作者从detector的overfitting at training/quality mismatch at inference问题入手,提出了基于multi-stage的Cascade R-CNN,该网络结构清晰,效果显著,并且能简单移植到其它detector中,带来2-4%的性能提升
论文: Cascade R-CNN: Delving into High Quality Object Detection

- 论文地址: https://arxiv.org/abs/1712.00726
- 代码地址: https://github.com/zhaoweicai/cascade-rcnn
Introduction

目前的目标检测算法大都使用$u=0.5$的IoU阈值来定义正负样本,这是相当宽松的阈值,导致detector产生许多干扰的bndbox。如图(a),许多人们认为大概率是负样本的框其实IoU都大于0.5。因此,论文希望研究出学习能尽量少包含接近负样本的bndbox的detector,如图(b)

论文对不同IoU阈值的regressor和detector进行了实验。从图c可以看出,不同IoU阈值的detector对不同水平的bndbox的优化程度不同,bndbox IoU与detecor的训练阈值越接近,box regress提升越高。而在图d中,detector(u=0.5)在低IoU水平下比detector(u=0.6)表现优异,而在高IoU水平下则反之,而当u=0.7时,由于训练正样本的不足以及推理时输入的样本IoU较低,detector(u=0.7)的整体表现都降低了
综上可以得出以下结论:
- 训练后的detector几乎总能提升Input bndbox的质量
- 单IoU detector对接近其训练IoU阈值的bndbox是最优的
- 单纯地增加训练时的IoU的阈值并不能直接提高detector的质量
因此,论文提出了Cascade R-CNN来解决上面的问题。Cascade R-CNN是一个顺序的多阶段extension,利用前一个阶段的输出进行下一阶段的训练,阶段越往后使用更高的IoU阈值,产生更高质量的bndbox。Cascade R-CNN简单而有效,能直接添加到其它R-CNN型detector中,带来巨大的性能提升(2-4%)
Object Detection

Faster R-CNN
目前经典的two-stage架构如图3(a)。第一阶段是一个提框的子网H0,用于生成初步的bndbox。第二阶段为特定区域处理的检测子网H1,给定bndbox最终的分类分数C和bndbox坐标B
Iterative BBox at inference
有的研究者认为单次的box regress是不足以产生准确的位置信息的,因此需要进行多次迭代来精调bndbox,这就是iterative bounding box regression:
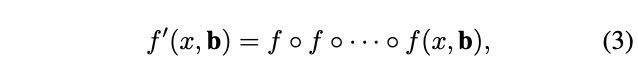
实现如图3(b)所示,所有的head都是一样的,但是这个方法忽略了两个问题:
- 如图1所示,detector(u=0.5)对于所有的高质量的bndbox是次优解,甚至降低了IoU大于0.85的bndbox的准确度
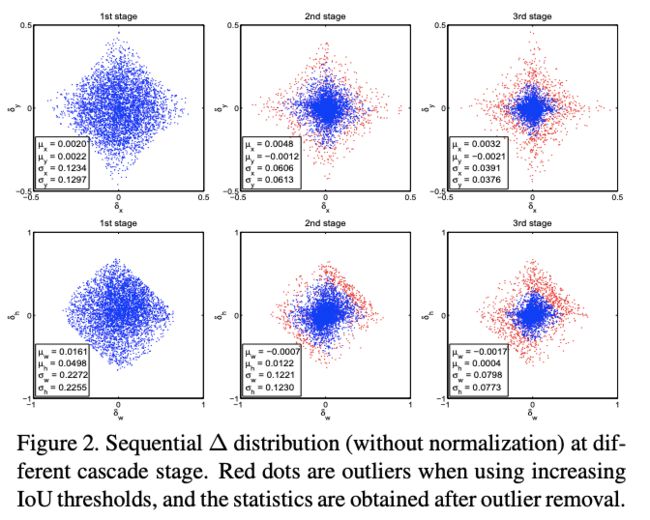
- 图2为bndbox的$(x, y, w, h)$与GT间的差值分布,从图中可以看出,不同阶段的bndbox分布是显著不同的。若regressor对于初始化的分布是最优的,那对于在后面的阶段肯定是次优的
因此,iterative BBox需要大量的手工操作,如box voting,而其结果不是稳定提升的。通常来说,对bndbox进行多于两次相同的regressor是几乎没有收益的
Integral Loss
由于bndbox经常包含目标和一定的背景,因此很难去判定当前bndbox是否正样本
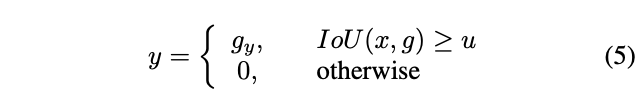
常用的方法是判断其与GT的IoU,当IoU大于阈值时,则赋予其对应GT的label。但是阈值的设定是十分苦难的,当阈值过高时,正样本包含很少的背景,但是会导致难以生成足够多的正样本进行训练,反之,则会导致detecor容易产生close false positives。因此,很难找到一个单独的classifier能一致地对所有IoU的bndbox是最优的

