最近想学习学习I/O流相关的内容,看到一篇博客:
java IO流学习总结
这篇博客总结得很好,但我还是想按照自己的思路把一些疑点梳理一下。我们知道,IO流分为字符流读写和字节流读写,本篇博客以文件读写作为切入点,总结字符流文件读写相关知识点(字节流暂放)。下面附上IO图解:
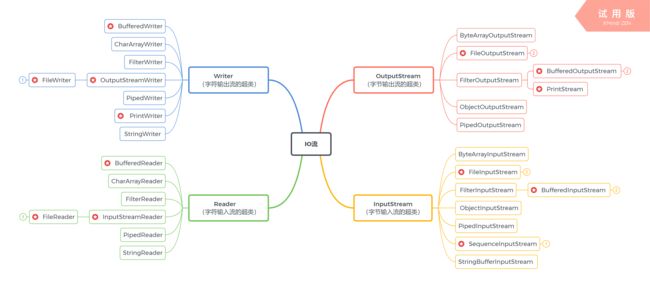
由图可知字符流的所有类都继承于Writer和Reader,其中直接操作文件读写的类是FileReader和FileWriter,这两者继承InputStreamReader和OutputStreamWriter。而InputStreamReader和OutputStreamWriter是字符和字节的桥梁,也可称之为字符转换流,这个先不细说,两者的区别暂且只需要记住以下这点:
- FileReader和FileWriter作为其子类,仅作为操作字符文件的便捷类来使用,文件读写采用平台默认的编码,不能手动设置编码。若平台编码跟文件编码不一致,便会出现乱码,此时要使用字符转换流,也要与字节流配套使用,这是后话。
File与FileDescriptor
这两者都是描述文件的相关类,区别如下
-
File:是磁盘文件和目录路径名的一种抽象形式,可表示文件,也可表示文件夹。其直接继承自 Object,实现了 Serializable 接口和 Comparable 接口;实现 Serializable 接口意味着 File 对象可以被序列化,而实现 Comparable 接口意味着 File 对象可以比较大小;此外 File 并没有什么特殊之处,就是对文件的一种上层抽象封装实现,方便操作文件。
-
FileDescriptor:是文件描述符,用来表示开放文件、开放套接字等。当 FileDescriptor 表示文件时,我们可以通俗的将 FileDescriptor 看成是该文件,但是不能直接通过 FileDescriptor 对该文件进行操作,若要通过 FileDescriptor 对该文件进行操作,则需要新创建 FileDescriptor 对应的 FileOutputStream,然后再对文件进行操作。此外,其中的静态变量in/out/err分别代表标准输入、输出、错误流的描述符,例如以下代码:
try {
FileOutputStream out = new FileOutputStream(FileDescriptor.out);
out.write('A');
out.close();
} catch (IOException e) {
}
out就是一个FileDescriptor对象,它是通过构造函数FileDescriptor(int fd)创建的。以上代码相当于System.out.print()的效果,同理,in和err对标System.in和System.err。除此之外,FileDescriptor可以用来定义“文件”、“Socket”等的文件描述符。
字符流中操作文件使用File即可,例如:
File fileHome = new File("C:\\_study\\repo\\JavaTest\\JavaIO\\files");
File srcFile = new File(fileHome,"src.txt");
File destFile = new File(fileHome,"res.txt");
FileWriter fileReader = new FileReader(srcPath);
FileWriter fileWriter = new FileWriter(destFile);
FileWriter与FileReader
使用这两个类读写文件的代码如下所示:
package CharStream;
import java.io.*;
import java.util.Arrays;
public class FileCtrByChar {
private final FileWriter fileWriter;
private final FileReader fileReader;
public FileCtrByChar(File srcFile, File destFile) throws IOException {
this.fileWriter = new FileWriter(destFile);
this.fileReader = new FileReader(srcFile);
}
/**
*文本文件复制,逐个读取字符
*/
public void readWriteByChar() throws IOException {
//long startTime = System.currentTimeMillis();
int ch;
//按照码点来读取
while((ch = fileReader.read())!=-1){//依次读到文件末尾
fileWriter.write(ch);//这只是将数据写入缓冲区,需要flush才能将缓冲区中数据写入文件,缓冲区默认大小8K,超过8K会自动写入
}
}
/**
*设置char数组,一次读一个字符数组
*/
public void readWriteByCharArr() throws IOException {
char[] chs = new char[40];
int len = 0;
while((len = fileReader.read(chs))!=-1){
fileWriter.write(chs);
}
}
public void close() throws IOException {
fileWriter.close();//close之前会调用flush
fileReader.close();
