By云端上的男人—DT大数据梦工厂
笔者学习Spark有一段时间,在这些个学习过程中,有酸甜苦辣可谓自己体会。接下来我会把我对与Spark的学习心得和大家共同分享一下。以便于大家少走一些弯路。而且在讲解Spark的时候,我会把一些关于Scala我认为比较重要的特性的东西都着重讲解一下,以便于大家对Scala这门语言有更加充分的了解.
在学习Spark之间,大家得先了解Spark是做什么的!关于Spark的详细的简介,大家可以在搜索网站上去查找。而笔者只会把自己所学习的,感受的架构的知识分享出来,可以让大家以更好的角度来看待Spark。
Spark是专为大规模数据处理而设计的快速通用的计算引擎。那么到底Spark是什么呢?笔者不会用太多的术语去解释Spark。笔者会用自己的方式来为大家阐释Spark是个什么东西。笔者会以模块的方式来讲解Spark的功能。然后以问题驱动的模型来把Spark相关的细节逐渐展露出来。
笔者所写的博客面对的人员是有scala基础以及对进程和线程有相关概念的人员和spark会基本使用的人员,如果大家有的对scala不是很熟悉的话,请大家观看家林老师的相关的scala教程链接:http://pan.baidu.com/s/1sljSvut密码:eea6.
Spark基础相关的链接链接:http://pan.baidu.com/s/1eSvKaFS密码:y95q
scala给我们提供了函数式编程的思维的方式,相信大家都知道,尤其是在map-reduce的应用中.所以,在我们的应用程序之中,我们通常会这样去应用我们的scala的集合,

相信大家对这个用法十分的熟悉,而且,我们要在这里考虑的问题是,这只是在一个进程中来运行的,这样的话,我们也知道,在单个进程中处理大量数据的能力肯定没有在多个进程中处理这么多数据的能力要强。那么,这就引入了我们的分布式处理框架Spark了(把大量数据分布在各个进程中去处理数据).
在了解Spark之前,我们需要知道一个知识点就是,默认情况下我们会把节点(Node)和物理机器做一对一的映射,也就是说,一个物理机器就是对应一个节点,一个节点就是对应一个物理机器.笔者阅读spark的版本是1.6.3的版本
首先,笔者认为最重要的讲解模块就是Spark的集群系统。Spark的集群系统如下图所示。笔者只会使用到Spark集群一种模式即:Standalonemode(不考虑高可用模式)。这种模式下,有一个(默认)Master和多个Worker组成的集群系统。
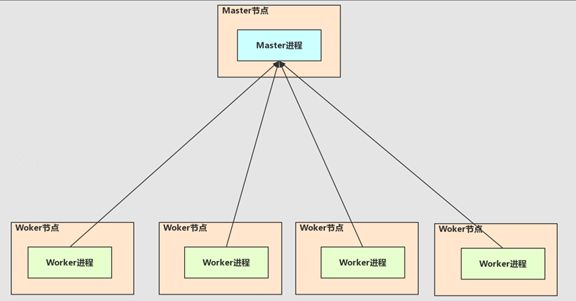
那么现在,我们就需要把Spark的集群结构说明一下(上图)。我们的Master节点中有一个Master进程,它主要的责任就是管理集群的资源(具体的资源也就是所有的Worker节点提交过来的CPU的核数和内存的大小的使用量)。至于为什么我们的Master进程要管理所有的Worker提交过来的CPU核数和内存的总量,那时因为我们的用户想要提交自己的程序去处理他本身的业务,但我们用户提交的程序需要这些资源。而且用户提交的程序称之为DriverProgram
接下来就是关于我们用户程序的提交的过程,为此,Spark给我们提供了两种提交的方式:一种是Client模式提交,一种则是Cluster模式提交。当然,这些设置都不是我们用户的事情,我们的用户只关注他自己的业务即可,这也是软件工程思路,所以,这些额外的一些提交方式的设置就需要委托给Spark提供的一些功能来完成,那么Spark集群提供的SparkSubmit进程就是专门来做这样的事情。关于为什么有两种提交的模式待会再谈。
说完了SparkSubmit,我们就要说一下Spark中Driver的概念,大家试想一下,我们的用户只关心自己的业务逻辑,而且我们的用户的也需要代码的简洁性,尽管我们用户获取到了资源,但是如何对这么资源的使用,用户也是不关心的,而且我们从模块化的思想来看,我们的Master进程管理好自己的资源的使用就是已经很不错了。那么我们的用户的业务处理就需要另一个角色来管理了,这个就是我们的Driver,这个Driver会向Master进程申请资源(CPU核数和内存),成功之后Driver就开始处理用户的业务逻辑代码
为什么Spark给我们提供了两种提交的模式?试想用户写出自己的业务逻辑代码是被提交了集群上,但是用户怎么能够实时的知道代码运行的状态消息?所以在我们把代码提交给集群的时候,我们有了Client和Cluster的两种提交的模式,在Client模式下我们的用户的代码的运行会在我们的命令终端上不断的去输出日志消息(一般在Client模式方式下,笔者是在Master节点上进行用户业务代码的提交),而且在这个时候,我们的Driver就运行在SparkSubmit进程之中(上文已经提到过)。那么,如果我们是以Cluster的方式进行提交的话,这里就有些麻烦了,我们的SparkSubmit进程会向Master进程通信以请求用户的代码作为一个进程运行到我们的Spark集群之上的某个Worker节点中。当把用户的代码提交成功能之后,我们的SparkSubmit进程就会结束自己的生命,而我们的Driver就会在某个Worker节点中来以DriverWrapper进程身份来处理用户的业务逻辑代码。这时的Driver在某个Worker节点中,我们就看不到我们的日志在控制台上的输出了,一般都会在我们的日志文件夹中存在。
Note:在Spark中还有一种Client模式是给用户提供了一种类似于Scala交互式接口。如图所示。

