前言
总结自己的redis,日常使用不是特别频繁,所以比较基础。
开篇
redis 是无关系型数据库,因为其实内存数据库,所以常常和他的竞争对手memcached对比,因为两者原理基础相似,存储方式也是key和value的方式。
在memcached中value只能是字符串,而redis就有5种结构了。当然这并是不说mencached就比redis差,只是介绍出redis有哪些优点。
redis最大的优势或者说特点和普通的关系型数据库而言就在于是内存中,这意味着我们有很好都读写能力。
缺点也就很明显了,因为在内存中消耗的资源成本肯定比持久化存储的成本高。毕竟你要向公司申请一台redis,公司会考虑到今年给你们部门的开销,毕竟公司上层很可能不懂什么是技术,只知道资本主义那一套。
如果是技术出身的老板可能还会怼我们开发人员,因为他会在技术与资本之前权衡,但是往往选择资本主义,然后用着他的专业术语和我们沟通一番。
好了说到内存,那么肯定得考虑如何持久化,因为别的不说,你总得备份数据库吧,万一服务器抽风呢?
1.时间点存储,每隔一段时间存储一些数据或者说某个时间点来存储数据,总之就是规划时间这回事。然后这种方式被别人称为rdb,redis database。
2.AOF方式,(append only file)。这种方式就是通过操作日志的方式,每一次写(增删改)的操作都会被记录,这样就做到了持久化了。
上面的优劣点就不介绍了,因为第一章只是简单的介绍。
redis的数据结构
前文:我在远程操作,使用redis client作为演示。
redis 开启远程:修改 protected-mode 为 no ; 修改 daemonize 为 no ; 修改默认的,设置为 bind 0.0.0.0,然后添加一个密码,具体的可百度。当然这样是不安全的,只作为演示。
上图是我连接数据库后的,但是我只使用第一个,就算是生产环境一般也使用一个。
上文介绍到redis和memcached不同之处,在于由5种数据结构,看一下吧。
string 字符
set str string
key: str value string

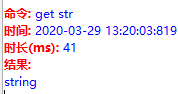
当然我们命令行查看的方式:
get str
删除的话,就是del str,在此不演示了。
list 列表
添加一个list,key命名为keylist 值为item1
rpush keylist item1
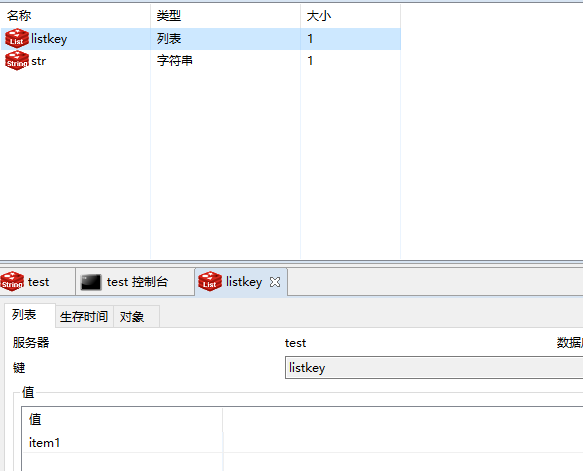
当然我们也可以左边push进入:lpush keylist item2

你们看item2在item1的上方
删除的方式,一个是往左边弹出:
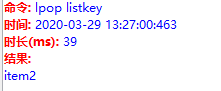
查看一下剩下什么:
lrange listkey 0 -1
![]()
因为redis client 是在是不好用,所以换回了putty,命令行模式。
往右边弹出:
rpop listkey
这样就没有任何数据了。
lrange listkey 0 -1
![]()
在列表中是支持索引的。
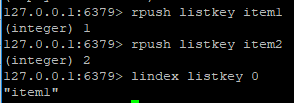
上图中使用了lindex 索引。但是是没有rindex。
集合
集合通过散列来实现的,这意味着每个字符都是不同的,集合同时是无序的。这和我们在高级语言中学习集合是一致的。
sadd setkey item1
往集合中增加一个值,如果key不存在就创建,返回了集合中的值的数量。
![]()
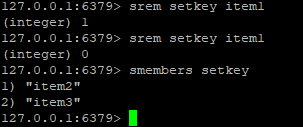
查询集合是使用:smembers setkey

中间有一个我打错了,望见谅。
查找的方式是:sismember setkey item1 如果存在返回1,不存在返回0

删除是srem setkey item1,删除了是1,没有删除是0。
散列
如果把其他类型比作游击队,那么散列名字虽然有个散字,但是却是一个团队。
这似乎补充了redis没有表的问题。
使用hset作为添加散列:
hset hashkey subhashkey1 item1-1
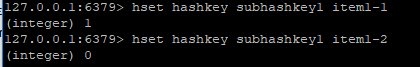
如果subhashkey1存在将会覆盖,且返回0。
查询的方式是hget,hget hashkey subhashkey1
![]()
查询散列中的keys,可以用hkeys hashkey.那么将会显示出subhashkey1,这里我就不展示。
如果使用hgetall hashkey,那么显示的将会是:
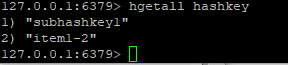
会显示所有的键值对,包括了值。
下图为删除的:
![]()
有序集合
写到这里,其实应该返回到集合去查看的。
前面解释了集合是通过哈希实现的,集合是有索引的。
对应的是——哈希值:value。
在有序集合中,只是这个哈希值不再是系统帮助我们生成,而是我们手动输入,这样我们通过我们输入的值就可以找到value。
有两个一定要记住的术语:
1.有序集合的键被称作成员。
2.有序集合的值被称作分值。
我们通过zadd来添加。
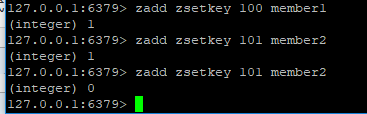
上文可知,通知1是添加了,0是覆盖了。
对了,redis符合一句话,没有错误就是成功了,所以不存在返回0是出现错误。
zrange zsetkey 0 -1
是查询。
zrange zsetkey 0 -1 会有另外一个参数,就是展示出我们输入的成员。
如下图:
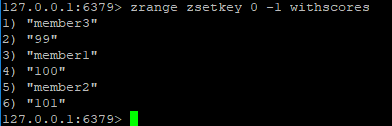
有一个zrangescore的,也特别重要:

它会根据我们的成员范围来查找。
最后一个是删除zrem,zrem删除的是分值,而不是成员,因为他是一个集合,而不是一个散列。

如果我们使用zrem通过成员去删除的话:
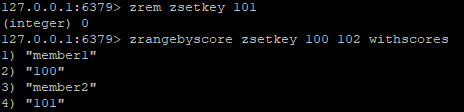
是不会成功的,返回结果为0,代表zrem中没有101这个分值,而不是说这条语句失败了。
总结
redis 的语句都特别好理解,但是在使用中一般都会出现问题,当然这些问题都会交给运维人员去解决(重启以及删库跑路),但是当持续崩的话,可能自己都会受到波及。