Akka集群的基石是集群规范,规范的核心是 Gossip协议 和 FD
在gossip协议和FD之上,Akka集群提供成员服务、无单点(故障/性能单点)、P2P等功能,进而使其他集群功能开枝散叶:actor地址透明、横向扩展、Watch和监管、服务漂移、分片集群和持久化...包含集群特色功能、以及实现所有传统功能的“分布式”版本:
1、维护一个actorSys集合(cluster) 使其可以互相通讯,并且都属于集群的一部分;
2、扩容:动态添加actorSys—成员服务;
3、准确探测actorSys离线—FD;
4、容错:删除失效的hosts/systems (或者正常收缩系统) 并使剩下的成员保持完整集群;
5、集群分布式计算;
6、指派集群成员为特定角色、允许你划范围;
7、集群Sharding:解决集群中一大堆有状态实体在成员actorSys上的横向分布问题,Sharding是一种模式,往往和Persistence联合使用以负载均衡大量有状态的实体,状态需要持久化,并且当成员宕机、下线时迁移actor、再平衡;
8、集群Persistence:可以将构建actor当前状态的一系列事件进行持久化,在启动时事件流可以重放以便恢复状态,事件流可供查询和送出比如外部大数据集群当中去进一步处理。也可以持久化状态快照;
9、分布式发布订阅:为了在actorSys之间协作,经常需要广播消息,这种模式即publish-subscribe ,它既可以向一个主题的所有订阅者广播消息、也可以向任一个订阅actor发送消息;
集群规范
基础概念统一用语:
1、node节点或者叫成员:集群逻辑成员,一台物理机可以有多个节点,其实就是actorSys. 元组格式标识:hostname:port:uid. 我们不分物理机虚拟机,对Akka来说没必要,统一称节点/成员。
2、集群:通过成员服务联结成为一体的节点集合。
3、领导者:leader,一个成员,管理gossip收敛性及所有成员节点的状态转移;注意它的管理职责是轻量的,叫发言人更合适,确切的说是Gossip发言人,gossip收敛的含义等价于集群所有成员达成一致(所以当有节点Unreachable时会有收敛阻塞的暂态),收敛时发言人“宣布”这个“里程碑”,告知所有成员大家对集群状态的观察已一致;轻量意味容易被替代,不会成为单点,轻量的意思是:仅仅是在大家已经达成一致的前提下,发布这个共同决策,leader仅仅是集群所有成员共同意志的代言人。当有节点掉线或分区时,gossip无法收敛,此时集群处于暂态,此时一些集群自身的管理事务会无法进行,比如此时如果有新节点加入,那么由于gossip收敛处于“阻塞”状态,新节点的身份无法切换到Up,但是仅此而已,集群之上的业务功能都是正常的。
The gossip messages are serialized with protobuf and also gzipped to reduce payload size.
我们可以用gossip的话来描述节点正常下线过程:首先它会切换状态到leaving,当leader确认该节点的leaving状态收敛,即进行下一步:切换其状态到exiting. 当该节点的exiting状态收敛、leader即进一步将该节点从集群remove、切换其状态到removed. 我们看到gossip的就是一轮一轮的过程:新事件发生 - 逐步收敛 - 收敛 - 继续下一步状态转移,集群的状态在这个动态过程中不断演进。
成员服务
集群是由一堆成员节点组成,节点的标识是:hostname:port:uid;一个一体的AK应用系统分布在集群节点上,每个节点运行着应用的一部分,一个节点也可以是集群成员却没有运行任何actor,给集群任一节点发送命令Join加入集群。节点标识里的uid是actorSys实例的唯一标识,actorSys重启的话该id会变,也就是说成为了一个全新的actorSys,这样AK用这个id可以做到准确的远程DeathWatch。actorSys即使是就地重启,也是一个全新的actorSys(这一点和actor重启不同),即使原来属于集群,因为UID变了,所以也得重新加入集群。集群成员的状态通过CRDT分布式可收敛数据结构在多台节点机之间维护,达成最终一致。
