver 导致的blocked,其实再仔细看回报错栈信息,我们会发现,这里的getConnection是在dataset 的foreachpartition 中调用,并且是在每次db 操作时获取一次getConnection 操作,这意味着在该分区下有多次重复的在同步方法中注册driver获取连接的操作,看到这里线程blocked的原因就很明显了,这里我们的解决方式是:
a. 在同个partition中的connection 复用进行db操作
b. 为了避免partition数据分布不均导致连接active时间过长,加上定时释放连接再从连接池重新获取连接操作
通过以上的连接处理,解决了blocked问题,tps也达到了4w左右。
5. executor 并发控制
我们都知道,利用spark 集群分区并行能力,可以很容易实现较高的并发处理能力,如果是并发的批处理,那并行处理的能力可以更好,但是,mysql 在面对这么高的并发的时候,是有点吃不消的,因此我们需要适当降低spark 应用的并发和上下游系统和平相处。控制spark job并发可以通过很多参数配置组合、集群资源、yarn队列限制等方式实现,经过实践,我们选择以下参数实现:
#需要关闭动态内存分配,其他配置才生效
spark.dynamicAllocation.enabled = false
spark.executor.instances = 2
spark.executor.cores = 2
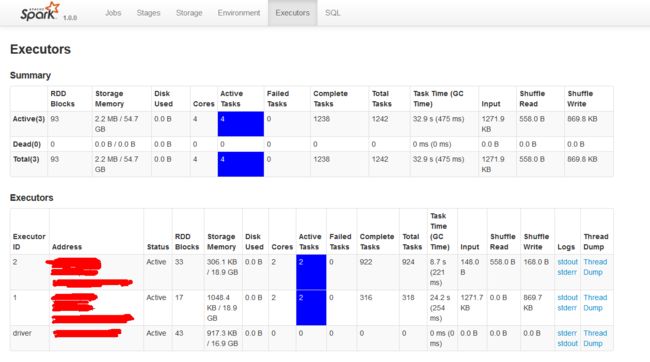
这里发现除了设置executor配置之外,还需要关闭spark的动态executor分配机制,spark 的ExecutorAllocationManager 是 一个根据工作负载动态分配和删除 executors 的管家, ExecutorAllocationManager 维持一个动态调整的目标executors数目, 并且定期同步到资源管理者,也就是 yarn ,启动的时候根据配置设置一个目标executors数目, spark 运行过程中会根据等待(pending)和正在运行(running)的tasks数目动态调整目标executors数目,因此需要关闭动态配置资源才能达到控制并发的效果。
除了executor是动态分配之外,Spark 1.6 之后引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域,我们先看看worker中的内存规划是怎样的:
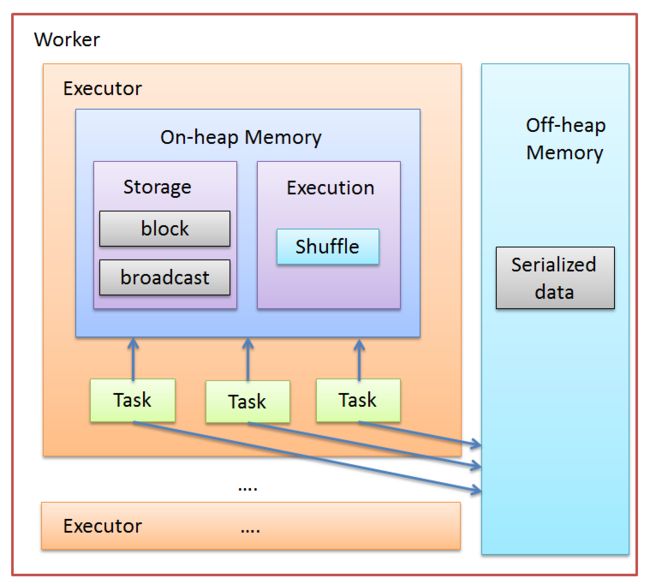
worker 可以根据实例配置,内存配置,cores配置动态生成executor数量,每一个executor为一个jvm进程,因此executor 的内存管理是建立在jvm的内存管理之上的。从本文第一张spark on yarn图片可以看到,yarn模式的 executor 是在yarn container 中运行,因此container的内存分配大小同样可以控制executor的数量。