一种尝试的方法是使用一个分类器集合,如图3(c)所示,优化针对各种质量的bndbox的loss。$U={0.5, 0.55, ..., 0.75}$是根据COCO设定IoU阈值合集,按照定义,分类器在推理时再进行组装

这种解决方法存在两个问题:
- 不同的classifer的正样本数量是不一样的,如图4所示,正样本的数量随着u的提高显著下降,这意味着高质量的classifiers容易过拟合
- 在推理时,高质量的classifers需要处理相对低质量的bndbox,而他们对这些bndbox并没有优化
因此,Integral loss在很多IoU水平难以表现出高的准确率。相对于原始的two-stage架构,Integral loss的架构收益相对较小
Cascade R-CNN
Cascaded Bounding Box Regression
由于很难训练一个能应付所有IoU水平的regressor,可以把回归任务分解成一个级联的regression问题,架构如图3(d)所示

T是级联阶段数,每个regressor$f_t$对于当前的级联输入都是最优的,随着阶段的深入,bndbox在不断的提升。
cascade regression与iterative BBox有以下区别:
- iteravtive BBox是后处理的方法,而cascaded regression是能够改变bndbox分布的重采样过程
- cascaded regression在训练和推理时是一致的,不存在区别
- cascaded regression的多个regressor对于对应阶段的输入分布是最优的,而iterative BBox仅对初始分布是最优的

Bndbox在回归时,为了对scale和location有不变性,将对坐标的学习转移到对坐标差值的学习。由于坐标插值通常较小,因此将其进行归一化$\delta'=(\delta_x-\mu_x)/\sigma$,以权衡定位与分类的loss。Cascade R-CNN在每一个stage结束后,都会马上进行计算这些均值/方差
Cascaded Detection
产生Cascade R-CNN的启发点主要有两个:
- 如图4的1st stage图所示,初始的bndbox分布大多落在低质量的区域,这对于高质量classifiers来说是无效的学习。
- 在图1(c)实验中可以看到,所有的曲线都高于对角线,即regressor都倾向于能够提升bndbox的IoU。
因此,以集合$(x_i, b_i)$作为开始,通过级联regress来产生高IoU的集合$(x'_i, b'_i)$。如图4所示,这种方法能在提升样本整体IoU水平的同时,使得样本的总数大致维持在一个水平,这会带来两个好处:
- 不会存在某个阈值的regressor过拟合
- 高阶段的detector对于高IoU阈值是最优的
从图2可以看出,随着阶段的深入,一些离群点会被过滤,这保证了特定阈值的detector的训练

在每一个阶段t,都独立一个对阈值$u_t(u_t > u_{t-1})$最优的classifier $h_t$和regressor$f_t$,$bt=f_{t-1}(x{t-1}, b{t-1})$是上一阶段的输出,$\lambda=1$是权重因子,$[yt\ge1]$是指示函数,表示背景的$L_{loc}$不加入计算。与integral loss不同,公式8保证了顺序地训练detectors来逐步提高bndbox质量。在推理时,bndbox的质量是顺序提高的,高质量的detectors只需要面对高质量的bndbox。
Experiment
Implementation Details
部分实验设置如下:
- 所有regressor都带分类,每一个cascade stage为相同的架构
- 共4个stage,一个为RPN,其余为$U={0.5, 0.6, 0.7}$的检测器。第一阶段检测器为正常的RPN,其余阶段使用上一阶段的输出作为输入
- 使用垂直翻转的数据增强手段以及单一图片输入尺寸
Quality Mismatch

图5展示了3个独立训练的detector的AP曲线,detector的IoU阈值分别为$U={0.5, 0.6, 0.7}$,detector(u=0.5)在低IoU水平表现最好,detector(u=0.6)在高IoU水平表现最好,而detector(u=0.7)则整体表现较差。为了进一步解释图(a)的结果,论文添加GT到proposal集合得到了图(b)的结果,所有的detector的AP都提升,而detector(u=0.7)提升最大,且几乎全局最优。因此,可以得出以下两个结论:
- $u=0.5$不是一个好的选择,仅限于低质量bndbox
- 高质量的detector高质量的bndbox输入
此外,图5(a)对比了以Cascade R-CNN的stage输出作为输入时detector的表现。当提升了输入的bndbox质量后,detector得到了明显的提升
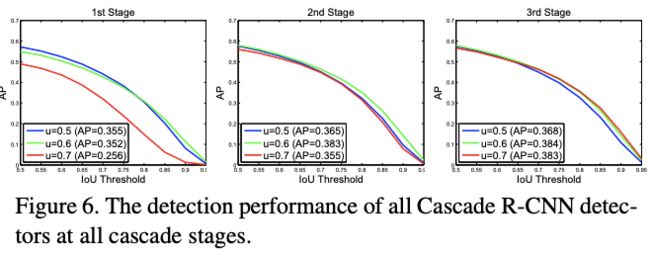
图6对比了各cascade detector在各stage上的表现。提高输入的质量后,各detector都得到了收益,如detector(u=0.7)从原来的AP=0.256提升为AP=0.383。此外,将图6和图5(a)对比可以得出,cascade联合训练的detector比单独训练的detector精度要高
Comparison with Iterative BBox and Integral Loss
论文对比Cascade R-CNN与iterative BBox和integral loss detector,Iterative BBox连续使用3次FPN+进行实现,而integral loss detector则使用$U={0.5, 0.6, 0.7}$的classification head