Akka集群有两种使用场景:
1、响应式微服务:一般来说我们不推荐在不同微服务之间使用Akka集群和actor,这会导致服务间紧耦合,这种场景我们推荐Lagom Framework(每个微服务都是一个Akka集群)
对于一个服务的多个节点(分布式服务) 要尽可能少的耦合?它们共享同一套代码和部署策略,在滚动升级时可能有两个版本同时在线运行,但是整体部署有一个控制单点,因此,服务间的通讯可以利用Akka Cluster、failure management 和 actor messaging,它们使用便利、性能好。
服务间通讯还可以使用Akka HTTP、Akka gRPC进行同步非阻塞通讯synchronous (yet non-blocking) ,使用Akka Streams Kafka 或者其他 Alpakka connectors 用于集成系统的异步通讯,所有这些通讯机制都良好支持流式消息和端到端反压,同步通讯工具也可以用于单次请求响应交互,而且通讯两端不限于akka、可以跨平台。
2、传统分布式应用:相比微服务没那么复杂,比如对于小型创业公司,只有一个团队、一个产品且产品上市时间是最重要的,那么,Akka Cluster 可用于高效构建这样的产品。
这种情况下,产品由一个集群构成、一个代码基、有一个部署监控中心,那么紧耦合也可以,有时候节点还可能具备运行时角色,也就是说集群并非完全同构的(e.g., “front-end” and “back-end” nodes, or dedicated master/worker nodes),但只要代码基一样、部署构件一样,那么这仅仅是一种运行时行为,所有节点上仍然是一个代码基,没毛病,A tightly coupled distributed application has served the industry and many Akka users well for years and is still a valid choice.
Gossip
Gossip收敛(最终一致性)指一个节点看到的集群状态和其他所有节点看到的一样,gossip收敛是集群状态达到一致的标志,只有达到收敛了,leader才能继续下一步,没有达到,关于集群的事务不能往下进行。一些P2P式分布式系统使用gossip来协调一个ad-hoc(实时自主)network,简单翻译一下gossip Wiki:
Gossip protocol是一个P2P节点通讯过程,类似epidemics spread病毒传播,使用gossip协调的分布式系统可以确保集群状态数据路由到所有成员节点,这样的分布式系统不需要中央节点,传播数据的方式是每个成员都将数据接力传递给自己的邻居节点。所以gossip往往被称为病毒virus/流言rumors协议,就是因为gossip传播数据的方式正像病毒/流言传播一样:每个节点闲暇时随机pairs off配对,互相分享最近的流言蜚语.....计算机在实现这种模式协议时往往采用随机"peer selection"方式:在一个固定频率下,每个节点随机选择其他节点分享流言。gossip的弱点在于服务质量,即传播数据的完整性和时效性没有强保证。在真实的办公室流言场景,并不是所有人都能参与传播流言,八卦和广播相比有歧视性,会有参与者被排除在外,因此,办公室八卦的例子不如病毒传播例子,真实的Gossip所有成员都是对等的,不会有歧视,不管这些细节,peer-to-pee通讯技术的流行名是'gossip'.
大概得有上百种Gossip-like变种协议,这些变种会不同程度侧重如下需求:
1、协议的核心包括周期性的、成对的进程间交互;
2、在这些交互过程中交换的信息具有有限的大小;
3、当通过代理交互时,至少一个代理的状态会发生变化,以反映另一个代理的状态;
4、假设通讯不可靠;.
