其实超融合这一块,放在云计算IT基础设施里面,不算是完全合适。你说它是分布式存储,但是它同时又是硬件服务器与存储;你说它算硬件,但是它又离不开分布式存储软件。
一、超融合架构
传统的IT基础设施架构,主要分为网络、计算、存储三层架构。但随着云计算与分布式存储技术的发展以及x86服务器的标准化,逐渐出现了一种将计算、存储节点融合在一起的架构--超融合架构。超融合将三层的IT基础设施架构缩小变成了两层。
2019年11月的Gartner超融合产品魔力象限中,领导者象限有5家:Nutanix、DELL、VMware、CISCO、HPE。(其中DELL vxRail一体机里面用的分布式存储软件也是VMware的VSAN,而VMware提供的则是VSAN纯软件的解决方案)
Nutanix能够成为超融合领导者中的领导者,自然是经过市场的充分验证,得到市场的认可。而且由于其公开资料(Nutanix 圣经)比较齐备,因此我们可以通过Nutanix一窥超融合的究竟。
二、关于Nutanix的起源、背景、设计理念等:
这边就不搬运了,可以直接搜索引擎搜索“Nutanix圣经”或“Nutanix-Bible”,可以找到相应的官方文档。
三、Nutanix的技术特点(以下部分为个人根据圣经与实际测试结果归纳,与圣经内容有部分重复):
一)逻辑架构:

引用自NUTANIX圣经-“Nutanix解决方案是一个融合了存储和计算资源于一体的解决方案。该方案是一个软硬件一体化平台,在2U空间中提供2或4个节点。
每个节点运行着hypervisor(支持ESXi, KVM, Hyper-V)和Nutanix控制器虚机(CVM)。Nutanix CVM中运行着Nutanix核心软件,服务于所有虚机和虚机对应的I/O操作。
得益于Intel VT-d(VM直接通路)技术,对于运行着VMware vSphere的Nutanix单元,SCSI控制(管理SSD和HDD设备)被直接传递到CVM。”
个人总结:从以上官方文档可知,2U的空间可以安装2~4个Nutanix节点(每个节点相当于1台物理服务器),所以设备装机密度非常高。每个节点都安装着虚拟化软件,并且在虚拟化层之上再运行着一台Nutanix的控制虚机(CVM),该虚机主要负责不同的Nutanix节点之间控制平面的通信。单个节点中配置有SSD硬盘与HDD硬盘,替代磁盘阵列作为存储使用,单个节点有独立的CPU与内存,作为计算节点使用。
二)Nutanix的数据读写原理
1、基础架构
以3个Nutanix节点为例,每个节点安装有Hypervisor,在Hypervisor之上运行着客户虚拟机,并且每个节点有一台Nutanix控制器虚机Controller VM,配置有2块SSD与4块HDD,通过SCSI Controller作读写。
2、数据保护
Nuntanix与传统磁盘阵列通过Raid、LVM等方式作数据保护不同,而是与一般的分布式存储一样,通过为数据建立副本,拷贝到其他Nutanix节点存放,来对数据进行保护,Nutanix将副本的数量称作RF(一般RF为2~3)。
当客户虚机写入数据“见图上1a)流程”,数据先写入到本地Nutanix节点的SSD硬盘中划分出来的OpLog逻辑区域(相当于Cache的作用),然后执行“1b)”流程,本地节点的CVM将数据从本地的SSD的OpLog拷贝到其他节点的SSD的OpLog,拷贝份数视RF而定。当其他节点CVM确定数据写入完成,会执行“1c”流程,给出应答写入完成。通过数据副本实现对数据的保护。
数据从SSD中的OpLog写入到SSD以及HDD的Extent Store区域,是按照一定的规则异步进行的,具体详见下面的部分。
3、存储分层
Nutanix数据写入以本地落盘为主要写入原则(核心原则)。
当客户虚机写入数据是,优先考虑写入本地SSD(如果SSD已用容量未达到阀值),如果本地SSD满了,会将本地SSD的最冷的数据,迁移到集群中其他节点的SSD,腾出本地SSD的空间,写入数据。本地落盘的原则,是为了尽量提高虚机访问存储数据的速度,使本地虚机不需要跨节点访问存储数据。(这点应该是与VSAN与其他分布式文件系统最大原理性区别)
当整个集群的SSD已用容量达到阀值(一般是75%),才会将每个节点的SSD数据迁移到该节点的HDD硬盘中。
SSD迁移数据到HDD,并非将所有数据全部迁移到HDD,而是对数据进行访问度冷热的排序,并且将访问较少的冷数据优先迁移到HDD硬盘中。
如SSD容量达到95%的利用率,则迁移20%的冷数据到HDD;如SSD容量达到80%,则默认迁移15%的冷数据到HDD。
4、数据读取与迁移
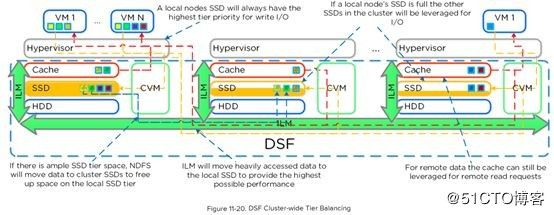