Localization: 如图7(a),单检测器的降低了高IoU输入的精度,当regressor对bndbox回归次数增加时,下降越明显。相反,cascade regressor则表现越来越好,几乎全面领先iterative BBox
Integral Loss: 图7(b)展示了integral loss各classifier以及集成后的准确率(使用同一个regressor),classifier(u=0.6)表现最好,而集成的classifier则没有任何收益

Table1展示了三种优化方法与Baseline的准确率具体数值,在低IoU水平时,Cascade R-CNN的收益较少,而在高水平时收益十分显著
Ablation Experiments
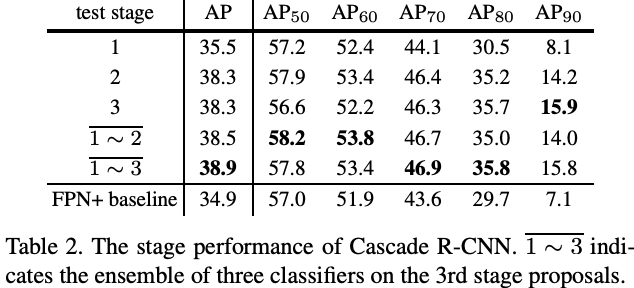
Stage-wise Comparison: Table2 总结了stage性能表现。由于multi-stage multi-task训练,1st stage性能已经有很好地提升,2rd stage和3rd stage则都维持在一个相对高的水平,集成的classifier性能最好

IoU Thresholds: Cascade R-CNN的所有head均使用u=0.5阈值进行初始化,在后面的训练中才使用对应的bndbox进行训练。从Table3的第一行看出,cascade能够提升baseline的性能,这表明使用不同的stage优化不同的输入分布的重要性。第二行表明,随着IoU阈值的提升,detector能产生更多高质量的bndbox,减少close false positive的产生
Regression Statistics: 渐进式地更新bndbox坐标差值的统计信息,从Table3可以看出,网络的训练对这些信息的统计不是十分敏感
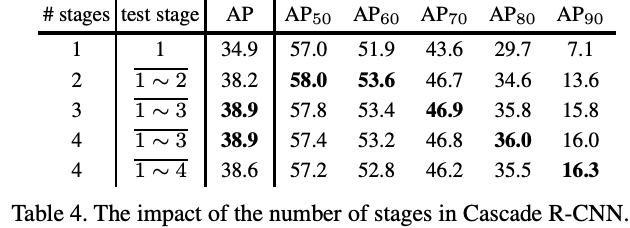
Number of Stages: Table4总结了stage数量对性能的影响。two-stage能显著地提升baseline的效果,而加入4th stage(u=0.75)后虽然高IoU水平的性能提升了,但却令整体性能有所下降。因此,three-stage是最好的折中方案
Comparison with the state-of-the-art
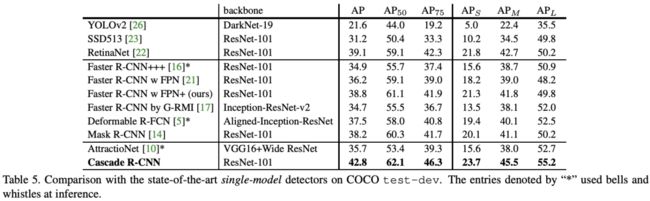
Table5对比了Cascade R-CNN与主流的one-stage detector和two-stage detector的性能,从表格可以看出,Cascade R-CNN的性能提升是十分明显的,各方面都优秀
Generalization Capacity
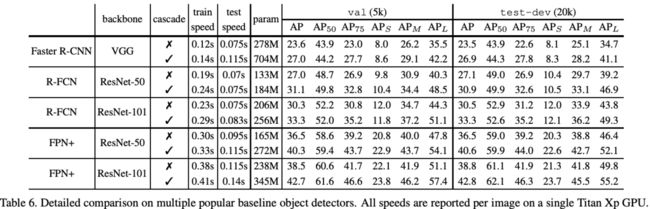
Detection Performance: 在所有的baseline detector上,使用Cascade R-CNN均有2~4%的提升,这表明Cascade R-CNN能广泛适用于多种检测器架构中
Parameter and Timing: Cascade R-CNN的参数量增加跟stage数量有关,与baseline的detector head呈线性关系。此外,由于detector head的计算耗时相对于RPN是非常小的,Cascade R-CNN的额外计算开销比较小
Conclusion
论文提出一个高质量的多阶段目标检测架构Cascade R-CNN,这个架构解决了训练时的过拟合问题以及推理时的IoU mismatch问题。Cascade R-CNN适用于各种detector baseline,带来可观的性能提升
写作不易,未经允许不得转载~
更多内容请关注个人微信公众号【晓飞的算法工程笔记】