5、与典型的消息延迟相比,交互的频率较低,因此协议成本可以忽略不计;
6、在对等点选择中存在某种形式的随机性。对等点可以从完整的节点集合中选择,也可以从较小的邻居集合中选择;
7、由于复制,传递的信息可能存在隐式冗余;
Gossip协议类型
在最早使用“闲话”一词之前的许多协议都属于这个相当广泛的定义。例如,Internet路由协议经常使用类似八卦的信息交换。闲话基础设施可用于实现标准的路由网络:节点之间互相八卦P2P消息,有效地通过闲话层推动流量。如果带宽允许,这意味着闲话系统可能支持任何经典协议或实现任何经典分布式服务。然而,更典型的闲话协议是那些特定地以规则、周期、相对延迟、对称和无中心方式运行的协议;节点间的高度对等性是其特有的特征。因此,虽然可以在闲话基础上运行2阶段提交协议2-phase commit protocol,但是这样做与正统方式不一致。
收敛一致性这个术语有时用来描述实现信息指数级快速传播的协议。为此,协议必须将任何新信息传播到所有感兴趣节点,并限制在系统大小的对数时间内。举例:
假设我们想要在一个未知大小的网络中找到与某个搜索模式最匹配的对象,在这个网络中,每台计算机运行一个实现闲话协议的小型代理程序(相当于Akka基础通讯层),要开始搜索,首先得要求本地代理开始gossip传播搜索字符串。周期性地,以某种速率(为了简单起见,假设是每秒10次),每个代理随机选择一些其他代理,并与之闲聊。A知道的搜索字符串现在也会被B知道,反之亦然、下一轮gossip A 和 B 会配对其他节点比如 C 和D,这是一种round-by-round一轮紧接着一轮的翻倍传播,非常强效,即使丢失一些消息、或者重复消息都没什么关系。第一次收到搜索字符串时,每个代理检查其本地机器是否匹配文档,代理还会互相不断八卦目前的最佳匹配结果,因为gossip是一种信息exchange交换,你可以把你的一堆节点机想象成一大群叽叽喳喳不停的鸟。
例如,在一个拥有25,000台机器的网络中,我们可以在大约30轮闲话之后找到最佳匹配:15轮用于传播搜索字符串、15轮用于发现最佳匹配。在不增加不必要的负载的情况下,每十分之一秒就会发生一次闲话交换,因此这种形式的网络搜索可以在大约3秒内搜索整个大数据中心,这是一种近似网络风暴的强劲传播方式。
最后,比如说十秒后、搜索自然结束,搜索的发起者会自动地知道结果了。Gossip protocols have also been used for achieving and maintaining distributed database consistency or with other types of data in consistent states, counting the number of nodes in a network of unknown size, spreading news robustly, organizing nodes according to some structuring policy, building so-called overlay networks, computing aggregates, sorting the nodes in a network, electing leaders, etc. 仅有两个采用Gossip维护分布式一致性的分布式数据库cassendra、riak,因为它们不默认提供强一致保障。对于无主集群来说只能达到最终一致性—收敛,收敛的集群进入了一个完备的“稳态”,准备好安全地进行下一步集群操作了。集群成员的状态变化会以MemberEvent消息形式广播出去,MemberEvent是“动词”,表述事件:Published when the state change is first seen on a node. The state change was performed by the leader when there was convergence on the leader node, i.e. all members had seen previous state. 但是当你的订阅actor收到第一条当前集群快照消息时,它里面罗列的所有成员Member的状态属性是MemberStatus,这个MemberStatus是静态的“名词”,表述状态。Convergence收敛的实现是当gossip的时候传递一个节点集,该集内节点看到相同版本的集群状态,这个集叫seen set. 当所有节点都包含进seen set内时,即为收敛convergence.
有三个使用gossip用于在peer-to-peer网络发现节点的开源库:
1、Apache Gossip communicates using UDP written in Java, has support for arbitrary data and CRDT types.
2、gossip-python utilizes the TCP stack and it is possible to share data via the constructed network as well.
3、Smudge is written in Go and uses UDP to exchange status information; it also allows broadcasts of arbitrary data across the constructed network.
See also
1、Gossip protocols are just one class among many classes of networking protocols. See also virtual synchrony, distributed state machines,Paxos algorithm, database transactions. Each class contains tens or even hundreds of protocols, differing in their details and performance properties but similar at the level of the guarantees offered to users.
2、Some gossip protocols replace the random peer selection mechanism with a more deterministic scheme. For example, in the NeighbourCast algorithm, instead of talking to random nodes, information is spread by talking only to neighbouring nodes. There are a number of algorithms that use similar ideas. A key requirement when designing such protocols is that the neighbor set trace out an expander graph.
3、Routing
4、Tribler, BitTorrent peer to peer client using gossip protocol.
