前言:
数据结构是计算机相关专业的基础课程,不管学什么编程语言,都要学习数据结构。接下来就一起来了解一下吧。
一、概述
数据结构是研究数据如何在计算机中进行高效的组织和存储的一门学科。数据结构有逻辑结构和存储结构之分,逻辑结构描述的是数据与数据之间的关系,主要分为以下几种:
- 线性结构:数据与数据之间是一对一的关系。主要有数组、栈、队列、链表、哈希表等。
- 树形结构:数据与数据之间是一对多的关系。主要有二叉树、二分搜索树、AVL、红黑树、堆、线段树、Treap、Trie、哈夫曼树等。
- 图形结构:数据与数据之间是多对多的关系。主要有邻接矩阵和邻接表。
存储结构就是数据在计算机中是怎样进行存储的,主要分为:
- 顺序存储:用一组连续的空间来进行存储,底层用数组实现。
- 链式存储:存储空间可以是不连续的,底层用链表实现。
二、数组
1. 什么是数组?
关于数组的概念就不多说了,大家应该都知道。数组因为有索引,所以数组的优点就是查询快。这里强调两点,一是数组只能存储同一类型的数据,可以是基本类型也可以是引用类型,二是数组长度是不可变的。
2. 封装数组:
java给我们提供的数组可以进行的操作有限,我们可以将数组再次封装一下,让其可以进行增删改查等操作。
public class Array{
private E[] data;//存储数据的数组
private int size;//数组中元素的个数
/** 构造函数,capacity表示数组的容量,即length */
public Array(int capacity){
data = (E[]) new Object[capacity];
size = 0;
}
/** 默认构造函数 */
public Array(){
this(10);
}
/** 获取数组中元素的个数 */
public int getSize(){
return size;
}
/** 获取数组的容量,即length */
public int getCapacity(){
return data.length;
}
/** 判断数组是否为空 */
public boolean isEmpty(){
return size == 0;
}
/** 往数组末尾添加元素 */
public void addLast(E e){
add(size,e);
}
/** 往数组第一个位置添加元素 */
public void addFirst(E e){
add(0,e);
}
/** 往数组index索引处添加元素 */
public void add(int index,E e){
if (size == data.length)
throw new IllegalArgumentException("数组已满");
if (index < 0 || index > size)
throw new IllegalArgumentException("插入位置不合法");
for (int i = size - 1;i >= index; i --){
data[i+1] = data[i];//目标位置之后(包括目标位置)的元素后移
}
data[index] = e;
size ++;
}
/** 获取index索引处的元素 */
public E get(int index){
if (index < 0 || index >= size)
throw new IllegalArgumentException("查询位置不合法");
return data[index];
}
/** 获取最后一个元素 */
public E getLast(){
return get(size - 1);
}
/** 获取第一个元素 */
public E getFirst(){
return get(0);
}
/** 修改index索引处的元素 */
public void update(int index,E e){
if (index < 0 || index >= size)
throw new IllegalArgumentException("查询位置不合法");
data[index] = e;
}
/** 查找数组中是否包含元素e */
public boolean contains(E e){
for (int i = 0; i < size; i++){
if (data[i] .equals(e)) return true;
}
return false;
}
/** 查找元素e所在的索引 */
public int find(E e){
for (int i = 0; i < size; i++){
if (data[i].equals(e)) return i;
}
return -1;
}
/** 删除index索引处的元素 */
public E remove(int index){
if (index < 0 || index >= size)
throw new IllegalArgumentException("位置不合法");
E temp = data[index];
for (int i = index + 1;i< size; i++){
data[i-1] = data[i];//目标位置之后的元素前移