Nutanix圣经引用-“I/O和数据的本地化(data locality),是Nutanix超融合平台强劲性能的关键所在。所有的读、写I/O请求都藉由VM的所在节点的本地CVM所响应处理。所以基本上不会出现虚机在一个节点,而需要访问的存储数据在另外一个物理节点的情况,VM的数据都将由本地的CVM及其所管理的本地磁盘提供服务。
当VM由一个节点迁移至另一个节点时(或者发生HA切换),此VM的数据又将由现在所在节点中的本地CVM提供服务。当读取旧的数据(存储在之前节点的CVM中)时,I/O请求将通过本地CVM转发至远端CVM。所有的写I/O都将在本地CVM中完成。DFS检测到I/O请求落在其他节点时,将在后台自动将数据移动到本地节点中,从而让所有的读I/O由本地提供服务。数据仅在被读取到才进行搬迁,进而避免过大的网络压力。”
个人总结:即一般虚机读写数据都是读本地节点的硬盘,如果本地节点硬盘没有该数据,会从其他节点先拷贝过来本地节点硬盘,再为本地虚机提供访问,而不是虚机直接访问其他节点。即要贯彻本地落盘的核心思想。
5、Nutanix解决方案的优缺点
Nutanix方案优点:
1) 本地落盘策略,确保虚机访问存储速度:虚机写入的数据都在本物理节点的磁盘上,避免跨节点存储访问,确保访问速度,减轻网络压力。
2) 采用SSD磁盘作为数据缓存,大幅提升IO性能:
表格数据引入原文:[SATA,SAS,SSD 读写性能测试结果] (侵删)
(侵删)
见上表数据,从随机的读写来看,SSD的IO及带宽性能比SATA的性能提升了约1000倍。而结合Nutanix的本地落盘策略,虚机数据写入,仅有本地的2块SSD硬盘作为数据缓存负责写入数据。
但由于单块SSD硬盘的IO比传统阵列的SATA高出1000倍,IO性能大幅提升。(相当于要超过2000块SATA硬盘做Raid,才能提供近似的IO性能)。
3)永远优先写入SSD,确保高IO性能
数据写入HDD不参与,即使本地SSD容量满了会将冷数据迁移到集群其他节点SSD,然后还是SSD进行读写,确保高IO。后续异步将SSD冷数据迁移到HDD。
4)数据冷热分层存储
冷数据存放在HDD,热数据保留在SSD,确保热点数据高IO读取。
5)设备密度高,节省机房机架空间
2U可以配置4个节点,包含了存储与计算,比以往机架式/刀片服务器与磁盘阵列的解决方案节省了大量的空间。
Nutanix方案缺点:
1)本地落盘及SSD缓存方案确保了高IO,但是硬盘的带宽得不到保证。
传统磁盘阵列,多块SATA/SAS硬盘加入Raid组,数据写入的时候,将文件拆分为多个block,分布到各个硬盘中,同个Raid组的硬盘同时参与该文件的block的读写。通过多块硬盘的并行读写,从而提升IO与带宽性能。
而Nutanix的解决方案中,单个文件的读写遵循本地落盘的策略,因此不再对文件拆分到多块硬盘进行并行读写,而只有本地节点的SSD硬盘会对该文件进行写入。
虽然SSD硬盘的IO与带宽都是SATA/SAS的数百上千倍,但是SSD对比SATA/SAS硬盘在带宽上面只有2~3倍的速率提升,而传统Raid的方式,多块硬盘并行读写,虽然IO比不上SSD,但是带宽则比单块/两块SSD带宽高出很多。
因此Nutanix的解决方案适合用于高IO需求的业务类型,但是因为它的读写原理,则决定了它不合适低IO、高带宽的业务类型。
三)行业竞争对手对比:
VMWARE EVO RAIL软件包:VMware没有涉足硬件产品,但EVO: RAIL 软件捆绑包可供合格的 EVO: RAIL 合作伙伴使用。合作伙伴转而将硬件与集成的 EVO: RAIL 软件一起出售,并向客户提供所有硬件和软件支持。
而EVO:RAIL的核心,其实就是VSphere虚拟化软件+VSAN软件的打包。
硬件设计方面,基本上与Nutanix的理念一致,2U设备安装4个节点,每个节点有独立的CPU与内存,3块HDD,1块SSD。
但VSAN与Nutanix最大的一个区别,就是不必须完全遵循Nutanix的本地落盘的策略。可以通过设置条带系数,将本地虚机的数据读写设置为横跨多个节点的硬盘,默认条带系数为1,最大可设置为12个,即一个虚机的数据写入,可以同时采用12个节点的SSD硬盘并行读写。
通过这种方式,VSAN可以一定程度的弥补了Nutanix方案不适用于带宽要求高,IO要求低的业务类型的缺点。
但是这种横跨物理节点的访问流量,在虚机数量众多的情况下,肯定会给网络带来压力,网络带宽可能会成为另一个瓶颈。
其次VSAN可以集成在Hypervisor层,而不需要像Nutanix在Hypervisor上面运行一个控制虚机CVM。
再次,Nutanix支持KVM、Hyper-V、ESXI等多种Hypervisor,而VSAN仅支持自家的ESXI。
其他待补充:由于暂时未对VSAN进行实际部署测试,仅停留在对其原理的研究,因此,关于VSAN的部分待后续平台上线测试完成后继续补充。