作者:敏丞
前言
在上篇文章里,我们比较了 Kylin 和 Druid 这两个重要的 OLAP引擎的特点,也分析了 Kylin on HBase 的不足,得出了使用 Druid 代替 HBase 作为 Kylin 存储的方案,最后介绍了美团开发的 Kylin on Druid 的架构和流程。在这篇文章中,我们接着上篇文章,将介绍如何使用 Kylin on Druid,Kylin on Druid 的性能表现,以及在使用过程中总结的一些经验。
如何使用Kylin on Druid
准备阶段
准备一个 Druid 集群,并且注意以下几点:
a) 使用 MySQL 作为元数据存储
b) 使用 HDFS 作为 Deep Storage
c) Druid 版本至少为 0.11
d) 因为数据存储和聚合都在 Historical 执行,需要将主要的资源分配给 Historical(Middle Manager 和 Overload 在 KOD 中并不被使用)
从 Kylin 的 Github 仓库获取 kylin-on-druid 分支的最新代码并打包。
修改 kylin.properties,增加配置项。
请参考:
https://github.com/apache/kylin/blob/kylin-on-druid/storage-druid/README.md,以下仅列举主要配置
a) kylin.storage.druid.coordinator-addresses 指定了 Druid 的 coordinator 节点地址
b) kylin.storage.druid.broker-host 指定了 Druid 的 Broker 节点地址
c) kylin.storage.druid.mysql-url 指定了作为 Druid 元数据存储的 MySQL 的 JDBC url
d) kylin.storage.druid.mysql-seg-table 指定了 Druid 元数据存储 segment 信息的 MySQL 表名
e) kylin.storage.druid.hdfs-location 指定了 Druid Segment 文件在 HDFS 的存储路径
以下是测试环境的配置:

图 1 Kylin 配置文件
按照正常的启动方式启动Kylin。
构建 Cube 阶段
1. 在 Cube Design 界面的第五步(高级设置)设置 Cube Engine 和 Cube Storage 分别为 MapReduce 和 Druid。Cube 设置全部完成后,选择“ Build Cube ”。

图 2 高级设置中的 Cube Storage 选项
2. 观察 Cube 构建过程,等待构建完成,以下展示了构建 Cube 各个新增步骤的说明和步骤运行成功时的输出信息:
a) “Calculate Shards Info”根据配置项,计算出 Druid Segment File 的数量。

图 3 Calculate Shards Info
从 Output 看出这里设置为 2 个 Segment File,每个约 500 MB。
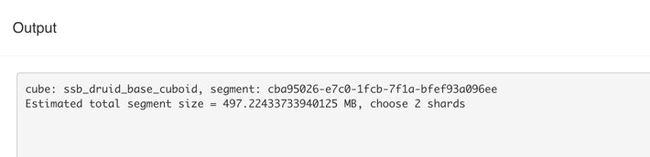
图 4 Calculate Shards Info 输出
b) “Update Druid Tier” 更新 Druid Tier 的 Rule
图 5 Update Druid Tier
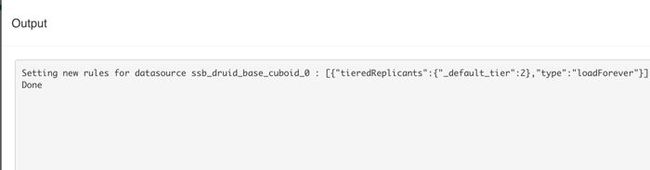
图 6 Update Druid Tier 输出
c) “Convert Cuboid to Druid” 启动一个 MapReduce Job,将 Cuboid 文件转为 Druid 的列式存储格式,生成数据放到 HDFS 的指定目录

图 7 Convert Cuboid to Druid
MapReduce Job 的统计数据

图 8 Convert Cuboid to Druid 输出
该步骤结束时可以检查到文件已经存在于 HDFS 上。

图 9 Convert Cuboid to Druid 生成文件
d) “Load Segment to Druid” 通过 MySQL 来向 Druid 集群 announce 新的 Druid Segment,等到 Segment 已经完全被分发到各个 Druid Historical 才结束该 step。

