原文地址
https://www.kaggle.com/mjbahmani/a-comprehensive-ml-workflow-with-python/notebook
原文的目的是利用经典的鸢尾花数据集对常用的机器学习算法进行简单的介绍,内容应该很适合初学者,本文记录自己的重复过程,数据可以在原文处获得
第一部分 Exploratory Data Analysis (EDA)探索性数据分析
-
1.1 简单的统计描述
import pandas as pd
dataset = pd.read_csv("Iris.csv")
type(dataset)
print(dataset.shape)
返回数据的维度,使用到的鸢尾花数据集是150行6列
print(dataset.info())
info()可以得到数据集的一些基本信息
dataset["Species"].unique()
dataset["Species"].value_counts()
这两个函数可能会用到的比较多,unique()用来统计一组包含重复的数据集中都有哪些数据,value_counts()用来统计每个数据出现了多少次,以前自己解决类似的问题会使用R语言的table()函数,简单的小例子说明使用方法
a_dict = {}
a_dict["yan"] = ["A","A","A","B","B","C","C","D"]
df = pd.DataFrame(a_dict)
df["yan"].unique()
df["yan"].value_counts()
dataset.head(5)
dataset.tail(5)
dataset.sample(5)
dataset.describe()
dataset.isnull().sum()
dataset.groupby("Species").count()
dataset.columns
dataset[dataset['SepalLengthCm']>7.2]
head查看前5行数据;tail查看后5 行数据;sample随机抽取行数据;describe()获取每列数据的统计信息,包括数据的个数,平均值,方差,最大值,最小值,分位数等;isnull().sum()用来统计每列数据中的缺失值总数;groupby()函数的作用自己还是不太明白;columns产看列名;dataset[dataset['SepalLengthCm']>7.2]筛选符合特定条件的数据
-
1.2 数据可视化
散点图
散点图可以用来探索两个数值型变量之间可能存在的某种关系
import seaborn as sns
import matplotlib.pyplot as plt
sns.FaceGrid(dataset,hue="Species",size=5).map(plt.scatter,"SepalLengthCm","SepalWidthCm").add.legend()
plt.show()

这段语句的作用自己暂时还没有看明白,不过确实感觉到seaborn的可视化功能非常强大,而且默认的配色感觉很漂亮抽时间好好学习一下
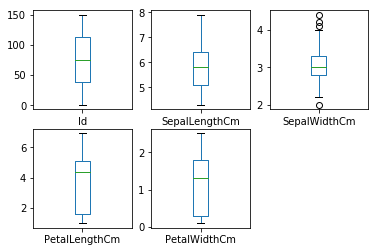
箱线图
线形图用来描述一组数据的分布,大部分人的做法是采用柱形图添加误差线的方法,不过箱线图看起来可能会更加直观
dataset.plot(kind='box', subplots=True, layout=(2,3), sharex=False, sharey=False)
plt.show()
sns.boxplot(x="Species", y="PetalLengthCm", data=dataset )
plt.show()
ax= sns.boxplot(x="Species", y="PetalLengthCm", data=dataset)
ax= sns.stripplot(x="Species", y="PetalLengthCm", data=dataset, jitter=True, edgecolor="gray")
plt.show()


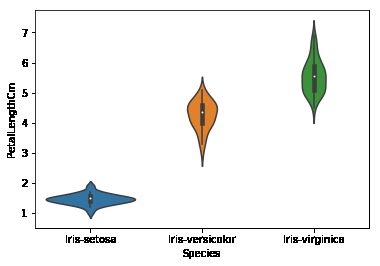
小提琴图
小提琴图自己的理解就是箱线图的另一种形式
sns.violinplot(data=dataset,x="Species", y="PetalLengthCm")
plt.show()
柱形图
dataset.hist(figsize=(15,20))
plt.figure()
plt.show()

Multivariate Plots
(这个自己不知道如何来翻译,就是将一组中两两之间绘制散点图)
pd.plotting.scatter_matrix(dataset,figsize=(10,10))
plt.figure()
plt.show()
这里面plt.figure()语句放到这里暂时没有明白是什么作用

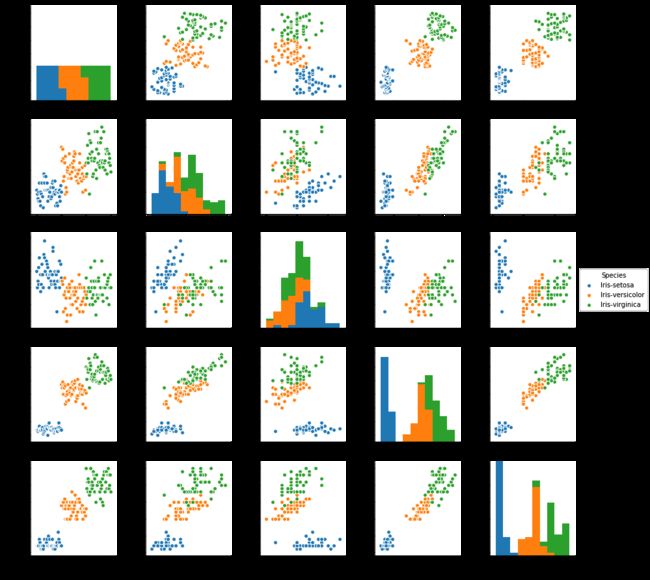
pairplot
这个和上面的Multivariate plots表达的意思应该差不多
sns.pairplot(dataset, hue="Species")
plt.show()
sns.pairplot(dataset, hue="Species",diag_kind="kde")
plt.show()

今天先重复到这里,未完待续......(20180928)
更新(20180930)
kdeplot
kdeplot自己也不知道是什么意思,原文给出的英文解释是 seaborn's kdeplot, plots univarite or bivarite density estimates,直面的意思是画单变量或者双变量的密度估计,根据结果看kdeplot的概率密度函数图
sns.FacetGrid(dataset, hue="Species", size=5).map(sns.kdeplot, "PetalLengthCm").add_legend()
plt.show()

根据这图10可以看出花瓣长度这个变量是符合正态分布的
热图
plt.figure(figsize=(7,4))
sns.heatmap(dataset.corr(),annot=True,cmap='cubehelix_r')
plt.show()

热图展示的是各变量之间的相关系数
原文还分别展示了joinplot, andrews_curves, radviz;这三幅图自己都没有明白是什么意思,疑问留在这里