论文为Google Brain在16年推出的使用强化学习的Neural Architecture Search方法,该方法能够针对数据集搜索构建特定的网络,但需要800卡训练一个月时间。虽然论文的思路有很多改进的地方,但该论文为AutoML的经典之作,为后面很多的研究提供了思路,属于里程碑式的论文,十分值得认真研读,后面读者会持续更新AutoML的论文,有兴趣的可以持续关注
来源:晓飞的算法工程笔记 公众号
论文:Neural Architecture Search with Reinforcement Learning

- 论文地址:https://arxiv.org/abs/1611.01578
- 论文代码:https://github.com/titu1994/neural-architecture-search
Introduction
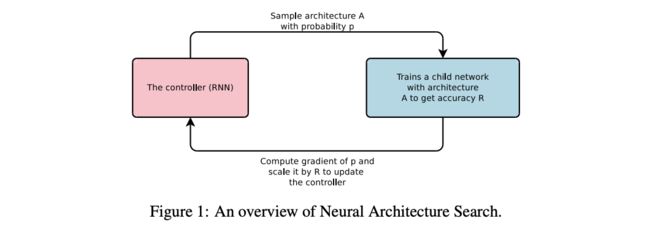
论文提出神经网络架构搜索(Neural Architecture Search),一个用于搜索架构的gradient-based方法,主要包含4个步骤:
- the controller. 网络结构可能看成是可变长的字符串,因此,论文使用循环神经网络(recurrent network)来产生这样的字符串
- child network. 在实际数据集上训练字符串对应的网络(child network),在验证集上获得准确率
- prolicy signal. 将准确率作为奖励信号(reward signal),我们能计算策略梯度(policy gradient)来更新controller
- iteration. 重复步骤1-3,controller将学习到如何针对训练集构建合适的神经网络
Methods
GENERATE MODEL DESCRIPTIONS WITH A CONTROLLER RECURRENT NEURAL NETWORK
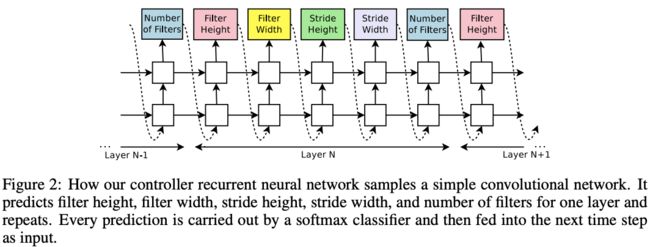
假设需要产生一个仅包含卷积层的神经网络,如图2,the controller会生成一个代表网络超参数的token序列。在实验中,当层数达到设定后,生成操作就会停止,这个设定会按设定随着训练的进行增加。对于the controller产生的网络,会进行训练并在收敛后在预留的验证集上进行测试和记录,将准确率作为指标来优化the controller RNN的参数$\theta_c$
TRAINING WITH REINFORCE
![]()
controller产生的网络可以标记为一连串action $a_{1:T}$,网络在验证集上的准确率标记为$R$,将$R$作为奖励信息,使用强化学习来训练controller最大化$R$,损失函数为准确率的期望
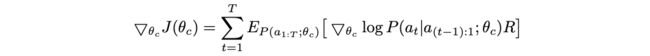
由于$R$对于controller是不可导的($R$是独立训练产生的),需要使用强化学习的policy gradient method来更新$\theta_c$,这里采用Williams的REINFORCE方法,通过多次采样来估算奖励期望进行梯度计算(这里有懂强化学习的读者,可以留言讲解下这个公式)