图 10 Load Segment to Druid
从 Output 看到,首先修改 MySQL 元数据信息花费了 0.11 秒,然后等待 Druid 集群将上步生成的两个 segment 文件 download 到 Historical,这个过程时间约为两分钟。

图 11 Load Segment to Druid 输出
运行过程中观察 Coordinator Web UI,可以看到 Data Source 的图标从红色变成蓝色。
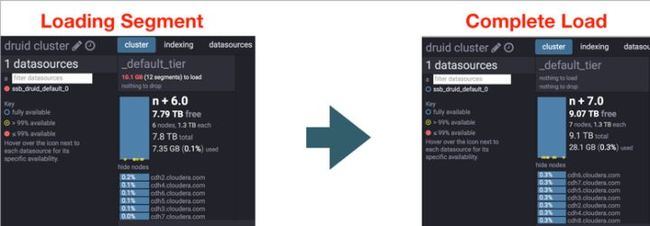
图 12 Coordinator Web UI
e) Cube 构建完成

图 13 Cube 构建完成
f) 检查 Druid Segment 状态和分布,检查 Schema 是否正确(可选);通过 Druid API 查看 Cube 对应的 Druid Data Source 的元数据。
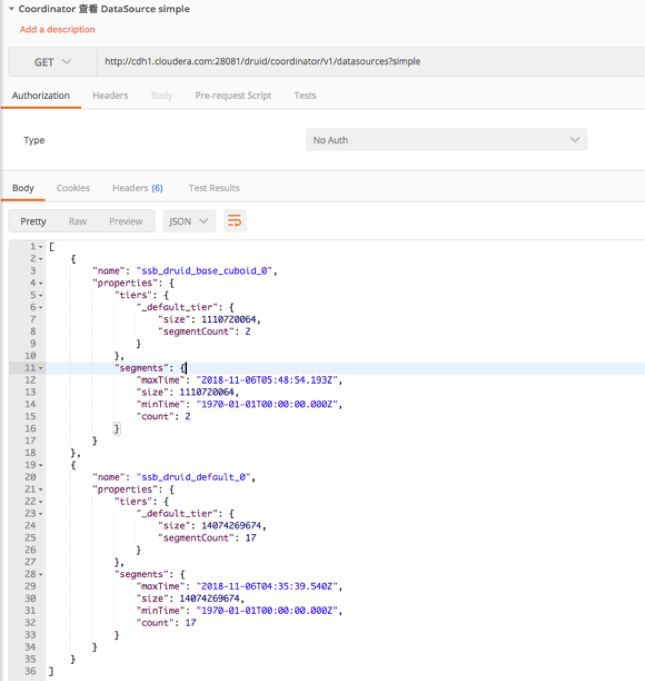
图 14 Data Source Schema
通过 Druid API 查看 Druid Segments 的明细数据。
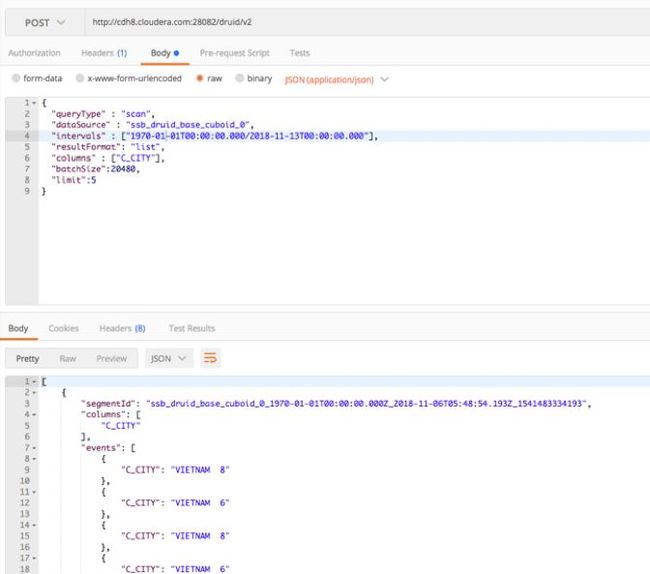
图 15 Data Source Data
检查单个节点的上已经从 Deep Storage 下载下来的 Segment 数据文件。

