作者:xiaoyu微信公众号:Python数据科学
pandas有些功能很逆天,但却鲜为人知,本篇给大家盘点一下。
一、ACCESSOR
pandas有一种功能非常强大的方法,它就是accessor,可以将它理解为一种属性接口,通过它可以获得额外的方法。其实这样说还是很笼统,下面我们通过代码和实例来理解一下。
>>> pd.Series._accessors
{'cat', 'str', 'dt'}对于Series数据结构使用_accessors方法,可以得到了3个对象:cat,str,dt。
-
.cat:用于分类数据(Categorical data) -
.str:用于字符数据(String Object data) -
.dt:用于时间数据(datetime-like data)
下面我们依次看一下这三个对象是如何使用的。
str对象的使用
Series数据类型:str字符串
定义一个Series序列
>>> addr = pd.Series([
... 'Washington, D.C. 20003',
... 'Brooklyn, NY 11211-1755',
... 'Omaha, NE 68154',
... 'Pittsburgh, PA 15211'
... ])
>>> addr.str.upper()
0 WASHINGTON, D.C. 20003
1 BROOKLYN, NY 11211-1755
2 OMAHA, NE 68154
3 PITTSBURGH, PA 15211
dtype: object
>>> addr.str.count(r'\d')
0 5
1 9
2 5
3 5
dtype: int64关于以上str对象的2个方法说明:
-
Series.str.upper:将Series中所有字符串变为大写 -
Series.str.count:对Series中所有字符串的个数进行计数
其实不难发现,该用法的使用与Python中字符串的操作很相似。没错,在pandas中你一样可以这样简单的操作,而不同的是你操作的是一整列的字符串数据。仍然基于以上数据集,再看它的另一个操作:
>>> regex = (r'(?P[A-Za-z ]+), ' # 一个或更多字母
... r'(?P[A-Z]{2}) ' # 两个大写字母
... r'(?P\d{5}(?:-\d{4})?)') # 可选的4个延伸数字
...
>>> addr.str.replace('.', '').str.extract(regex)
city state zip
0 Washington DC 20003
1 Brooklyn NY 11211-1755
2 Omaha NE 68154
3 Pittsburgh PA 15211 关于以上str对象的2个方法说明:
-
Series.str.replace:将Series中指定字符串替换 -
Series.str.extract:通过正则表达式提取字符串中的数据信息
这个用法就有点复杂了,因为很明显看到,这是一个链式的用法。通过replace将 " . " 替换为"",即为空,紧接着又使用了3个正则表达式(分别对应city,state,zip)通过extract对数据进行了提取,并由原来的Series数据结构变为了DataFrame数据结构。
当然,除了以上用法外,常用的属性和方法还有.rstrip,.contains,split等,我们通过下面代码查看一下str属性的完整列表:
>>> [i for i in dir(pd.Series.str) if not i.startswith('_')]
['capitalize',
'cat',
'center',
'contains',
'count',
'decode',
'encode',
'endswith',
'extract',
'extractall',
'find',
'findall',
'get',
'get_dummies',
'index',
'isalnum',
'isalpha',
'isdecimal',
'isdigit',
'islower',
'isnumeric',
'isspace',
'istitle',
'isupper',
'join',
'len',
'ljust',
'lower',
'lstrip',
'match',
'normalize',
'pad',
'partition',
'repeat',
'replace',
'rfind',
'rindex',
'rjust',
'rpartition',
'rsplit',
'rstrip',
'slice',
'slice_replace',
'split',
'startswith',
'strip',
'swapcase',
'title',
'translate',
'upper',
'wrap',
'zfill']属性有很多,对于具体的用法,如果感兴趣可以自己进行摸索练习。
dt对象的使用
Series数据类型:datetime
因为数据需要datetime类型,所以下面使用pandas的date_range()生成了一组日期datetime演示如何进行dt对象操作。
>>> daterng = pd.Series(pd.date_range('2017', periods=9, freq='Q'))
>>> daterng
0 2017-03-31
1 2017-06-30
2 2017-09-30
3 2017-12-31
4 2018-03-31
5 2018-06-30
6 2018-09-30
7 2018-12-31
8 2019-03-31
dtype: datetime64[ns]
>>> daterng.dt.day_name()
0 Friday
1 Friday
2 Saturday
3 Sunday
4 Saturday
5 Saturday
6 Sunday
7 Monday
8 Sunday
dtype: object
>>> # 查看下半年
>>> daterng\[daterng.dt.quarter > 2]
2 2017-09-30
3 2017-12-31
6 2018-09-30
7 2018-12-31
dtype: datetime64[ns]
>>> daterng[daterng.dt.is_year_end]
3 2017-12-31
7 2018-12-31
dtype: datetime64[ns]以上关于dt的3种方法说明:
-
Series.dt.day_name():从日期判断出所处星期数 -