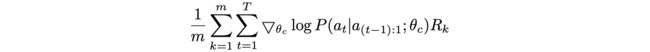
转换后,对于controller的梯度$\triangledown_{\theta_c} J(\theta_c)$就如上式所示,m为controller一次产生的网络数,T为controller产生的超参数,$R_k$为第k个网络的准确率
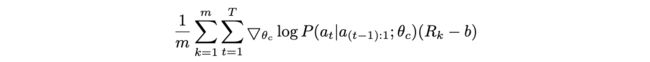
前面的更新公式是对梯度的无偏估计,但会产生较大的方差,因为产生的网络质量不稳定,每轮的准确差异可能很大。为了减少方差,加入基底参数b,即REINFORCE with Baseline,这里的b是之前每轮网络的准确率的指数滑动平均(exponential moving average),这样就能判断当前的准确率较之前是上升了还是下降了,从而更好地更新controller。由于b与当前的iteration无关,所以公式依然是无偏估计

由于网络的训练需要很长时间,论文采用分布式训练以及异步更新参数的方法来加速整体流程。采用parameter-server的结构,总共S个parameter server,K个controller,每个controller一次训练m个网络。在网络都收敛后,controller收集梯度发送给parameter server,收敛定义为训练达到设定的周期
INCREASE ARCHITECTURE COMPLEXITY WITH SKIP CONNECTIONS AND OTHER LAYER TYPES
前面提到的网络构建不包含目前流行的skip-connection layer(ResNet)和branching layer(GoogleNet),论文使用Neelakan-tan提出的给予注意力极致的set-selection type attention来增加这个特性
![]()
在层N添加一个anchor point隐藏层,该层输出N-1个content-based sigmoids来指示之前的层是否需要连接,$h_j$代表构造的网络的第j层的anchor point,$W_{prev}$ $W_{curr}$ $v$是可训练的参数,由于这些参数依然是概率分布,所以REINFORCE方法依然可直接使用
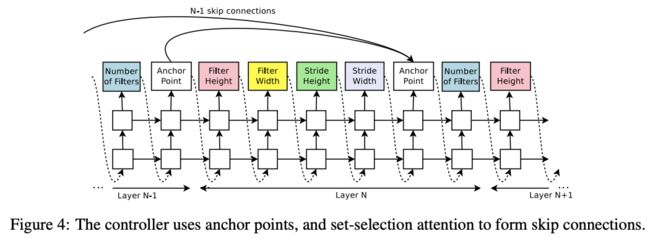
在实际中,如果一个层包含多个输入,会将输入进行concat操作。由于每层的输出大小不一样,而且有的层甚至没有输入和输出,skip connection可能会出现问题,主要有以下3种应对方法:
- 如果当前层无输入,直接将image作为输入
- 在最后一层将所有无连接的输出concat作为最后的的分类器的输入
- 当concat的输入大小不一致时,将小的输入进行0填充至统一大小
最后,论文提到controller可以添加学习率等参数的预测。此外,可以增加layer type的预测,来让controller增加pooling, local contrast normalization, batchnorm等层的添加
GENERATE RECURRENT CELL ARCHITECTURES
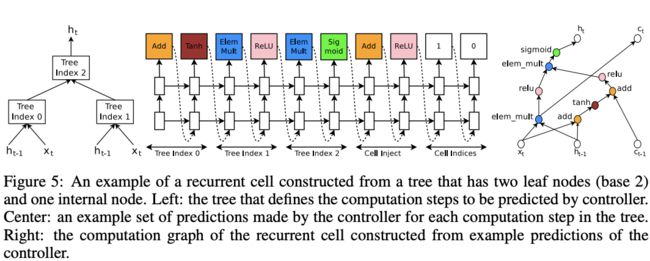