}
size --;
data[size] = null;//这句话可有可无
return temp;
}
/** 删除数组中的第一个元素 */
public E removeFirst(){
return remove(0);
}
/** 删除数组中的最后一个元素 */
public E removeLast(){
return remove(size-1);
}
/** 删除指定元素e */
public void removeElement(E e){
int index = find(e);
if (index != -1){
remove(index);
}
}
@Override
public String toString(){
StringBuilder res = new StringBuilder();
res.append(String.format("size = %d,capacity = %d\n",size,data.length));
res.append("[");
for (int i = 0;i < size; i++){
res.append(data[i]);
if (i != size -1){
res.append(", ");
}
}
res.append("]");
return res.toString();
}
}
上面就将静态数组再次封装了一下,可以对数组元素进行增删改查等操作。但是呢这还是静态数组,也就是说,我们new Array的时候传入的capacity是多少,那么这个数组长度就是多少,不能再改变了。接下来看看动态数组如何实现。
3. 动态数组:
要动态的改变数组的长度,其实是不能直接实现的。但是我们可以创建一个新数组,将旧数组的的元素全都放入新数组,然后让旧数组的引用指向新数组即可。看代码实现:
/** 给数组扩容 */
private void resize(int newCapacity) {
E[] newData = (E[]) new Object[newCapacity];//新数组
for (int i = 0; i< size;i++){
newData[i] = data[i];//旧数组的值存入新数组对应的位置
}
data = newData;//指向新数组
}
有了这个方法,就可以对刚才上面的add和remove方法做一些修改。
/** 往数组index索引处添加元素 */
public void add(int index,E e){
if (index < 0 || index > size)
throw new IllegalArgumentException("插入位置不合法");
if (size == data.length)//数组已满
resize(2 * data.length);//扩容两倍,如果以前为10,现在就是20
for (int i = size - 1;i >= index; i --){
data[i+1] = data[i];
}
data[index] = e;
size ++;
}
/** 删除index索引处的元素 */
public E remove(int index){
if (index < 0 || index >= size)
throw new IllegalArgumentException("位置不合法");
E temp = data[index];
for (int i = index + 1;i< size; i++){
data[i-1] = data[i];
}
size --;
if (size == data.length/4 && data.length / 2 != 0){//如果删除元素后数组只使用了1/4的容量
resize(data.length/2);//那就缩小到以前容量的一半
}
return temp;
}
小结:数组是线性结构的,一经定义长度就不可变。删除数组中元素的思路就是将目标元素之后的元素都前移一位;添加元素的思路就是将目标位置开始的元素都后移一位,再把目标元素添加到目标位置;给数组动态地扩容的思路就是创建一个容量更大的新数组,把旧数组的元素放到新数组对应的位置,最后把旧数组的引用指向新数组。
三、链表
1. 什么是链表?
链表也是一种线性结构。上面说的动态数组、栈和队列,底层都是用静态数组实现的,而链表是一种简单的真正的动态数据结构。它也可以辅助实现其他的数据结构,也就说,像栈和队列,也可以链表来实现。链表是用节点来存储数据的,节点中有数据域和指针域,数据域存放数据,指针域连接下一个节点。这就像火车一样,火车车厢用来搭载乘客,同时每一节车厢又连接着下一节车厢。静态数组定义时就需要声明长度,使用的是计算机中连续的内存空间,可以通过索引访问元素,因此查询元素是非常快的。而链表所使用的空间是不连续的,长度也是不固定的,无法通过索引访问元素,所以查询慢,而增删很快,因为增删时只需要改变一个节点的指针域即可。
2. 链表的实现:
上面说到了链表是用节点来存放数据的,同时节点又连接着下一个节点。所以先要有一个节点类Node,Node应该要有两个属性,一个是用来存放数据的,应该定义为泛型,另一个属性就是Node类型的next,表示的是下一个节点。链表类就应该int类型的size属性,用来记录链表中元素的个数,Node类型head属性,表示链表的头节点。现在来分析一下链表是如何添加和删除元素的。