任何节点处于unreachable(不可达、网络分区)状态会阻止Gossip收敛,直到其恢复为reachable或者状态过渡到down/removed(彻底下线/剔除),也就是说,在网络分区状态下,新节点无法加入(新节点可以join加入,但是其状态无法转变为up上线),直到网络分区得到恢复或者unreachable不可达节点彻底down下线。换句话说,不可达是非正常的暂态,此时Gossip不会进行任何集群成员事务cluster membership management,直到不可达节点彻底down下线,down下线是正常的稳态。
忙碌的Gossip集群应该是更多处于暂态,暂态是各个节点机互相进行有效通讯的状态、也是不断收敛的过程(Gossip有效性也是数学上可以证明这个过程一定会向收敛方向走),收敛像重力,比如一个碗里面有个球代表集群状态,不管怎么晃动这个球总会落向碗底->收敛,收敛时是稳态,球处于碗底静止,此时没有任何集群事务发生,节点机间关于集群状态通讯的都是旧闻。
那些影响了Akka设计的papers:
Actor Model, Message-Passing Concurrency & Futures/Promises
A Universal Modular ACTOR Formalism for Artificial Intelligence - Carl Hewitt et al. - 1973
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.77.7898
Viewing Control Structures as Patterns of Passing Messages - Carl Hewitt et al. - 1976
http://dspace.mit.edu/handle/1721.1/6272
Concurrent Programming Using Actors: Exploiting Large-Scale Parallelism - Carl Hewitt, Gul Agha - 1985
http://dspace.mit.edu/handle/1721.1/6433
ACTORS: A Model of Concurrent Computation in Distributed Systems - Gul Agha - 1985
http://dspace.mit.edu/handle/1721.1/6952
Making reliable distributed systems in the presence of software errors - Joe Armstrong - 2003
http://www.erlang.org/download/armstrong_thesis_2003.pdf
Robust Composition: Towards a Unified Approach to Access Control and Concurrency Control - Mark Miller - 2006
http://www.erights.org/talks/thesis/
Towards Haskell in the Cloud - Simon Peyton Jones et al. - 2011
http://research.microsoft.com/en-us/um/people/simonpj/papers/parallel/remote.pdf
Dataflow Concurrency, STM & Concurrent Datastructures etc.
Active Object : An Object Behavioral Pattern for Concurrent Programming - R. Greg Lavender, Douglas C. Schmidt - 1996
http://www.cs.wustl.edu/~schmidt/PDF/Act-Obj.pdf
SEDA: An Architecture for Well-Conditioned, Scalable Internet Services - Matt Welsh, et al. - 2001
http://www.eecs.harvard.edu/~mdw/papers/seda-sosp01.pdf
Ideal Hash Tries - Phil Bagwell - 2001
http://lampwww.epfl.ch/papers/idealhashtrees.pdf
Concepts, Techniques, and Models of Computer Programming - Peter Van Roy, Seif Haridi - 2004
http://en.wikipedia.org/wiki/Concepts,_Techniques,_and_Models_of_Computer_Programming
Mozart/Oz Programming System - Dataflow Concurrency
http://www.mozart-oz.org/documentation/tutorial
Composable Memory Transactions - Simon Peyton Jones et al. - 2005
http://research.microsoft.com/en-us/um/people/simonpj/papers/stm/stm.pd
Transactional Locking II - Dave Dice et al. - 2006
http://labs.oracle.com/scalable/pubs/DISC2006.pdf