论文也在RNN架构搜索上进行了尝试,RNN和LSTM单元(cell)可以定义为一个树状结构,将$x_t$和$h_{t-1}$作为输入,输出$h_t$。controller需要预测结构中node的合并方式(addition, elementwise, multiplication等)和激活函数(tanh, sigmoid等)来处理输入以及生成输出,然后将两个node的输出喂到下一个node中,为了方便预测,对树状结果的每一个node进行了编号
另外,受LSTM的启发,为每个单元添加变量$c_{t-1}$和$c_t$来存储记忆状态(memory state),让controller选择这两个变量分别连接哪个node,注意$c_{t-1}$需要合并和激活操作(Cell Inject),整体的预测步骤如下:
- controller预测node 0的操作为$Add$和$Tanh$,$a_0=tanh(W_1 * x_t + W_2 * h_{t-1})$
- controller预测node 1的操作为$ElemMult$和$ReLU$,$a_1=ReLU((W_3 * x_t) \odot (W_4*h_{t-1}))$
- controller预测"Cell Index"的第二个变量为0,以及"Cell Inject"的操作为$Add$和$ReLU$,$a_0^{new}=ReLU(a_0+c_{t-1})$
- controller预测node 2的操作为$ElemMult$和$Sigmoid$,$a_2=sigmoid(a_0^{new}\odot a_1)$
- controller预测"Cell Index"的第一个变量为1,将$c_t$设为node 1激活前的输出
EXPERIMENTS AND RESULT
LEARNING CONVOLUTIONAL ARCHITECTURES FOR CIFAR-1
-
Search spac
搜索空间包含卷积操作,ReLu,batch normalization和skip connection。卷积核的长宽限制在$[1,3,5,7]$,output_num限制在$[24,36,48,64]$,步长包含两种,一种固定为1,一种则限制在$[1,2,3]$
-
Training details
controller为双层LSTM,每层35个隐藏单元,使用ADAM优化,学习率为0.0006。搜索的网络进行50轮训练,验证集是从训练机随机挑选的5000张样本,使用Nesterov Momentum训练,学习率为0.1。网络的层数初始为6层,每产生1600个子网络就增加2层
-
Results

在训练了12800个网络后,得到了准确率最高的网络结构,之后进行小范围的超参数(learning rate,weight decay,batchnorm epsilon,epoch to decay learning rate)搜索,最后得到表1的结果:
- 如果不预测步长和池化,能够得到一个5.5% errror rate的15-layer网络结构,这个结构准确率和层数的性价比很高,但是他的性能很慢,见Appendix,值得注意的是,这个结构包含很多长方形和比较大的卷积核,以及包含很多skip connections