-
添加元素:
有如下链表:
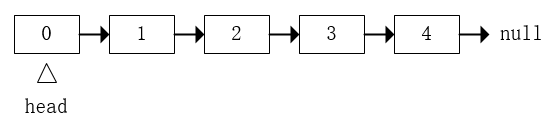 链表
链表
现要在链表最前面添加一个节点node,那么应该执行的操作就是:
node.next = head;
head = node;
添加完成后就成了这样:
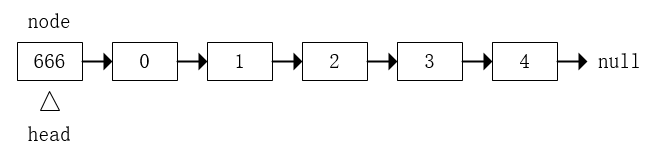
如果是要在链表中间的某个位置添加元素,比如在元素 “1” 的后面添加节点 “666” ,那么首先我们要找到要插入位置之前的那个节点prev,这里prev就是 “1” 这个节点。接下来执行的操作就是:
node.next = prev.next;
prev.next = node;
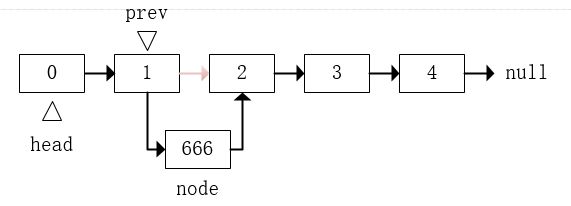
在指定位置添加元素我们需要找到目标位置的前一个节点,但是如果目标位置是第一个位置的时候,就没有前一个节点了。其实我们可以搞一个虚拟头节点。如下图。

- 删除元素:
删除节点同样也要先找到需要删除的元素的前一个节点prev,需要删除的节点假设叫做delNode。那么删除delNode要执行的操作就是:
prev.next = delNode.next;
delNode.next = null;
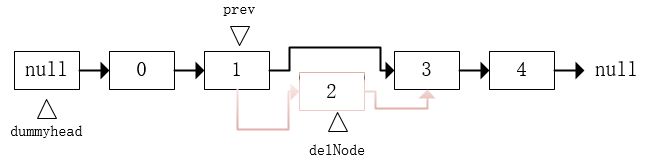
有了上面的分析,就用代码来实现链表这种数据结构。
- 代码实现:
public class MyLinkedList {
/** 节点设计成内部类 */
private class Node {
public E e;//存放的元素
public Node next;//下一个节点
public Node(E e, Node next) {
this.e = e;
this.next = next;
}
public Node(E e) {
this(e, null);
}
public Node() {
this(null, null);
}
@Override
public String toString() {
return e.toString();
}
}
private Node dummyhead;//虚拟头节点
private int size;//存储的元素个数
public MyLinkedList() {
dummyhead = new Node(null, null);
size = 0;
}
/** 获取链表中元素个数 */
public int getSize() {
return size;
}
/** 判断链表是否为空 */
public boolean isEmpty() {
return size == 0;
}
/** 在链表指定位置添加元素,(index是从0开始的) */
public void add(int index, E e) {
if (index < 0 || index > size) {
throw new IllegalArgumentException("位置不合法");
}
Node prev = dummyhead;
for (int i = 0; i < index; i++) {
prev = prev.next;//找到目标位置的前一个节点
}
/*Node node = new Node(e);
node.next = prev.next;
prev.next = node;*/
prev.next = new Node(e, prev.next);//与上面3行代码等效
size++;
}
/** 在链表末尾添加元素 */
public void addLast(E e) {
add(size, e);
}
/** 往链表头添加元素 */
public void addFirst(E e) {
add(0,e);
}
/** 获取链表指定位置的元素(index从0开始) */
public E get(int index){
if (index<0 || index>=size){
throw new IllegalArgumentException("位置不合法");
}
Node cur = dummyhead.next;
for (int i=0;i=size){
throw new IllegalArgumentException("位置不合法");
}
Node cur = dummyhead.next;
for (int i=0;i=size){
throw new IllegalArgumentException("位置不合法");
}
Node prev = dummyhead;
for (int i = 0;i");
cur = cur.next;
}
res.append("NULL");
return res.toString();
}
}
小结:链表也是线性结构的,是一种不同于数组的动态数据结构,链表的英文翻译的linkedList,注意和java提供的LinkedList集合区分开,LinkedList集合底层正是用链表实现的。
四、栈
1. 什么是栈?