}
}
可见,FileWriter的输出过程中也是存在缓冲区的。
flush()和close()区别
-
flush()将缓冲区的内容写入目标,并使缓冲区为空以供其他数据存储,但不会永久关闭流。 这意味着仍然可以向流中写入更多数据。
-
close()会永久关闭流。 如果要进一步写入一些数据,则必须再次重新打开流,并将数据附加到现有数据之后。
注意:因为Writer带有flush(),所以其所有子类都带有缓冲区功能。因此,FileWriter和BufferWriter都有缓冲区;注意读写结束时,一定要刷新或关闭,不然数据可能留在缓冲区内无法完全写入。
使用Buffer进行包装
FileWriter和FileReader可以使用BufferWriter和BufferReader进行包装,代码如下所示。
public void readWriteByCharInBuffer() throws IOException {
BufferedReader bufferedReader = new BufferedReader(fileReader);
BufferedWriter bufferedWriter = new BufferedWriter(fileWriter);
int ch;
while((ch = bufferedReader.read())!=-1){
bufferedWriter.write(ch);
}
bufferedReader.close();
bufferedWriter.close();
}
public void readWriteByCharArrInBuffer() throws IOException {
char[] chs = new char[50];
int len = 0;
BufferedReader bufferedReader = new BufferedReader(fileReader);
BufferedWriter bufferedWriter = new BufferedWriter(fileWriter);
while((len = bufferedReader.read(chs))!=-1){
bufferedWriter.write(chs);
}
bufferedReader.close();
bufferedWriter.close();
}
public void readWriteByLine() throws IOException {
BufferedReader bufferedReader = new BufferedReader(fileReader);
BufferedWriter bufferedWriter = new BufferedWriter(fileWriter);
String line;
while((line = bufferedReader.readLine())!=null){
bufferedWriter.write(line);
}
bufferedReader.close();
bufferedWriter.close();
}
至于使用buffer包装的好处,网上的一致说法是,引入了缓冲区存取效率更快。缓冲区的好处毋庸置疑:
为什么使用缓冲区效率更高?
- 当设置缓冲区时,计算机会使用DMA执行IO操作,数据存取完毕之前,会腾出cpu的时间,结束后通知cpu接管后续操作。不使用缓冲时,cpu会主动地进行周期轮询等等操作,查看IO设备是否读完数据,此时cpu不能做其它操作,效率更低。
但是我仍然产生了困惑,FileWriter写文件过程中不是也有缓冲区嘛,读文件不是也可以使用char数组进行缓存嘛,那么Buffer包装的好处究竟体现在哪呢?
于是我进行了一个实验:准备一个140kB的文本文件,使用带Buffer和不带Buffer的方法对其进行读写测试,即将文本复制进另一个文本(复制操作代码见上文),测试读写效率。通过程序执行时间来表达读写效率,记录时间的代码如下:
long startTime = System.currentTimeMillis();
······
long endTime = System.currentTimeMillis();
System.out.println("运行时间:" + (endTime - startTime) + "ms");
分别测试三次,测试结果如下:
| 方法 | FileWriter&FileReader | BufferWriter&BufferReader |
|---|---|---|
| 按字符读写 | 30ms,38ms,41ms | 16ms,16ms,16ms |
| 按char[]读写 | 16ms,14ms,16ms | 15ms,16ms,15ms |
测试结果一目了然。如果设置字符数组,读取文件字符数据时,使用Buffer包装和不使用相比,读写效率几乎一致;但按字符逐个读取,使用Buffer的效率就要高出不少。
实际上,阅读源码可知,FileReader和BufferReader两者的read(char[] buf)都继承自Reader,没有差别;但是read()方法,BufferReader对其进行了重写,做了优化。即便是对于一个字符的读取,BufferedReader依然是先读取一个数组的数据到缓冲区中,然后从缓冲区中一个个的取,因此效率更高。
除此之外,BufferReader还有一些FileReader没有的特性,例如提供了readLine()方法,可以逐行读取(相对应的,BufferedWriter中提供newLine()方法支持换行),还可以指定缓冲区的大小,对缓冲区的支持更专业。
因此,在实践中可以无需纠结地使用BufferReader与BufferWriter。