图 16 Local Cache
Kylin on Druid 的查询时长对比
我们在测试环境下基于 SSB 数据构建不同 Cube,通过比较在不同 Cube 上相同 SQL 的查询用时,来了解使用 Kylin on Druid 对查询用时的影响。
我们使用 SSB 生成测试数据,数据量 29,999,795。
Druid 集群规格如下:
8 台虚拟机(8core, 65GB Memory),其中一台部署 Overlord 和 Coordinator,1 台部署 Broker,6 台部署 Middle Manager 和 Historical,其中 Historical 配置参数如下。

图 17 Historical JVM 参数
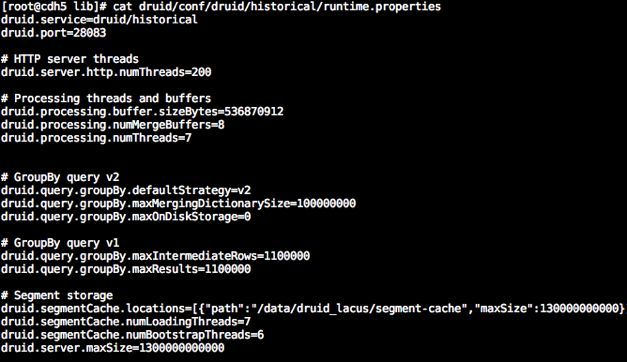
图 18 Historical 参数
以下为三种 Cube 构建方案的描述:
Druid Base(绿色列)指的是使用 Druid 作为存储,只构建 Base Cuboid
HBase Base(蓝色列)指的是使用 HBase 作为存储,只构建 Base Cuboid
HBase Default(红色列)指的是使用 kylin-ssb 默认的 cube 元数据的构建方案
下图为三种方案构建的 Cube 在不同查询语句下的平均查询用时对比
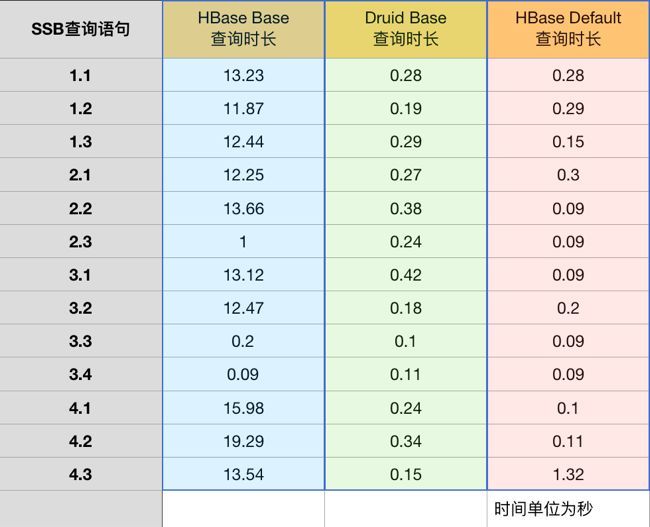
图 19 SSB 查询时长
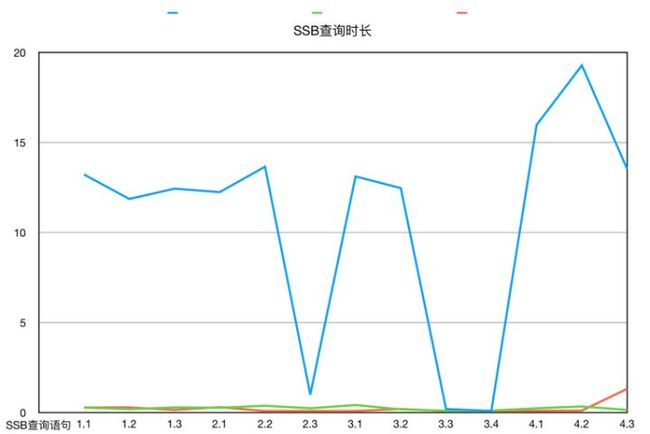
图 20 SSB 查询时长-折线图
结论
关于构建 Cube 时间和 MapReduce 内存,使用 Druid 占用资源略多。基于 Druid 只构建 base cuboid 得到的 Cube,与基于 HBase 根据复杂剪枝设置得到的 Cube 有了相当的查询性能。可见利用 Druid 高效的 filter 和 scan,Kylin 的现场计算能力有了十分明显的提升。而如果 Cube 设计得当,且计算较多 Cuboid 的话,HBase 的性能跟 Druid 不分伯仲。
美团 Kylin on Druid 的线上环境表现
美团点评是 Apache Kylin 的重度用户,Kylin 覆盖了美团点评主要业务线,截止 2018 年 8 月的数字,每天的查询次数超过 380 万次。美团第一批上线使用 Kylin on Druid 后,Cube 存储使用减少了约 79%,构建过程的内存和 CPU 使用减少了 20% 左右;从查询时长观察,大部分的查询用时减少了 50% 以上(图21来自于 Kylin 北京 Meetup 上康凯森的分享内容)。