栈就类似于水桶,只有水桶口一个开口,用水桶装水的时候,最先装到的水在桶底,而用水桶中的水的时候,最先用的是最后装的在最上面的水。栈也是这样,只允许在栈顶操作,元素有后进先出(last in first out,简称LIFO)的特点,添加元素叫入栈,删除元素叫出栈。
2. 栈的应用:
- 撤销功能:我们都知道像word记事本等编辑器的撤销功能,其实就是使用栈来实现的。你的操作都会记录在栈中,当你撤销的时候,你最后的操作就会出栈,就恢复到之前的状态。
- 程序调用的系统栈:比如有三个方法A、B、C,A方法执行到第三行调用了B,B执行到第四行调用了C,那么当C执行完后,从哪里开始执行呢?其实当执行A方法转而去执行B方法的时候,系统栈就会记录这个位置,比如这个位置叫A3,执行B方法转而去执行C方法的时候,也会记录这个位置,比如叫B4,那么现在系统栈中自顶向下为B4、A3。当执行完C后,发现系统栈中栈顶元素为B4,那么计算机就知道接下来就从B方法的第四行开始执行了。
- 括号匹配问题:一般的编辑器都会检查你输入的括号是否有效,'(' 以 ')'闭合时为有效,'(' 以 '}' 闭合是为无效。这就是用栈来实现检查这个功能的。
3. 栈的实现:
栈可以基于数组实现,也可以使用链表实现。先看看基于数组如何实现。
- 首先创建一个Stack接口,提供对栈的一些操作的方法。
public interface Stack {
/** 获取栈中元素个数 */
int getSize();
/** 栈是否为空 */
boolean isEmpty();
/** 添加元素 */
void push(E e);
/** 删除元素 */
E pop();
/** 获取栈顶元素 */
E peek();
}
- 基于数组(自己封装的数组)实现栈。
public class ArrayStack implements Stack {
Array array;//自己封装的动态数组
/** 构造方法,初始化栈 */
public ArrayStack(int capacity){
array = new Array<>(capacity);
}
public ArrayStack(){
array = new Array<>();
}
@Override
public int getSize() {
return array.getSize();
}
@Override
public boolean isEmpty() {
return array.isEmpty();
}
@Override
public void push(E e) {
array.addLast(e);//因为只能在栈顶添加,所以是addLast
}
@Override
public E pop() {
return array.removeLast();//因为只能在栈顶删除,所以是removeLast
}
@Override
public E peek() {
return array.getLast();//数组的最后一个就是栈顶元素
}
public int getCapacity(){
return array.getCapacity();
}
@Override
public String toString(){
StringBuilder res = new StringBuilder();
res.append("Stack:");
res.append("[");
for (int i = 0;i - 基于链表(自己实现的链表)实现栈:
public class LinkedListStack implements Stack {
private MyLinkedList list;//自己实现的链表
public LinkedListStack(){
list = new MyLinkedList<>();
}
@Override
public int getSize() {
return list.getSize();
}
@Override
public boolean isEmpty() {
return list.isEmpty();
}
@Override
public void push(E e) {
list.addFirst(e);
}
@Override
public E pop() {
return list.removeFirst();
}
@Override
public E peek() {
return list.getFirst();
}
@Override
public String toString(){
StringBuilder res = new StringBuilder();
res.append("Stack: top");
res.append(list);
return res.toString();
}
}
上面分别基于数组和链表实现了栈的一些基本操作。为了操作的方便,基于数组的时候,数组末尾是栈顶,基于链表的时候,链表头是栈顶。java.util包中也有一个Stack类,就是java提供的实现好了的栈,它提供的方法也和上面的差不多。
- 栈的应用例子(括号匹配问题):
问题描述:给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效。
有效字符串需满足:左括号必须用相同类型的右括号闭合。左括号必须以正确的顺序闭合。
public boolean isValid(String s){
Stack stack = new Stack<>();
for (int i=0;i 小结:栈也是线性结构的,只允许在栈顶操作,添加元素叫入栈,删除元素叫出栈,元素有先进后出的特点。
五、队列
1. 什么是队列?
队列也是一种线性结构,它只能从队尾添加元素,从队首取出元素,是一种先进先出(first in first out,简称FIFO)的数据结构。就跟生活当中的排队是一样的,要排队只能从队尾加入,从队首离开。
2. 队列的实现:
- 首先创建一个Queue接口,提供操作队列的一些方法。
public interface Queue {
/** 获取队列中元素的个数 */
int getSize();
/** 判断队列是否为空 */
boolean isEmpty();
/** 入队 */
void enqueue(E e);
/** 出队 */
E dequeue();
/** 获取队首元素 */
E getFront();
}
- 基于数组(自己实现的动态数组)实现队列:
public class ArrayQueue implements Queue {
private Array array;
public ArrayQueue(int capacity){
array = new Array<>(capacity);
}
public ArrayQueue(){
array = new Array<>();
}
@Override
public int getSize() {
return array.getSize();
}
@Override
public boolean isEmpty() {
return array.isEmpty();
}
public int getCapacity(){
return array.getCapacity();
}
@Override
public void enqueue(E e) {
array.addLast(e);
}
@Override
