面试官:出现了性能问题,该怎么去排查呢?
程序猿:接口响应那么慢,时间都花到哪里去了?
运维喵:为什么你的应用跑着跑着,CPU 就接近 100%?

分享一些真实生产问题排查故事,看看能否涨姿势,能否 get 到其中之「趣」?
另外,为了方便收藏,文末把 Java 程序优化及问题排查套路,整理成了葵花宝典,一定要记得收藏呦。
1. 业务催的急,心发慌的现场!
2012 年,在一家支付公司做用户域的基础服务,每天做的事儿便是为满足业务需求,制定各种各样的 API。
某天,业务反馈线上调用查询省份地市接口频繁超时 ... ...
生产要敬畏,生产无小事。
于是乎,煎饼果子丢一旁。一边让业务同事提供调用接口时的唯一 ID(rpid,查询日志全靠它),一边找运维同事确认网络有没有问题、服务有没有问题,在排除环境没问题的前提下,快速根据 rpid 获取日志并进行分析。
日志记得好,排查问题没烦恼。发现程序执行到访问数据库拿数据时总会需要花费很长时间,导致业务接口超时。
当时,分析原因有二。
原因一:大部分接口都是读在线库,而该接口读的则是离线库,但是离线库配置的最大连接数是 2,在高并发情况下,拿不到数据库连接;
原因二:省份地市信息为不变信息,程序并没有借助缓存提升性能。
寻得病症,便可对症下药。
2. 服务一启动,运维就疯狂打 Call 的现场。
2016 年,在一家互联网金融公司负责理财网站的从 0 到 1,都知道要想服务做的好,监控模块少不了。
当时时间紧任务重,分工也很明确,有两个兄弟负责监控模块的搭建,测试验证通过后,进行上线,但是只要一启动监控模块,运维同事都反馈机器 CPU 疯狂报警。
生产要敬畏,生产无小事。
于是,带着做监控模块的兄弟开启了排查诊断之旅。
当时的代码没有了,为了更好的还原现场,还是跑一个模拟程序。
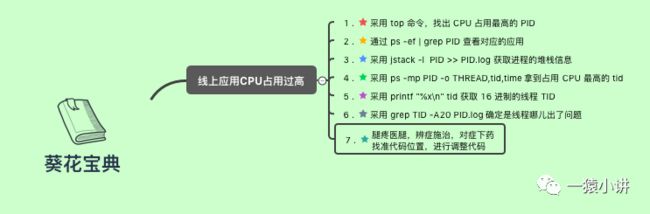
首先,采用 top 命令,找出 CPU 占用最高的进程 PID;

然后,通过 ps -ef | grep PID 查看对应的应用,确认一下是不是你的应用,运维喵别给扣错帽子,说啥咱也不能背锅。

接着,采用 jstack -l PID >> PID.log 获取进程的堆栈信息。
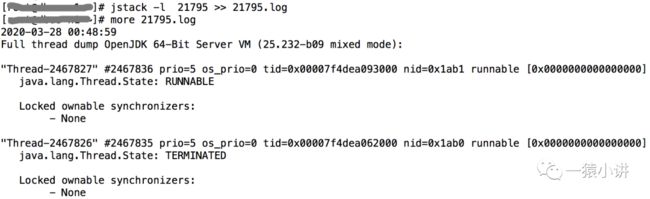
然后,采用 ps -mp PID -o THREAD,tid,time 拿到占用 CPU 最高的线程 TID。
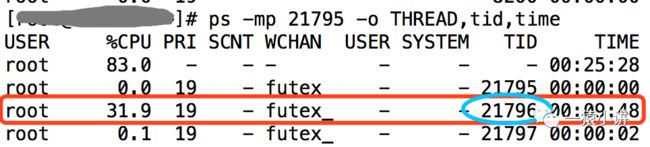
接着,采用 printf "%x\n" tid 获取 16 进制的线程 TID。

最后,采用 grep TID -A20 PID.log 确定是线程哪儿出了问题。
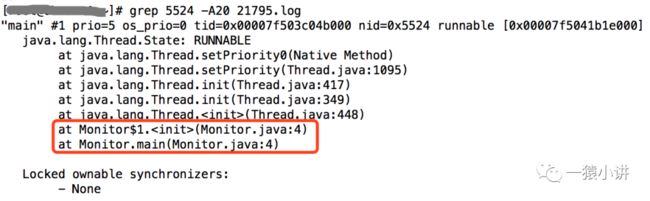
找到代码位置,便可对症下药。
另外,你或许会感觉命令繁琐,其实摆脱命令的困扰,采用 VisualVM 图形化性能监控工具,则会有种土枪换炮的感觉,不过生产上一般还是用命令的居多(言外之意:势必要掌握命令)。

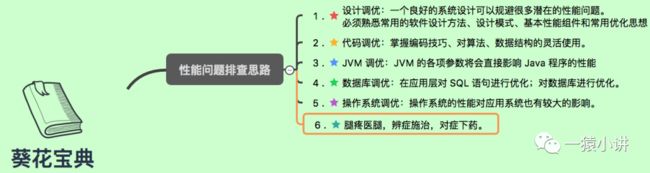
3. 经验从哪儿来?
作为一个久经职场的码农,真心的告诉你,经验来源于填坑,遇到的坑越多,经验越丰富,虽然遇到的问题可能变幻莫测,但是解决问题却有章可循。
用心画了一部 Java 程序优化的「葵花宝典」,丑是丑了点,但是真能解决大问题,请放心收藏。
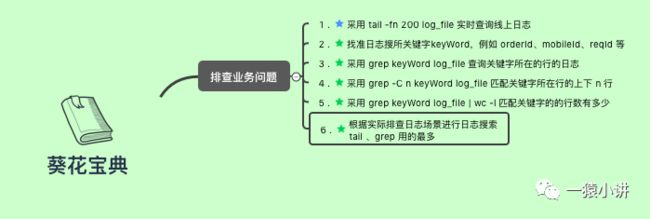

好了,今天的分享接近尾声,以备不时之需,建议你好好收藏,最重要的是去拿去实践。
