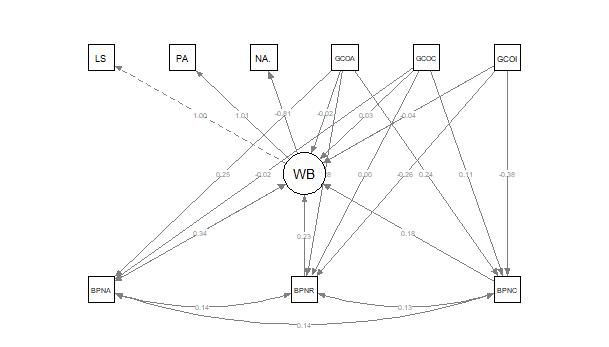
大家好,我是一个研究积极心理学的教育学博士,这是我在土澳的日常
前几天的一个晚上,需要做一个结构方程模型(SEM)来分析一个中介变量。我打开SPSS,把数据存成.dat格式,然后准备用Mplus计算模型拟合。我编好程序,点击运行的时候突然发现发现,Mplus不能用了。这种情况以前也出现过,所以我不慌不忙地把早就准备好的安装包拿出来重装了一遍。可以用倒是可以用了,但系统提示试用版只能计算2到3个变量。我的模型有四五个变量。于是我又按照着安装包里的破解说明,重装了两三遍,还是不行。由于每次重装都要重启,这样折腾了一圈下来,转眼就过去了一个小时。
我很郁闷,以前这个安装包是可以用的,难道因为我的系统升级了?于是我上网去找新的破解版。找到几个都有各种问题。最终,我在一个论坛上找到的付费的安装包,要注册那个论坛,还要付一百多块钱!倒不是因为没有一百块钱,而是非常不愿意为这样的盗版东西付钱。
但是已经快半夜两点了,我看着时间一点一点流逝,非常气愤。心想:人家R那么强大的软件包都是免费的,一个盗版的Mplus凭什么要交一百块钱?!
诶?R是免费的?我怎么早没想到呢?
其实今年月份申请结束以后,我报了一个大数据分析的网课,利用一个月的时间学R语言和python,虽然都没有学精,但我至少电脑里装了这些软件,并且我知道它们都是免费的!而且有很多现成的分析数据的package,也都是免费的!只是我学完以后就再也没用过,所以当时心里还是有点没自信。不过现在逼上梁山了,只能硬着头皮上了。
于是我搜索了一下做结构方程模型的package,找到了一个叫做lavaan的包。
接着我在youtube上找了教学软件,尽管是英文的,不过边看操作边做还是能跟上。于是我又花两个多小时,装好了安装包(因为R很多安装包的版本兼容性不好,所以试了好几个版本花了一些时间),学会了用lavaan编结构方程模型,以及用程序直接画图(尽管不是很美观)。
凌晨4点多的时候,我终于搞定了!找免费Mplus的过程非常郁闷,但是学习R的时候还是很开心的。如果早点用R的话,我应该2点多就可以睡觉了……
搞定之后我也有一些反思:
1. 提前学习一些技能,不知道未来什么时候就会用到。
如果我不是说在四月份学过R,而当天晚上从头学,两个小时应该是搞不定这些东西的。可能甚至连R程序怎么装都没搞明白。恩,是的,当时是教数据分析的老师带着装的,因为不仅要装R,还要再装一个R studio,还有各种基础的数据分析的包等等。幸好这些我都提前搞定了。而且现学的话,那些基础代码不明白,youtube的视屏也是看不懂的,因为视频里只是从如何使用lavaan开始的。在那么紧张的凌晨,是绝对不可能淡定的从头学起的。总之很幸运地在几个月前学习了R语言,虽然当时没有用的,但是在若干个月后的某个夜晚,凌晨2点,我竟然用到了!
2. 放下自己学不会的念头,编程也好,任何事情都好,入门没你想的那么难。
尽管中学时代学过一点Basic语言编程,但从本科开始就一直学心理,很久很久没有碰过编程了。而且编程语言进化速度那么快,对程序员来说,很多时候都要重新学语言,别说我了。不过,这也说明了从头学一个编程语言不是不可能的。
最开始听到大数据分析什么的,我也觉得很恐惧,学心理的都懂得,统计是很多人不能说的伤痛。SPSS都用不熟,怎么可能还自己编程序呢?
但其实编程也不是那么难的。现在互联网发达了,很多东西都不需要自己学,都有人教,特别是入门阶段,报一个辅导班,找一个老师带着,很快就可以入门。剩下的内容就可以用多少学多少,就像我学了基础的R语言,然后老师也没有教结构方程,可是我就可以自己学了。
TED有个演讲介绍20小时入门任何技能,我觉得这个还时间还是有一定准确性的。
3. 不要花时间在没有积累的事情上,而是用来学习和投资,让努力可以积累。
同样是2个小时,如果用来找免费资源,除了积累了一些搜索免费资源的技能,什么都学不到。而如果用这两个小时学习如何使用R,如何做结构方程模型,这些技能和努力在未来是可以发挥价值的。
以前互联网还是免费的时代,很多人习惯了去寻找免费资源。但现在互联网免费资源越来越少,如果你在这个时代还在找免费的资源,那浪费的时间的价值和所收获的免费资源的价值绝对不成正比。
有句话叫做免费的才是最贵的,确实是这样。使用免费的东西总是要付出一些代价的,可能是你为某个网站贡献了流量,或者点击了广告。
总之,把你的时间和精力花在那些有积累效应的事情上,而不是浪费在寻找免费资源上。
最后附上一段代码:
***加载lavaan和画图的库***
install.packages("lavaan", dependencies=TRUE)
install.packages("stringr")
install.packages("DiagrammeR")
install.packages("dplyr")
install.packages("semPlot")
install.packages("nloptr")
library("stringr")
library('lavaan')
library("DiagrammeR")
library("dplyr")
library('nloptr')
library("semPlot")
***读入数据集***
dat1 <- read.csv("C:/Desktop/DT.csv")
***设定结构方程模型***
Model1 <- '
grit =~ GritInterest + GritPersistence
GritInterest ~~ GritPersistence
grit ~ External + Introjected + Identified + Intrinsic + GM
External ~ GM
Introjected ~ GM
Identified ~ GM
Intrinsic ~ GM
External ~~ Introjected + Identified + Intrinsic
Introjected ~~ Identified + Intrinsic
Identified ~~ Intrinsic
'
Model2 <- '
grit =~ GritInterest + GritPersistence
grit ~ External + Introjected + Identified + Intrinsic + GM
External ~ GM
Introjected ~ GM
Identified ~ GM
Intrinsic ~ GM
'
***计算拟合***
fit1 <- sem(model=Model1,data=dat1)
fit2 <- sem(model=Model2,data=dat1)
***输出拟合结果***
summary(fit1,standardized=T,fit.measures=T,rsq=T,modindices = TRUE)
summary(fit2,standardized=T,fit.measures=T,rsq=T,modindices = TRUE)
***画图***
semPaths(fit1, intercept = FALSE, whatLabel = "est",
residuals = FALSE, exoCov = FALSE)