public E dequeue() {
return array.removeFirst();
}
@Override
public E getFront() {
return array.getFirst();
}
@Override
public String toString(){
StringBuilder res = new StringBuilder();
res.append("Queue:");
res.append("front [");
for (int i = 0;i - 基于链表(自己实现链表)实现队列:
public class LinkedListQueue implements Queue {
private class Node {
public E e;//存放的元素
public Node next;//下一个节点
public Node(E e, Node next) {
this.e = e;
this.next = next;
}
public Node(E e) {
this(e, null);
}
public Node() {
this(null, null);
}
@Override
public String toString() {
return e.toString();
}
}
private Node head,tail;//头节点和尾节点
private int size;//元素个数
public LinkedListQueue(){
head = null;
tail = null;
size = 0;
}
@Override
public int getSize() {
return size;
}
@Override
public boolean isEmpty() {
return size == 0;
}
/** 入队,在链表的尾部进行操作 */
@Override
public void enqueue(E e) {
if (tail == null){
tail = new Node(e);
head = tail;
}else {
tail.next = new Node(e);
tail = tail.next;
}
size ++;
}
/** 出队,在链表头操纵 */
@Override
public E dequeue() {
if (isEmpty()){
throw new IllegalArgumentException("队列为空");
}
Node delNode = head;
head = head.next;
delNode.next = null;
if (head == null){
tail = null;
}
size --;
return delNode.e;
}
@Override
public E getFront() {
if (isEmpty()){
throw new IllegalArgumentException("队列为空");
}
return head.e;
}
@Override
public String toString(){
StringBuilder res = new StringBuilder();
res.append("queue:front ");
Node cur = head;
while (cur != null){
res.append(cur + "--> ");
cur = cur.next;
}
res.append("NULL tail");
return res.toString();
}
}
基于链表的队列并没有直接使用上面第三部分实现的链表,而是重新写了一下,把虚拟头节点去掉了,同时多维护了一个尾节点tail。这样一来,入队操作在链表尾部进行,出队操作在链表头部进行,时间复杂度都是O(1),如果不维护一个尾节点,那么入队和出队总有一个时间复杂度是O(n)。基于数组的队列出队这个操作,出队是删除队首元素,对应的底层数组的操作就是删除数组中第一个元素,删除第一个元素的话,那么其他元素都得往前移一位,所以这个时间复杂度是O(n)的。因此就出现了循环队列。
3. 循环队列:
- 循环队列分析:
上面说到了,出队的时候会导致底层数组第二个元素开始都前移一位,这样性能不是很好。循环队列就是用front来记录队首的位置,tail指向队尾元素的后一个位置。一开始数组为空时,front和tail同时指向底层数组的0索引处,即
front == tail //队列为空
当有元素入队时,tail++即可,当0索引处的元素出队后,front++即可,后面的元素不用前移,这样就性能就提升了。
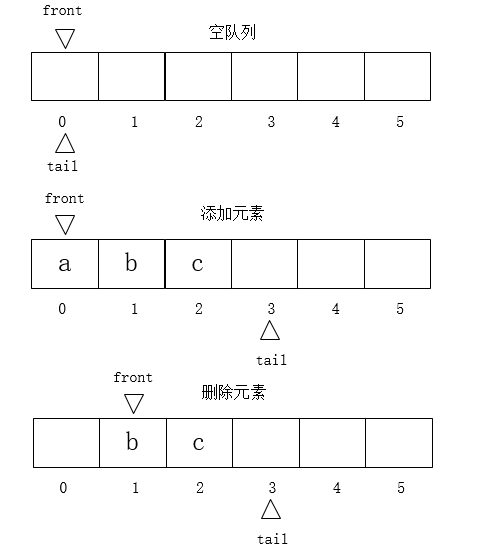
在上图删除元素的基础上继续添加元素,当索引为4处也存放有元素了,此时tail指向索引5,那么tail++就超出索引范围了,若要往索引5处添加元素,此时tail应该指向0才对,这才是循环队列。

如果要让tail指向5后再指向0,其实tail++是不能实现的,应该是
tail = (当前索引 + 1) % 数组长度
在上图,tail指向的0索引处是没有元素的,如果此时再往0索引处添加元素,那么tail就等于1,又和front相等了。上面说了,front 等于 tail的时候是队列为空,现在队列满又是这种情况,所以不行。因此规定:
tail + 1 == front //队列已满
所以循环队列是浪费了数组的一个空间的。
- 编码实现循环队列:
同样实现Queue接口。
public class LoopQueue implements Queue {
private E[] data;//存放元素的数组
private int front,tail;//队首和队尾
private int size;//队列中元素个数
public LoopQueue(int capacity){
data = (E[]) new Object[capacity+1];
front = 0;
tail = 0;
size = 0;
}
public LoopQueue(){
this(10);
}
/** 获取队列容积(数组长度 - 1 ) */
public int getCapacity(){
return data.length - 1;
}
@Override
public int getSize() {
return size;
}
@Override
public boolean isEmpty() {
return front == tail;
}
@Override
public void enqueue(E e) {
if ((tail + 1)% data.length == front){//队列已满
resize(getCapacity() * 2);//给数组扩容
}
data[tail] = e;
tail = (tail + 1) % data.length;
size ++;
}
/** 给数组扩容 */
private void resize(int newCapacity) {
E[] newData = (E[]) new Object[newCapacity + 1];
for (int i=0;i 小结:队列也是线性结构的,跟生活中的排队是一样的,在队首删除元素,队尾添加元素,有先进先出的特点。
六、递归
本文本来是讲数据结构,但这里先说说递归,因为接下来的几种数据结构都有用到递归算法。
1. 什么是递归?
