目标是修改LeNet用于识别德国交通标志,共43个类别。LeNet有两个卷积层、三个全连接层,我增加了一层卷积,修改了kernel大小。另外,在全连接层中加入了dropou用于防止过拟合。这里记录下搭建网络的过程,总结使用TensorFlow搭建并训练卷积网络的方法。
1. 数据集的载入、augment与normalization
- 载入数据集
"""
载入数据集
"""
# 下载好的数据集是用pickl序列化了的,所以要用pickle来读取
import pickle
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import tensorflow as tf
# flatten用于最后一层卷积后的flatten
from tensorflow.contrib.layers import flatten
training_file = "./datasets/traffic-signs-data/train.p"
validation_file= "./datasets/traffic-signs-data/valid.p"
testing_file = "./datasets/traffic-signs-data/test.p"
with open(training_file, mode='rb') as f:
train = pickle.load(f)
with open(validation_file, mode='rb') as f:
valid = pickle.load(f)
with open(testing_file, mode='rb') as f:
test = pickle.load(f)
X_train, y_train = train['features'], train['labels']
X_valid, y_valid = valid['features'], valid['labels']
X_test, y_test = test['features'], test['labels']
训练、验证、测试集各有34799、4410、12630张图片,图片都为(32, 32, 3),共有43个类别。
- 接下来是data augment。
我用了两个特别简单的方法来扩大数据集:一个是将图片都转为灰色,也就是将三个channel上的像素都取为它们的均值;另一个是对每张图片都加上一个100以内的整数。
但并没有使用全部的数据,考虑到我用CPU训练,只是使用了五万多张图片。
"""
Data Augmen
"""
n_classes = y_train.max() + 1
n_train = X_train.shape[0]
# 第二种方法,先随机生成X_train.shape[0]个正整数
bias = np.random.randint(0,100,(n_train,1,1,1))
# broadcasting,并保证范围都在[0,255]以内
X_train_aug0 = np.clip(X_train+bias, 0, 255).astype(np.uint8)
y_train_aug0 = y_train
# 沿各个图片的channel取均值
# 本来为(34799, 32, 32, 3),取均值后为(34799, 3, 3, 1)
a = np.mean(X_train,axis=3,keepdims=True).astype(np.uint8)
# 将均值扩到3个channel,(34799, 3, 3, 1)->(34799, 32, 32, 3)
X_train_aug1 = np.concatenate((a,a,a),axis=3)
y_train_aug1 = y_train
X_train_aug = np.concatenate((X_train_aug0,X_train_aug1), axis=0)
y_train_aug = np.concatenate((y_train_aug0,y_train_aug1), axis=0)
# 保存新数据
with open('./datasets/traffic-signs-data/train_aug.p','wb') as f:
pickle.dump(dict(features=X_train_aug,
labels=y_train_aug,
sizes=np.concatenate((train['sizes'],train['sizes']),axis=0),
coords=np.concatenate((train['coords'],train['coords']),axis=0)),
f)
# 添加到训练集,只使用了四分之一的新数据
# 现在训练集有52199张图片
X_train = np.concatenate((X_train,X_train_aug[0:-1:4,:,:,:]), axis=0)
y_train = np.concatenate((y_train,y_train_aug[0:-1:4]), axis=0)
- normalize训练、验证、测试集
就使训练集均值为零后除以标准差
# zero out the mean
train_image_mean = np.mean(X_train, axis=0)
X_train_norm = X_train - train_image_mean
# normalize the variance
train_image_std = np.std(X_train_norm, axis=0)
X_train_norm = X_train_norm / train_image_std
对测试、训练集做同样的操作,保证分布一致:
X_valid_norm = X_valid - train_image_mean
X_valid_norm = X_valid / train_image_std
X_test_norm = X_test - train_image_mean