RDD 的每个 Partition 经过处理后唯一对应一个 Block(BlockId 的格式为 rdd_RDD-ID_PARTITION-ID ),从上图可以看出,开发过程中常用的分区(partition)数据是以block的方式存储在堆内的storage内存区域的,还有为了减少网络io而做的broadcast数据也存储在storage区域;堆内的另一个区域内存则主要用于缓存rdd shuffle产生的中间数据;此外,worker 中的多个executor还共享同一个节点上的堆外内存,这部分内存主要存储经序列化后的二进制数据,使用的是系统的内存,可以减少不必要的开销以及频繁的GC扫描和回收。
为了更好的理解executor的内存分配,我们再来看一下executor各个内存块的参数设置:
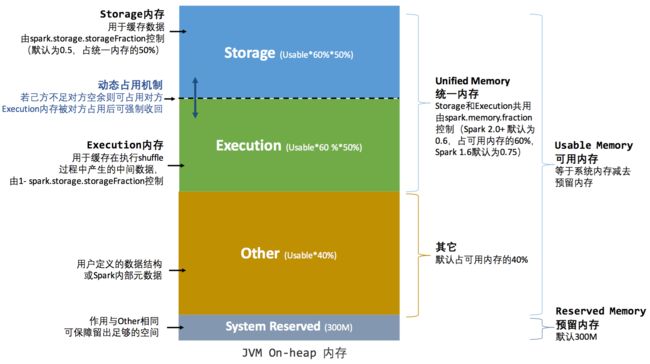
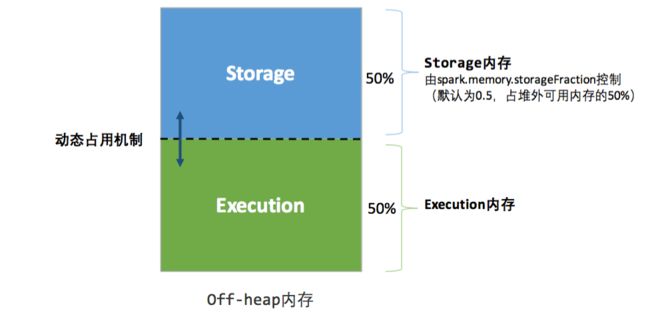
了解spark 内存管理的机制后,就可以根据mysql的处理能力来设置executor的并发处理能力,让我们的spark 应用处理能力收放自如。调整executor数量还有另外一个好处,就是集群资源规划,目前我们的集群队列是yarn fair 模式,

先看看yarn fair模式,举个例子,假设有两个用户A和B,他们分别拥有一个队列。当A启动一个job而B没有任务时,A会获得全部集群资源;当B启动一个job后,A的job会继续运行,当A的job执行完释放资源后,不过一会儿之后两个任务会各自获得一半的集群资源。如果此时B再启动第二个job并且其它job还在运行,则它将会和B的第一个job共享B这个队列的资源,也就是B的两个job会用于四分之一的集群资源,而A的job仍然用于集群一半的资源,结果就是资源最终在两个用户之间平等的共享。
在这种情况下,即使有多个队列执行任务,fair模式容易在资源空闲时占用其他队列资源,一旦占用时间过长,就会导致其他任务都卡住,这也是我们遇到的实际问题。如果我们在一开始能评估任务所用的资源,就可以在yarn队列的基础上指定应用的资源,例如executor的内存,cpu,实例个数,并行task数量等等参数来管理集群资源,这有点类似于yarn Capacity Scheduler 队列模式,但又比它有优势,因为spark 应用可以通过spark context的配置来动态的设置,不用在配置yarn 队列后重启集群,稍微灵活了一点。
除了以上提到的几点总结,我们还遇到很多其他的疑问和实践,例如,什么时候出现shuffle;如何比较好避开或者利用shuffle;Dataset 的cache操作会不会有性能问题,如何从spark ui中分析定位问题;spark 任务异常处理等等,暂时到这里,待续...
赖泽坤 @vip.fcs
参考资料:
http://www.cnblogs.com/yangsy0915/p/5118100.html
https://mp.weixin.qq.com/s/KhHy1mURJBiPMGqkl4-JEw
https://www.ibm.com/developerworks/cn/analytics/library/ba-cn-apache-spark-memory-management/index.html?ca=drs-&utm_source=tuicool&utm_medium=referral
https://docs.scala-lang.org/zh-cn/overviews/collections/conversions-between-java-and-scala-collections.html
https://www.jianshu.com/p/e7db5970e68c