Series.dt.quarter:从日期判断所处季节 -
Series.dt.is_year_end:从日期判断是否处在年底
其它方法也都是基于datetime的一些变换,并通过变换来查看具体微观或者宏观日期。
cat对象的使用
Series数据类型:Category
在说cat对象的使用前,先说一下Category这个数据类型,它的作用很强大。虽然我们没有经常性的在内存中运行上g的数据,但是我们也总会遇到执行几行代码会等待很久的情况。使用Category数据的一个好处就是:可以很好的节省在时间和空间的消耗。下面我们通过几个实例来学习一下。
>>> colors = pd.Series([
... 'periwinkle',
... 'mint green',
... 'burnt orange',
... 'periwinkle',
... 'burnt orange',
... 'rose',
... 'rose',
... 'mint green',
... 'rose',
... 'navy'
... ])
...
>>> import sys
>>> colors.apply(sys.getsizeof)
0 59
1 59
2 61
3 59
4 61
5 53
6 53
7 59
8 53
9 53
dtype: int64上面我们通过使用sys.getsizeof来显示内存占用的情况,数字代表字节数。还有另一种计算内容占用的方法:memory\_usage(),后面会使用。
现在我们将上面colors的不重复值映射为一组整数,然后再看一下占用的内存。
>>> mapper = {v: k for k, v in enumerate(colors.unique())}
>>> mapper
{'periwinkle': 0, 'mint green': 1, 'burnt orange': 2, 'rose': 3, 'navy': 4}
>>> as_int = colors.map(mapper)
>>> as_int
0 0
1 1
2 2
3 0
4 2
5 3
6 3
7 1
8 3
9 4
dtype: int64
>>> as_int.apply(sys.getsizeof)
0 24
1 28
2 28
3 24
4 28
5 28
6 28
7 28
8 28
9 28
dtype: int64
注:对于以上的整数值映射也可以使用更简单的
pd.factorize()方法代替。
我们发现上面所占用的内存是使用object类型时的一半。其实,这种情况就类似于Category data类型内部的原理。
内存占用区别:Categorical所占用的内存与Categorical分类的数量和数据的长度成正比,相反,object所占用的内存则是一个常数乘以数据的长度。
下面是object内存使用和category内存使用的情况对比。
>>> colors.memory_usage(index=False, deep=True)
650
>>> colors.astype('category').memory_usage(index=False, deep=True)
495上面结果是使用object和Category两种情况下内存的占用情况。我们发现效果并没有我们想象中的那么好。但是注意Category内存是成比例的,如果数据集的数据量很大,但不重复分类(unique)值很少的情况下,那么Category的内存占用可以节省达到10倍以上,比如下面数据量增大的情况:
>>> manycolors = colors.repeat(10)
>>> len(manycolors)/manycolors.nunique()
20.0
>>> manycolors.memory_usage(index=False, deep=True)
6500
>>> manycolors.astype('category').memory_usage(index=False, deep=True)
585可以看到,在数据量增加10倍以后,使用Category所占内容节省了10倍以上。
除了占用内存节省外,另一个额外的好处是计算效率有了很大的提升。因为对于Category类型的Series,str字符的操作发生在.cat.categories的非重复值上,而并非原Series上的所有元素上。也就是说对于每个非重复值都只做一次操作,然后再向与非重复值同类的值映射过去。
对于Category的数据类型,可以使用accessor的cat对象,以及相应的属性和方法来操作Category数据。
>>> ccolors = colors.astype('category')
>>> ccolors.cat.categories
Index(['burnt orange', 'mint green', 'navy', 'periwinkle', 'rose'], dtype='object')实际上,对于开始的整数类型映射,可以先通过reorder_categories进行重新排序,然后再使用cat.codes来实现对整数的映射,来达到同样的效果。
>>> ccolors.cat.reorder_categories(mapper).cat.codes
0 0
1 1
2 2
3 0
4 2
5 3
6 3
7 1
8 3
9 4
dtype: int8dtype类型是Numpy的int8(-127~128)。可以看出以上只需要一个单字节就可以在内存中包含所有的值。我们开始的做法默认使用了int64类型,然而通过pandas的使用可以很智能的将Category数据类型变为最小的类型。
让我们来看一下cat还有什么其它的属性和方法可以使用。下面cat的这些属性基本都是关于查看和操作Category数据类型的。
>>> [i for i in dir(ccolors.cat) if not i.startswith('_')]
['add_categories',
'as_ordered',
'as_unordered',
'categories',
'codes',
'ordered',
'remove_categories',
'remove_unused\_categories',
'rename_categories',
'reorder_categories',
'set_categories']但是Category数据的使用不是很灵活。例如,插入一个之前没有的值,首先需要将这个值添加到.categories的容器中,然后再添加值。
>>> ccolors.iloc[5] = 'a new color'