Values and Change - Clojure's approach to Identity and State - Rich Hickey - 2009
http://clojure.org/state
Are We There Yet? (video) - Rich Hickey - 2009
http://www.infoq.com/presentations/Are-We-There-Yet-Rich-Hickey
Distributed Computing & Distributed Databases
Time, Clocks, and the Ordering of Events in a Distributed System - Leslie Lamport - 1978
http://research.microsoft.com/en-us/um/people/lamport/pubs/time-clocks.pdf
Distributed Snapshots: Determining Global States of Distributed Systems - Leslie Lamport - 1985
http://www.cs.swarthmore.edu/~newhall/readings/snapshots.pdf
Timestamps in Message-Passing Systems That Preserve the Partial Ordering - Colin J. Fidge - 1988
http://zoo.cs.yale.edu/classes/cs426/2012/lab/bib/fidge88timestamps.pdf
A Note On Distributed Computing - Jim Waldo et al. - 1994
http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.41.7628
The Eight Fallacies of Distributed Computing - Peter Deutsch - 1994
https://blogs.oracle.com/jag/resource/Fallacies.html
A Gossip-Style Failure Detection Service - Robert Van Renesse et al. - 1998
http://www.cs.cornell.edu/home/rvr/papers/GossipFD.pdf
Paxos Made Simple - Leslie Lamport - 2001
http://research.microsoft.com/en-us/um/people/lamport/pubs/paxos-simple.pdf
Chord: A Scalable Peer-to-peer Lookup Service for Internet Applications - Ion Stoica et al. - 2001
http://pdos.csail.mit.edu/papers/chord:sigcomm01/
Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-Tolerant Web Services - Nancy Lynch et al. - 2002
http://lpd.epfl.ch/sgilbert/pubs/BrewersConjecture-SigAct.pdf
Push-Pull Gossiping for Information Sharing in Peer-to-Peer Communities - Mujtaba Khambatti et al. - 2003
http://khambatti.com/mujtaba/ArticlesAndPapers/pdpta03.pdf
The ϕ Accrual Failure Detector - Naohiro Hayashibara et al. - 2004
http://ddg.jaist.ac.jp/pub/HDY+04.pdf
GEMS: Gossip-Enabled Monitoring Service for Scalable Heterogeneous Distributed Systems - R Subramaniyan et al. - 2005
http://www.hcs.ufl.edu/pubs/GEMS2005.pdf
Dynamo: Amazon’s Highly Available Key-value Store - Werner Vogels et al. - 2007
http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf
Convenience Over Correctness - Steve Vinoski - 2008
http://steve.vinoski.net/pdf/IEEE-Convenience_Over_Correctness.pdf
Efficient Reconciliation and Flow Control for Anti-Entropy Protocols - Robert Van Renesse et al. - 2008
http://www.cs.cornell.edu/home/rvr/papers/flowgossip.pdf
Cassandra - A Decentralized Structured Storage System - Avinash Lakshman et al. - 2009
http://www.cs.cornell.edu/projects/ladis2009/papers/lakshman-ladis2009.pdf