X_test_norm = X_test / train_image_std
2. 搭建网络
接下来就是搭建网络的过程了。网络结构为:
| Layer | Description |
|---|---|
| Input | 32x32x3 RGB image |
| Convolution 3x3 | 1x1 stride, same padding, outputs 32x32x16 |
| LEAKY_RELU | |
| Max pooling 2x2 | 2x2 stride, outputs 16x16x16 |
| Convolution 3x3 | 1x1 stride, same padding, outputs 16x16x32 |
| LEAKY_RELU | |
| Max pooling 2x2 | 2x2 stride, outputs 8x8x32 |
| Convolution 3x3 | 1x1 stride, same padding, outputs 8x8x64 |
| LEAKY_RELU | |
| Max pooling 3x3 | 2x2 stride, outputs 3x3x64 |
| Flatten | output 576 |
| Fully connected | output 120 |
| LEAKY_RELU | |
| Dropout | |
| Fully connected | outout 84 |
| LEAKY_RELU | |
| Dropout | |
| Fully connected | output 43 |
| Softmax |
- kernel和全连接层权值的建立
三层kernel分别为:16个3x3x3、32个3x3x16、64个3x3x32
全连接层参数为:576x120、120x84、84x43
用到的API为:
tf.variable_scope()
tf.get_variable()
tf.truncated_normal_initializer()
tf.add_to_collection()
mu = 0
sigma = 0.1
# trainable用于控制卷积层和全连接层是否训练,记不得当时我为什么要控制这个了......
# regularizer是想传入通过tf.contrib.layers.l2_regularizer()返回的函数来着。
# 将其用于regularize全连接层参数,但是训练效果不好,最后就没用
def initialize_parameters(trainable=[True,True], regularizer=None):
# 将创建好的变量放入字典中返回
parameters = {}
with tf.variable_scope('parameters', reuse=tf.AUTO_REUSE):
# Layer 1: Convolutional.
# 每一层都用了variable_scope,并设置了reuse=tf.AUTO_REUSE,配合tf.get_variable()达到共享变量的目标。没有变量时创建,有的话就调用创建好的。
with tf.variable_scope('conv1', reuse=tf.AUTO_REUSE):
# 第一个卷基层的kernel,3x3,输入#channel,输出#channel
conv1_W = tf.get_variable("conv1_W", [3,3,3,16],
initializer = tf.truncated_normal_initializer(mu,sigma), dtype=tf.float32,
trainable=trainable[0])
# 除了kernel以外,别忘了bias
conv1_b = tf.get_variable("conv1_b", [1,1,1,16],
initializer = tf.zeros_initializer(), dtype=tf.float32,
trainable=trainable[0])
parameters["conv1_W"] = conv1_W
parameters["conv1_b"] = conv1_b
# Layer 2: Convolutional.
with tf.variable_scope('conv2', reuse=tf.AUTO_REUSE):
conv2_W = tf.get_variable("conv2_W", [3,3,16,32],
initializer = tf.truncated_normal_initializer(mu,sigma), dtype=tf.float32,
trainable=trainable[0])
conv2_b = tf.get_variable("conv2_b", [1,1,1,32],
initializer = tf.zeros_initializer(), dtype=tf.float32,
trainable=trainable[0])
parameters["conv2_W"] = conv2_W
parameters["conv2_b"] = conv2_b
# Layer 3: Convolutional.
with tf.variable_scope('conv3', reuse=tf.AUTO_REUSE):
conv3_W = tf.get_variable("conv3_W", [3,3,32,64],
initializer = tf.truncated_normal_initializer(mu,sigma), dtype=tf.float32,
trainable=trainable[0])
conv3_b = tf.get_variable("conv3_b", [1,1,1,64],
initializer = tf.zeros_initializer(), dtype=tf.float32,
trainable=trainable[0])