# ...
ValueError: Cannot setitem on a Categorical with a new category,
set the categories first
>>> ccolors = ccolors.cat.add\_categories(['a new color'])
>>> ccolors.iloc[5] = 'a new color' 如果你想设置值或重塑数据,而非进行新的运算操作,那么Category类型不是那么有用。
二、从clipboard剪切板载入数据
当我们的数据存在excel表里,或者其它的IDE编辑器中的时候,我们想要通过pandas载入数据。我们通常的做法是先保存再载入,其实这样做起来十分繁琐。一个简单的方法就是使用pd.read\_clipboard() 直接从电脑的剪切板缓存区中提取数据。
这样我们就可以直接将结构数据转变为DataFrame或者Series了。excel表中数据是这样的:
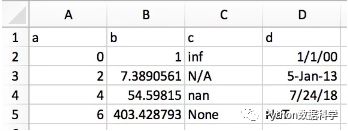
在纯文本文件中,比如txt文件,是这样的:
a b c d
0 1 inf 1/1/00
2 7.389056099 N/A 5-Jan-13
4 54.59815003 nan 7/24/18
6 403.4287935 None NaT将上面excel或者txt中的数据选中然后复制,然后使用pandas的read_clipboard()即可完成到DataFrame的转换。parse_dates参数设置为"d",可以自动识别日期,并调整为xxxx-xx-xx的格式。
>>> df = pd.read_clipboard(na_values=[None], parse_dates=['d'])
>>> df
a b c d
0 0 1.0000 inf 2000-01-01
1 2 7.3891 NaN 2013-01-05
2 4 54.5982 NaN 2018-07-24
3 6 403.4288 NaN NaT
>>> df.dtypes
a int64
b float64
c float64
d datetime64[ns]
dtype: object三、将pandas对象转换为“压缩”格式
在pandas中,我们可以直接将objects打包成为gzip, bz2, zip, or xz等压缩格式,而不必将没压缩的文件放在内存中然后进行转化。来看一个例子如何使用:
>>> abalone = pd.read_csv(url, usecols=[0, 1, 2, 3, 4, 8], names=cols)
>>> abalone
sex length diam height weight rings
0 M 0.455 0.365 0.095 0.5140 15
1 M 0.350 0.265 0.090 0.2255 7
2 F 0.530 0.420 0.135 0.6770 9
3 M 0.440 0.365 0.125 0.5160 10
4 I 0.330 0.255 0.080 0.2050 7
5 I 0.425 0.300 0.095 0.3515 8
6 F 0.530 0.415 0.150 0.7775 20
... .. ... ... ... ... ...