Riak Distributed Database - 2012
http://basho.com/resources/white-papers/
CAP Twelve Years Later: How the "Rules" Have Changed - Eric Brewer - 2012
http://www.infoq.com/articles/cap-twelve-years-later-how-the-rules-have-changed
Event Sourcing & CQRS
Event Sourcing - Martin Fowler - 2005
http://martinfowler.com/eaaDev/EventSourcing.html
Unshackle Your Domain - Greg Young - 2009
http://www.infoq.com/presentations/greg-young-unshackle-qcon08
CQRS - Martin Fowler - 2011
http://martinfowler.com/bliki/CQRS.html
Failure Detector
FD(failure detector)负责探测一个节点是不是“离群”了,也就是不可达了. For this we are using an implementation of The Phi Accrual Failure Detector by Hayashibara et al....失效嗅探者,暂时先知道它基于心跳探测是否有节点是不可达的,同样也用于探测节点重新恢复可达了。心跳每秒一次,是一种r-r同步请求响应握手消息。
如果一个节点对足够多的系统消息(e.g. watch, Terminated, remote actor deployment, failures of actors supervised by remote parent). 一直没有ACK确认,该节点会被隔离,再也回不来了,之后该节点会过渡到down或者removed. 这里之所以除了心跳还有系统消息,是因为系统还有一种死亡状态是假死:进程在、能ping通、心跳也有响应,就是所有业务操作无限期延迟,所以呢,最稳妥的心跳是业务心跳,也就是这个心跳要把所有正常业务请求操作都能走通才算,当然这只是理想,系统假死的原因比如一个多线程的系统,它里面某些线程死循环了、锁了。
领导者Leader
leader也是通过gossip选定的,这里没有选举过程,只要gossip收敛、所有节点都能明确谁是leader(收敛过程包含leader共商),leader仅仅是一个角色,任何节点都可以作,而且在每一个收敛周期都可能改变。leader的选定很简单,只是具备资格节点顺序表的第一个而已。
leader的职责很简单,就是切换集群成员状态,要么是加入要么是离开,比如把joining状态的成员切换为up上线状态、或者把exiting状态成员切换为removed剔除状态,当前leader的下一步管理操作由当gossip收敛时接收的一个最新集群状态所触发。
领导者也有一点权力,就是当某个节点处于unreachable不可达状态达到配置阀值时间,则令其自动down下线,即所谓的auto-down,但auto-down在与集群特别是持久化共用时是被建议不用的,因为它会导致所谓的精神分裂。

种子节点
种子节点配置为新节点加入时联络的节点机,新节点启动后会向所有种子节点发送“哥来了”消息,然后向第一个应答的种子节点发送join加入命令,种子节点配置对运行当中的集群没有任何影响,它仅仅是帮助新加入节点找到一个联络点用的,有了联络点新节点即可发出加入请求,新加入的节点可以向任意集群节点发出该请求,不只是种子节点。
成员生命周期
节点从joining预备加入状态开始,一旦所有节点都看到新节点预备加入状态(convergence. gossip收敛)则领导者将新节点状态过渡到up :
(joining预备加入——> up上线)
一个节点优雅退出集群的姿势是这样的:它把自己的状态变为leaving预备离开集群,一旦其预备离开状态收敛了(gossip convergence)、则领导者将其状态过渡到exiting离开;一旦其exiting离开状态再次收敛、则领导者将其状态过渡到removed剔除:
(leaving预备离开——>exiting离开 ——>removed剔除)
当一个节点状态是unreachable不可达,则gossip不收敛、leader不能进行任何操作(比如接纳新节点),这种僵持状态要改变则不可达节点的状态必须有所改变:它要么重新过渡到reachable可达,要么过渡到down下线,该节点要重新加入集群其actorSystem必须重启(前面说过,换一个uid)然后从joining预备加入开始重新走一遍加入流程,以全新身份加入。
如果配置了auto-down自动下线,超过不可达时间阀值集群会自动下线一个节点,重启后的新节点/新actorSystem请求加入集群则老的actorSystem会被过渡状态到下线。
配置了auto-down自动下线,最糟的情况是,剩下一堆单节点集群。
上面说过,如果有不可达节点则gossip不收敛,领导者没法进行任何操作。可以打开akka.cluster.allow-weakly-up-members设置(默认打开),允许这种情况下新加入节点可以过渡到WeaklyUp弱上线状态,一旦gossip收敛则领导者将节点状态过渡到up上线。Note that members on the other side of a network partition have no knowledge about the existence of the new members. You should for example not count WeaklyUp members in quorum decisions.