parameters["conv3_W"] = conv3_W
parameters["conv3_b"] = conv3_b
# Layer 4: Fully Connected.
with tf.variable_scope('fc1', reuse=tf.AUTO_REUSE):
fc1_W = tf.get_variable("fc1_W", [576,120],
initializer=tf.truncated_normal_initializer(mu,sigma), dtype=tf.float32,
trainable=trainable[1])
fc1_b = tf.get_variable("fc1_b", [1,120],
initializer=tf.zeros_initializer(), dtype=tf.float32,
trainable=trainable[1])
parameters["fc1_W"] = fc1_W
parameters["fc1_b"] = fc1_b
# Layer 5: Fully Connected.
with tf.variable_scope('fc2', reuse=tf.AUTO_REUSE):
fc2_W = tf.get_variable("fc2_W", [120,84],
initializer=tf.truncated_normal_initializer(mu,sigma), dtype=tf.float32,
trainable=trainable[1])
fc2_b = tf.get_variable("fc2_b", [1,84],
initializer=tf.zeros_initializer(), dtype=tf.float32,
trainable=trainable[1])
parameters["fc2_W"] = fc2_W
parameters["fc2_b"] = fc2_b
# Layer 6: Fully Connected.
with tf.variable_scope('fc3', reuse=tf.AUTO_REUSE):
fc3_W = tf.get_variable("fc3_W", [84,n_classes],
initializer=tf.truncated_normal_initializer(mu,sigma), dtype=tf.float32,
trainable=trainable[1])
fc3_b = tf.get_variable("fc3_b", [1,n_classes],
initializer=tf.zeros_initializer(), dtype=tf.float32,
trainable=trainable[1])
parameters["fc3_W"] = fc3_W
parameters["fc3_b"] = fc3_b
# add l2_regularization to collection 'regularize'
# 如果传入了用于normalize的函数,则将对全连接层权值normalize的tensor加入集合'regularize'中。在cost函数中通过集合加入这些regularize项。
if regularizer != None:
tf.add_to_collection('regularize', regularizer(fc1_W))
tf.add_to_collection('regularize', regularizer(fc2_W))
tf.add_to_collection('regularize', regularizer(fc3_W))
else:
# 如果没有传入regularize函数,则在集合中加个常量0就好。
# 因为后面使用tf.add_n(tf.get_collection('regularize'))来调出集合中的tensor
# 若集合为空则会报错的。
tf.add_to_collection('regularize', tf.constant(0., dtype=tf.float32))
# 各个可训练的参数都在改字典中了
# 搭建网络结构时调用就好
return parameters
建立权值的函数写好后,下面就是搭建网络前向传播的函数了:
- 搭建网络结构:
用到的API为:
tf.nn.conv2d()
tf.nn.leaky_relu()
tf.nn.max_pool()
tf.nn.dropout()
tf.contrib.layers.flatten()
tf.matmul()
其中关于tensorflow中的same padding和valid padding的介绍可看这里。
# x为建立的placeholder,为(None, 32, 32, 3)
# parameters就是上一函数的返回
# keep_prob用于控制各层dropout的概率。卷基层概率都设为1。
# 必须通过参数控制。
# 因为在训练过程中和在测试网络性能过程中其值不同。
# 返回的tensor logits为全连接的输出,为(None, 43),没有接softmax
# 因为后面使用的是tf.nn.softmax_cross_entropy_with_logits()来构造cost
def LeNet_forwardpass(x, parameters, keep_prob):
# Layer 1: Convolutional. Input = 32x32x3. Output = 32x32x16.
conv1_W = parameters["conv1_W"]
conv1_b = parameters["conv1_b"]
conv1 = tf.nn.conv2d(x, conv1_W, strides=[1,1,1,1], padding='SAME') + conv1_b
# Activation.
conv1 = tf.nn.leaky_relu(conv1, name="conv1_out")
# Pooling. Input = 32x32x16. Output = 16x16x16.
conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
# dropout
conv1 = tf.nn.dropout(conv1, keep_prob=keep_prob[0])