这种模式也是Driver在SparkSubmit进程之中,通过我们命令的输入然后把计算交给了集群来计算。思想类似,只是说多了一个可交互的接口。
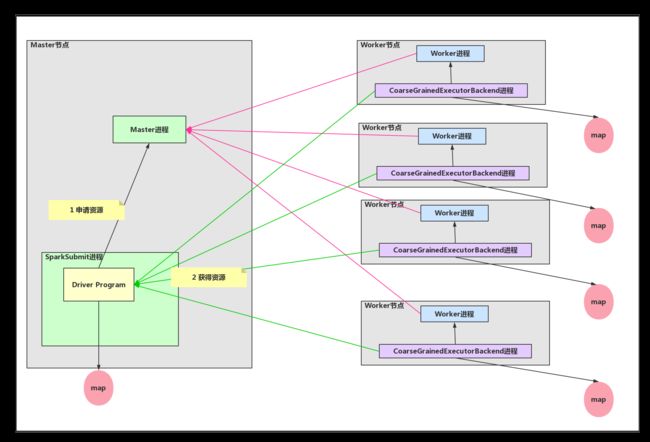
接下来,我们要把视角转到我们的Driver的业务逻辑处理这个过程中。由于考虑到下面消息接收的细节,笔者会把Driver说的再细一些,即我们的Driver大致分为了两个部分,一个是Driver是和Master进程通信以此来获得资源;另一是Driver是和CoarseGrainedExecutorBackend进程通信以此来管理自己获得的资源。我们的DriverProgram是以先入先出的方式(FIFO)来向集群进行提交作业,而且一旦Driver获得资源之后,默认情况下会最大化的使用集群中的资源(CPU和内存)。如果有其他的DriverProgram来提交的话就会等待上一个Driver运行完成。当我们的Driver向Master进程申请资源的时候,Driver会被注册到Master进程内存数据结构中,然后Master进程向Driver发送已经注册的消息。接下来Master进程就会发消息给每个Worker节点中的Worker进程,每个Worker进程会接受消息去启动一个CoarseGrainedExecutorBackend进程(已经获得最大化的CPU和内存资源)。紧接着Worker进程会向Master进程发送消息,Master进程接收到消息之后就会向Driver发送资源更新的消息。因为Worker启动CoarseGrainedExecutorBackend进程需要时间,所以CoarseGrainedExecutorBackend进程启动后也会向Driver发送计算资源注册的消息。所有在DriverProgram中要用到操作数据处理的指令都会以消息方式发送给CoarseGrainedExecutorBackend进程,然后CoarseGrainedExecutorBackend进程执行对数据的操作。如下图所示。比如用户的Driver程序中的map算子、filter算子等都会在CoarseGrainedExecutorBackend进程中来执行。(图中的假设是每个CoarseGrainedExecutorBackend进程都有Driver要求的数据,所以每个CoarseGrainedExecutorBackend都可以处理map算子操作)
接下来,我们就要考虑一下我们的数据模型了,如何在分布式集群中表示我们的数据,这就需要构建数据模型,毕竟是在多个进程中来计算我们的数据。在单进程中的时候,我们的集合可以是List或者其他类型的集合或者容器。但是在分布式中呢?我们的Spark开发者们设计了RDD这样的一个集合。
A Resilient Distributed Dataset (RDD)
在这样的一个集合中,我们从直观上可以了解到,这样的集合是管理多个进程中的数据。而且对于这个集合的每个算子的操作也都是会应用到各个进程的集合之中。

从上面的两句代码,大家只需要了解的是,我们RDD中的数据都会在我们的CoarseGrainedExecutorBackend进程中来计算.而collect的方法就是把计算的结果拿到我们的Driver中的意思.