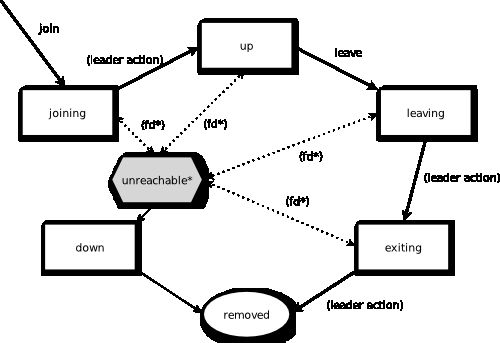
fd*是failure detector失效嗅探者、看来leave是要离开节点机的自主退出。
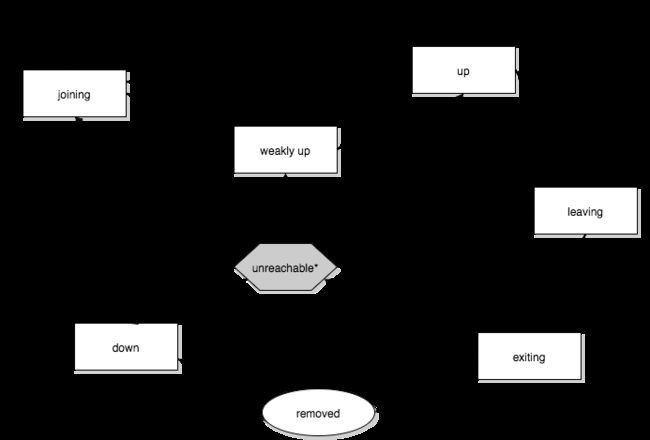
成员状态:
1、joining预备加入:请求加入集群、处于正在加入的暂态
2、weakly up弱上线:网络分区情况下的暂态(only ifakka.cluster.allow-weakly-up-members=on)
3、up在线:正常情况,稳态
4、leaving/exiting离开/退出:正常剔除时所处的状态
5、down正式下线:不再参与集群决策
6、removed永久剔除
用户可以做的操作
1、join加入:将一个节点加入集群,可以是主动显式地加入,也可以是启动时隐式自动进行(配置为启动即加入一个集群)
2、leave离开:优雅告别
3、down正式下线
leader领导者节点职责是切换成员状态:
1、joining预备加入 -> up在线
2、exiting退出 -> removed永久剔除,等等上图所有leader action环节
精神分裂
AK中必须考虑分区(会导致精神分裂)和JVM或硬件机器crash情况的处理,在使用Cluster Singleton 、Cluster Sharding特别是 Akka Persistence情况下这是很关键的。事实上从分布式系统角度来看,分区和crash是没区别的 i.e. 从一个节点的视角看来,有些节点有问题了,但是它无法知道那些节点是永久性crash了呢还是因为网络原因暂时或永久地不可达了呢?暂时性和永久性失效也是没差的。
第三种问题是进程假死unresponsive,e.g. 由于overload过载或full GC造成无响应,这些一样和分区、Crash没差,都表现为不可达、心跳无应答,因为表现上没差别,所以这些故障可以统一处理。
crash时,下一步很可能是立即删除不可达的集群成员节点;分区或无响应时,下一步很可能是等一会,期望这是暂时的问题 . . 总之,分区时我们期望分区的两边能做出一致的决策:哪一边继续运行下去,哪一边应该停掉了。
FD(failure detector)可以发现并广播分区、Crash故障,但是FD也无法辨认区分二者,FD使用周期性心跳做检查,只能检查到unreachable不可达现象,也可能恢复成reachable重新可达,FD自己不足以做出下一步怎么办决策,最直观的方式是达到超时后删除不可达节点,对于crashes和暂时的分区这样就够了,但是对永久性分区不够好,永久分区时,分区的两侧看到的都是对方不可达了,并且主动删除对方,从而形成两个分隔的独立集群,这是开源AK集群的默认行为(provided by the opt-in (off by default) auto-down feature in the OSS version of Akka Cluster.)
如果使用基于auto-down特性的超时检测、结合使用Cluster Singleton 或 Cluster Sharding 这就意味着会出现两个单例、或者出现两个具备同样ID的实体,再加上配合使用了 Akka Persistence 的话,两个实体都会写数据,这回造成致命的事件流数据混乱。
AK集群的默认行为是不会自动删除不可达节点,推荐做法是需要人工介入或者第三方外部监控系统干预,这是合理的方案,但是不便利。AK提供有商业插件解决分区、unresponsive nodes无响应节点、crashed这些问题:Split Brain Resolver......
指定法定多数Quorum策略
static-quorum静态配置指定的法定多数节点机策略:剩余可达节点大于等于配置的quorum法定多数情况下,会下线不可达节点,否则就下线剩余可达节点(就是自己这一边), i.e. quorum法定多数定义了集群可以运行下去的最少节点数。
当集群规模固定时,也就是节点机数量确定时这是个好策略,比如说9台节点机集群,配置:quorum=5. 如果分区为一边4台一边5台,则5台那边将继续运行下去保持集群,4台那边会停止运行并下线。但是5台小集群不能再经受失效了,因为再分区则节点机数量肯定少于5,如果再发生分区则节点机将全部下线。因此,老节点机下线的话注意及时补充新节点。