# Layer 2: Convolutional. Input = 16x16x16. Output = 16x16x32.
conv2_W = parameters["conv2_W"]
conv2_b = parameters["conv2_b"]
conv2 = tf.nn.conv2d(conv1, conv2_W, strides=[1,1,1,1], padding='SAME') + conv2_b
# Activation.
conv2 = tf.nn.leaky_relu(conv2, name="conv2_out")
# Pooling. Input = 16x16x32. Output = 8x8x32.
conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='VALID')
# dropout
conv2 = tf.nn.dropout(conv2, keep_prob=keep_prob[1])
# Layer 3: Convolutional. Input = 8x8x32. Output = 8x8x64.
conv3_W = parameters["conv3_W"]
conv3_b = parameters["conv3_b"]
conv3 = tf.nn.conv2d(conv2, conv3_W, strides=[1,1,1,1], padding='SAME') + conv3_b
# Activation.
conv3 = tf.nn.leaky_relu(conv3, name="conv3_out")
# Pooling. Input = 8x8x64. Output = 3x3x64.
conv3 = tf.nn.max_pool(conv3, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='VALID')
# dropout
conv3 = tf.nn.dropout(conv3, keep_prob=keep_prob[2])
# Flatten. Input = 3x3x64. Output = 576.
fc0 = flatten(conv3)
# Layer 4: Fully Connected. Input = 576. Output = 120.
fc1_W = parameters["fc1_W"]
fc1_b = parameters["fc1_b"]
fc1 = tf.matmul(fc0, fc1_W) + fc1_b
# Activation.
fc1 = tf.nn.leaky_relu(fc1, name="fc1_out")
# Dropout
fc1 = tf.nn.dropout(fc1, keep_prob=keep_prob[3])
# Layer 5: Fully Connected. Input = 120. Output = 84.
fc2_W = parameters["fc2_W"]
fc2_b = parameters["fc2_b"]
fc2 = tf.matmul(fc1, fc2_W) + fc2_b
# Activation.
fc2 = tf.nn.leaky_relu(fc2, name="fc2_out")
# Dropout
fc2 = tf.nn.dropout(fc2, keep_prob=keep_prob[4])
# Layer 6: Fully Connected. Input = 84. Output = n_classes.
fc3_W = parameters["fc3_W"]
fc3_b = parameters["fc3_b"]
logits = tf.matmul(fc2, fc3_W) + fc3_b
return logits
- 建立输入输出placeholder:
用到的API:
tf.placeholder()
tf.one_hot()
x = tf.placeholder(dtype=tf.float32, shape=(None, 32, 32, 3))
# 因为数据集中的label都为0-42的整数,为减少工作(偷懒)
# 没有对数据集的label转为one-hot形式,而是这里通过调用tf.one_hot()来转~~
# 另外,由于要在训练和测试中分别控制dropout的概率
# 所以将这个keep_prob也设为placeholder。
y = tf.placeholder(dtype=tf.int32, shape=(None))
keep_prob = tf.placeholder(dtype=tf.float32, shape=(5))