图 21 Kylin Meetup PPT
Kylin on Druid 的总结
目前 Kylin on Druid 的限制和要求
要求 Druid 使用 MySQL 作为元数据存储,使用 HDFS 作为分布式存储
Druid 需要 0.11 版本或者以上,Java 需要 JDK8 或者以上
Cube 构建目前只支持 MapReduce
Cuboid 数量相同时,Kylin on Druid 较使用 HBase 构建 Cube 而言,时间和计算资源使用一般稍多
Measure 尚不能完全支持,美团近期即将开源的包括 EXTENDED_COLUMN、Count Distinct(BitSet),这些 Measure 需要以向 Druid 添加扩展的方式支持;Count Distinct(HyperLogLog) 后续根据需求开发
Decimal 类型在 Druid 端使用 double 替换,美团近期也会提供准确的 Decimal 类型支持
转换为 Druid Segment 步骤使用内存比转HFile更多,一般需要分配更多内存
Kylin on Druid 的优势
1. 查询时无需加载字典,因此相比 Kylin on HBase 查询稳定性更高
2. 存储层支持业务隔离
3. 亿级及以下数据只需构建 Base Cuboid
4. 构建资源使用减少(因为需要构建的 Cuboid 数量减少了),查询时长减少(因为现场计算能力有了比较好的提升)
何时使用Kylin on Druid
1. 对 Druid 有充分的理解,有足够的经验去部署和运维 Druid 集群
2. 有足够的机器资源部署Druid
3. 查询没有较为固定的模式,因此大部分查询难以精确匹配Cube预计算得到的维度组合,可以利用Kylin on Druid来加速现场计算能力
4. 对查询响应速度有较高的要求
总结
在这两篇文章中,我们一步一步分析 Kylin 目前使用 HBase 作为存储的不足之处,同时比较了 Kylin 和 Druid 各自的特点,得出了将两者相结合的 Kylin on Druid 的方案。
随后介绍了美团开发的 KOD 使用方式,通过不同 Cube 构建方案的查询时长对比,得出 KOD 较原有 HBase 存储有较大性能和易用性提升的结论。最后总结了 KOD 的优势和使用经验,也了解到 KOD 目前有部分功能尚未完成。
目前这部分代码在 Kylin 的 Git 仓库的“ kylin-on-druid ”分支,欢迎广大开发者试用并积极参与开发和改进,更多问题可以发送到 Kylin 开发者邮件群组 [email protected] 进行讨论,谢谢大家。
参考链接
https://issues.apache.org/jira/projects/KYLIN/issues/KYLIN-3694
https://github.com/apache/kylin/tree/kylin-on-druid
https://blog.bcmeng.com/post/kylin-on-druid.html
http://druid.io/docs/latest/design