- 当需要预测步长时,由于搜索空间很大,搜索出的20-layer网络精度仅有6.01%
- 最后,在允许网络在13层和24层包含池化操作后,controller能够设计一个39-layer的网络,精度达到4.47%。为了缩小搜索空间,让模型预测13层网络,每层由全连接3层的3个子层构成(类似与densenet),此外,缩小卷积数量为$[6,12,24,36]$,每个大层增加40个卷积核,最终准确率达到3.74%,超越人类设计的最好网络
LEARNING RECURRENT CELLS FOR PENN TREEBANK
-
Dataset
RNN在Penn Treebank数据集上进行语言模型构建,进行word-level的实验,即单词预测
-
Search space
combination method为$[add,elem_mult]$,activation method为$[identity,tanh,sigmoid,relu]$,RNN单元的输入对为8对(对应之前的node0 node 1那种),总共大约$6\times 10^{16}$种网络结构
-
Training details
学习率为0.0005,每个子模型训练35个epoch,每个子网络包含两层,奖励函数为$\frac{c}{(validation perplexity)^2}$,c一般设为80。同样的,在搜索完结构后,需要进行超参数搜索
-
Result
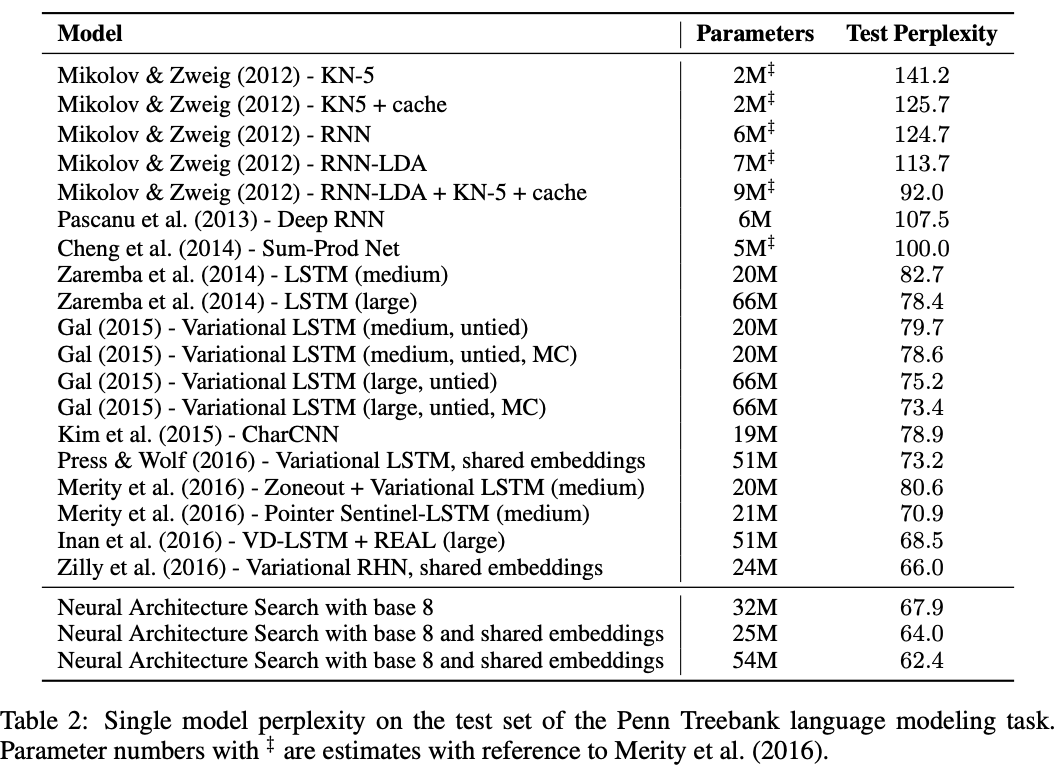
从表2可以看到,搜索到的网络性能达到了state-of-the-art,搜索出来的结构跟LSTM单元十分相似
-
Transfer Learning Results

为了验证搜索的单元在不同任务上的通用性,在同样的数据集上进行character-level的实验,即字符预测,从结构看出,搜索的结构依然表现不错
-
Control Experiment 1 – Adding more functions in the search space
为了验证架构搜索的鲁棒性,添加max合并方法和sin激活方法,从实验来看,虽然搜索空间变大了,但结果相差不大,结果见Appendix A
-
Control Experiment 2 – Comparison against Random Search
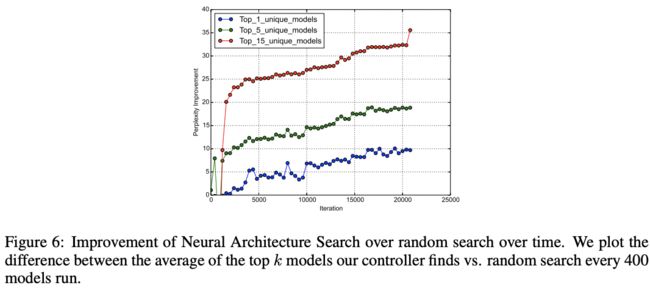
论文进行了随机搜索的对比,尽管这个方法看起来,但是实际经常很难超越,从实验结果看来,论文提出的搜索方法不仅最好的模型要优异,整体平均都要优于随机搜索
CONCLUSION
论文使用强化学习进行Neural Architecture Search这一创新的方法,该方法能够针对数据集搜索构建特定的网络,但搜索的资源消费巨大。从实验的过程来看,论文提出的方法还是需要添加许多人工干预的部分才能突破各个task中的state-of-the-art,而且需要十分多的计算资源和时间,但是从意义来说,该论文开创了AutoML的序幕,为后面很多的研究提供了思路,十分值得认真研读
参考内容
- [Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning
-WILLIAMS,R. J.