# one_hot_y为(None, 43),每一行只有一个1,其他为0.
one_hot_y = tf.one_hot(y, n_classes)
3. cost和优化器
下面是一些参数的设置,cost函数的建立,和优化器的建立。这里使用了learning rate decay。
用到的API:
tf.contrib.layers.l2_regularizer()
tf.nn.softmax_cross_entropy_with_logits()
tf.reduce_mean()
tf.add_n()
tf.get_collection()
tf.Variable()
tf.train.exponential_decay()
tf.train.AdamOptimizer()
# 训练的epoch和batch size
EPOCHS = 25
BATCH_SIZE = 128
# 初始学习率
rate = 0.005
# 下降率
decay_rate = 0.8
# 多少次一下降
decay_steps = 500
trainable = [True,True]
lamb = 0.01
# 返回的regularizer是一个函数,可以对输入tensor计算正则项
regularizer = tf.contrib.layers.l2_regularizer(lamb)
# 调用上面的函数建立参数
parameters = initialize_parameters(trainable, regularizer=None)
# 前向传播得到输出
logits = LeNet_forwardpass(x, parameters, keep_prob)
# 对网络的输出softmax后与label计算cross entropy
# 返回的是各个example的cross entropy,下面要对其求平均
# 该API不再推荐了,推荐使用v2版本
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=one_hot_y, logits=logits)
# 求平均后,加上regularization项,但这里别没有
loss_operation = tf.reduce_mean(cross_entropy) + tf.add_n(tf.get_collection('regularize'))
# learning rate decay
# 这个global_step是一个不可训练的变量,需要传给优化器对象的minimize方法
# 在训练时,每一次优化都会对其加1
global_step = tf.Variable(0, trainable=False)
# 返回的为tensor,可看文档,是对初始学习率decay的学习率tensor。
decay_rate = tf.train.exponential_decay(decay_rate=decay_rate, decay_steps=decay_steps,
global_step=global_step, learning_rate=rate)
# 建立优化器对象。learning_rate参数可传入浮点数或tensor
# 这里就传入的tensor
optimizer = tf.train.AdamOptimizer(learning_rate = decay_rate)
# trainig_operation是一个Operation,指出优化的是loss_operation.
# 文档中也说了:If global_step was not None, that operation also increments global_step.
# 现在传入了global_step,那么每次执行该Operation就会对global_step加1.
training_operation = optimizer.minimize(loss_operation, global_step=global_step)
在正式训练之前还要建立各评估函数,用于每次训练完之后,调用以便看看模型在训练集及验证集上的准确率。
4. 评估函数
思路很简单,对于网络的输出,找到最大值的索引,也就是该实例的类别,与其本身的label相比较,相等说明分类正确。然后计算分类正确的比例,也就是准确率了。用到的API:
tf.argmax()
tf.equal()
tf.cast()
tf.reduce_mean()
tf.get_default_session()
tf.Session.run()
tf.train.Saver()
# 很简单,accuracy_operation也就是准去率tensor了
correct_prediction = tf.equal(tf.argmax(logits, 1, output_type=tf.int32), y)
accuracy_operation = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
# 建立个函数在Session中调用,方便
def evaluate(X_data, y_data):
num_examples = len(X_data)
total_accuracy = 0
sess = tf.get_default_session()
# 这里是按batch评估准确率,最后计算总准确率了
# 这样的话应该运行速度比一次计算整体数据集的准确率快。
for offset in range(0, num_examples, BATCH_SIZE):
batch_x, batch_y = X_data[offset:offset+BATCH_SIZE], y_data[offset:offset+BATCH_SIZE]
# 因为是测试模型准确率,所以dropout概率为1,就是没有dropout。
accuracy = sess.run(accuracy_operation, feed_dict={x: batch_x, y: batch_y, keep_prob: [1.0,1.0,1.0,1.0,1.0]})
total_accuracy += (accuracy * len(batch_x))
return total_accuracy / num_examples
# 建立各Saver对象用于训练完成后保存模型。
saver = tf.train.Saver()
5. 训练模型
训练的过程就是在batch上不断调用优化器优化cost的过程。用到的API:
tf.Session()
tf.global_variables_initializer()
tf.Session.run()
tf.train.Saver.save()
# 用于在每次epoch中shuffle数据集
from sklearn.utils import shuffle
# 记录每次训练后batch上的cost值
cost = []
# 记录训练完一个epoch后,在整个数据集上的cost。
cost_epoch = []
# keep_prob
# 训练时dropout的概率,卷积层不dropout
k = [1.,1.,1.,0.4,0.5]
with tf.Session() as sess:
# 可别忘了初始化全局变量
sess.run(tf.global_variables_initializer())
num_examples = len(X_train_norm)
print("Training...")