递归,就是方法里面调用方法自身。我们直到方法里面也可以调用其他的方法,调用其他方法也很容易理解,其实方法里面也可以调用方法本身,如下:
public void fun(){
fun();
}
但是上面这段代码运行一段时间后会报错,因为这个递归没有结束条件,会形成死循环,一直往栈中压入fun方法,最后导致栈内存溢出。所以递归一定要有结束条件。还要注意,如果递归太深了,即使有结束条件,也可能会出现栈内存溢出错误。
2. 递归的使用:
需求:求1到n的和。
- 分析:
/** 使用递归求1到n的和 */
public int sum(int n){
}
假设现在传入的n等于4,那么就是求1到4的和。1到4的和就可以写出如下形式:
4 + 3 + 2 + 1 //sum(4) 求1到4的和
4后面的 3 + 2 + 1 又可以看成是求1到3的和,因此可以写成:
4 + sum(3)
sum(3) 其实又可以写成 3 + sum(2) ,因此整体又变成:
4 + 3 + sum(2)
sum(2) 又可以写成 2 + sum(1),因此又变成:
4 + 3 + 2 + sum(1)
写到这里,我们发现了规律,其实求1到n的和,就可以写成 n + sum(n-1) 。那么结束条件是什么呢?通过上面的分析可知,因为 sum(1) 就是等于1,所以结束条件就是当 n等于1 的时候,直接返回一个 1 就行了。
- 递归实现1到n的求和:
/** 使用递归求1到n的和 */
public int sum(int n){
if (n == 1){
return 1;
}
return n + sum(n-1);
}
上面分析了一下如何使用递归求1到n的和,并且给出了实现。下面就来看一下这段求和代码具体的执行过程:
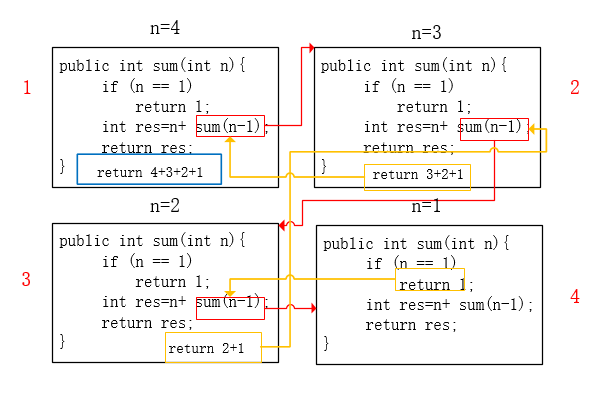
首先看红线的执行流程,图一中,传进去的n是4,执行到第四行时,变成了
4 + sum(3),接着就跳到了图二,传进去的n为3,执行到第四行,就变成了
3 + sum(2),再次调用sum方法,到了图三,传进去的n是2,执行到第四行,变成了
2 + sum(1),最后到了图四,传进去的n是1,执行到第三行,返回一个1;这个时候看黄线的执行流程,这个1就是图三的sum(1)的执行结果,把这个1回传到图三中,所以图三中返回的res就是
2 + 1 ,图三return的 2 + 1 再传给图二,结果图二return的就是
3 + 2 + 1,这个结果再传给图一,最后return的就是
4 + 3 + 2 + 1。
总结:
为避免篇幅过长,本文就先聊到这。本文主要说了一下数组、链表、栈和队列这四种线性结构。数组和链表是最基本的数据结构,可以辅助实现其他数据结构,像栈和队列,既可以用数组实现,也可以用链表实现。用数组实现的叫顺序存储,用链表实现的叫链式存储。最后还说了一下递归,为接下来的学习做准备。