](http://www-anw.cs.umass.edu/~barto/courses/cs687/williams92simple.pdf) - [Neural Programmer: Inducing Latent Programs with Gradient Descent - Arvind Neelakantan
](https://arxiv.org/abs/1511.04834)
A APPENDIX
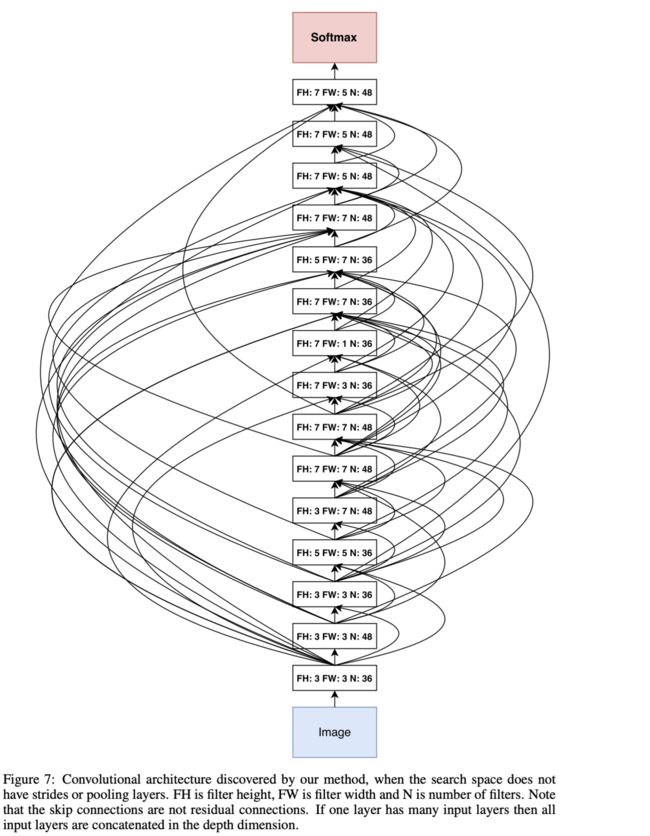
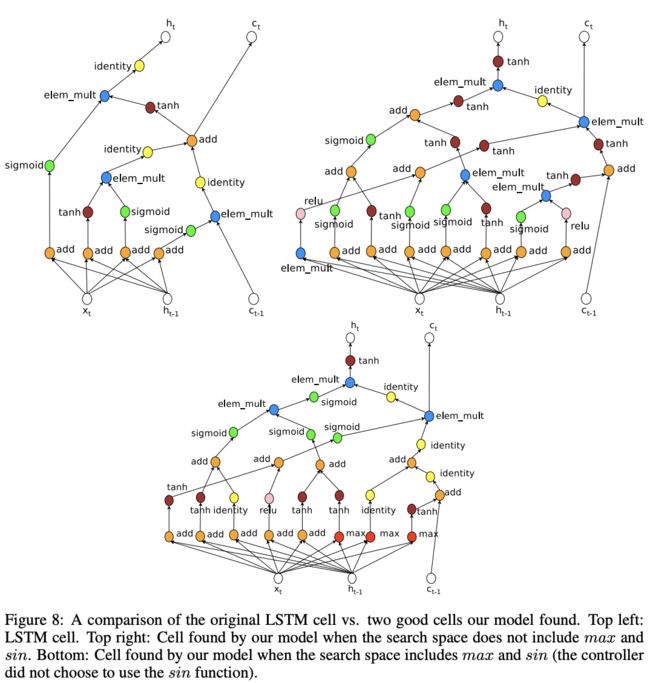
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