4170 M 0.550 0.430 0.130 0.8395 10
4171 M 0.560 0.430 0.155 0.8675 8
4172 F 0.565 0.450 0.165 0.8870 11
4173 M 0.590 0.440 0.135 0.9660 10
4174 M 0.600 0.475 0.205 1.1760 9
4175 F 0.625 0.485 0.150 1.0945 10
4176 M 0.710 0.555 0.195 1.9485 12导入文件,读取并存为abalone(DataFrame结构)。当我们要存为压缩的时候,简单的使用 to_json()即可轻松完成转化过程。下面通过设置相应参数将abalone存为了.gz格式的压缩文件。
abalone.to_json('df.json.gz', orient='records',
lines=True, compression='gzip')如果我们想知道储存压缩文件的大小,可以通过内置模块os.path,使用getsize方法来查看文件的字节数。下面是两种格式储存文件的大小对比。
>>> import os.path
>>> abalone.to_json('df.json', orient='records', lines=True)
>>> os.path.getsize('df.json') / os.path.getsize('df.json.gz')
11.603035760226396四、使用"测试模块"制作伪数据
在pandas中,有一个测试模块可以帮助我们生成半真实(伪数据),并进行测试,它就是util.testing。下面同我们通过一个简单的例子看一下如何生成数据测试:
>>> import pandas.util.testing as tm
>>> tm.N, tm.K = 15, 3 # 默认的行和列
>>> import numpy as np
>>> np.random.seed(444)
>>> tm.makeTimeDataFrame(freq='M').head()
A B C
2000-01-31 0.3574 -0.8804 0.2669
2000-02-29 0.3775 0.1526 -0.4803
2000-03-31 1.3823 0.2503 0.3008
2000-04-30 1.1755 0.0785 -0.1791
2000-05-31 -0.9393 -0.9039 1.1837
>>> tm.makeDataFrame().head()
A B C
nTLGGTiRHF -0.6228 0.6459 0.1251
WPBRn9jtsR -0.3187 -0.8091 1.1501
7B3wWfvuDA -1.9872 -1.0795 0.2987
yJ0BTjehH1 0.8802 0.7403 -1.2154
0luaYUYvy1 -0.9320 1.2912 -0.2907上面简单的使用了
makeTimeDataFrame 和 makeDataFrame 分别生成了一组时间数据和DataFrame的数据。但这只是其中的两个用法,关于testing中的方法有大概30多个,如果你想全部了解,可以通过查看dir获得:
>>> [i for i in dir(tm) if i.startswith('make')]
['makeBoolIndex',
'makeCategoricalIndex',
'makeCustomDataframe',
'makeCustomIndex',
# ...,
'makeTimeSeries',
'makeTimedeltaIndex',
'makeUIntIndex',
'makeUnicodeIndex']五、从列项中创建DatetimeIndex
也许我们有的时候会遇到这样的情形(为了说明这种情情况,我使用了product进行交叉迭代的创建了一组关于时间的数据):
>>> from itertools import product
>>> datecols = ['year', 'month', 'day']
>>> df = pd.DataFrame(list(product([2017, 2016], [1, 2], [1, 2, 3])),
... columns=datecols)
>>> df['data'] = np.random.randn(len(df))
>>> df
year month day data
0 2017 1 1 -0.0767
1 2017 1 2 -1.2798
2 2017 1 3 0.4032
3 2017 2 1 1.2377
4 2017 2 2 -0.2060
5 2017 2 3 0.6187
6 2016 1 1 2.3786
7 2016 1 2 -0.4730
8 2016 1 3 -2.1505
9 2016 2 1 -0.6340
10 2016 2 2 0.7964
11 2016 2 3 0.0005明显看到,列项中有year,month,day,它们分别在各个列中,而并非是一个完整日期。那么如何从这些列中将它们组合在一起并设置为新的index呢?
通过to_datetime的使用,我们就可以直接将年月日组合为一个完整的日期,然后赋给索引。代码如下:
>>> df.index = pd.to_datetime(df[datecols])
>>> df.head()
year month day data
2017-01-01 2017 1 1 -0.0767
2017-01-02 2017 1 2 -1.2798
2017-01-03 2017 1 3 0.4032
2017-02-01 2017 2 1 1.2377
2017-02-02 2017 2 2 -0.2060当然,你可以选择将原有的年月日列移除,只保留data数据列,然后squeeze转换为Series结构。
>>> df = df.drop(datecols, axis=1).squeeze()
>>> df.head()
2017-01-01 -0.0767
2017-01-02 -1.2798
2017-01-03 0.4032
2017-02-01 1.2377
2017-02-02 -0.2060
Name: data, dtype: float64
>>> df.index.dtype_str
'datetime64[ns]欢迎关注微信公众号Python数据科学,分享机器学习、数据挖掘、Python数据分析、爬虫等干货,同时可免费获得百G学习资源,期待我们一起学习。