print()
for i in range(EPOCHS):
# 这里shuffle的数据集。感觉弄一个数据集的索引列表,
# shuffle该列表应该快一些。
X_train_norm, y_train = shuffle(X_train_norm, y_train)
for offset in range(0, num_examples, BATCH_SIZE):
end = offset + BATCH_SIZE
# 在numpy中不用担心索引超出数组边界。
batch_x, batch_y = X_train_norm[offset:end], y_train[offset:end]
sess.run(training_operation, feed_dict={x: batch_x, y: batch_y, keep_prob: k})
loss = sess.run(loss_operation, feed_dict={x: batch_x, y: batch_y, keep_prob: [1.0,1.0,1.0,1.0,1.0]})
cost.append(loss)
loss = sess.run(loss_operation, feed_dict={x: X_train_norm, y: y_train, keep_prob: [1.0,1.0,1.0,1.0,1.0]})
cost_epoch.append(loss)
# 分别在训练、测试集上评估正确率。
train_accuracy = evaluate(X_train_norm, y_train)
validation_accuracy = evaluate(X_valid_norm, y_valid)
print("EPOCH {} ...".format(i+1))
print("Train Accuracy = {:.5f}".format(train_accuracy))
print("Validation Accuracy = {:.5f}".format(validation_accuracy))
print()
# 保存训练好的模型
saver.save(sess, './model/model.ckpt')
print("Model saved")
运行上面的代码,就开始训练模型了。从第十几个epoch开始,在验证集上的正确率就稳定在96.x%了。在训练集上都是99.9x%。过拟合还是很严重的,多使用些方法做data augment会降低过拟合。
注意,在退出上下文管理器tf.Session()后,该会话就关闭了,该会话所拥有的变量的值也就被释放了。但是没关系,已经将训练好的模型保存到了文件中。
下面画出的是列表cost,也就是每个batch后的cost值,可看到mini-batch gradient descent的特点:
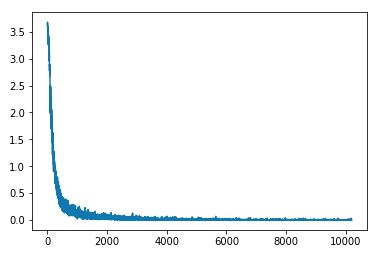
下面画出的是列表cost_epoch,也就是每个epoch后的cost值:
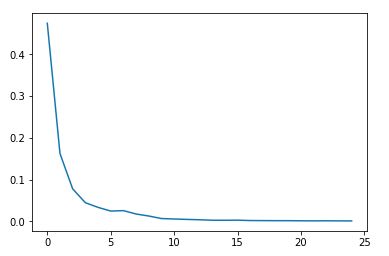
6. 评估测试集
下面就要在测试集上评估模型的性能了。用到的API:
tf.train.Saver.restore()
with tf.Session() as sess:
# restore的过程就相当于将保存的训练好的模型加载到当前graph中
# 构建好的结构中。在这一过程中,各变量的值都被初始化为保存好的
# 变量的值。
# 也就不需要再调用sess.run(tf.global_variables_initializer())了
saver.restore(sess, './model/model.ckpt')
test_accuracy = evaluate(X_test_norm, y_test)
print("Test Accuracy = {:.3f}".format(test_accuracy))
模型在测试集上的精度可达到0.943。
7. 观看网络状态
下面的函数可以画出对于某张图片,网络各层的输出。将输出形式化的显示。只是最基本的显示,只能对第一层卷积的输出有比较好的观察。
下面函数的一个输入要求传递的是网络中某一层(要看的那一层)激励函数的输出Tensor对象。但有个问题是,我是通过函数来搭建网络结构的,函数只是输出了网络输出层的Tensor。对于在函数中使用的conv1、conv2等变量无法再引用了。
但这没关系,因为搭建的这些Tensor和Operation都存在于Graph中,由于没有显式创建Graph对象,所以TensorFlow自动创建了个default graph。通过查看tf.Graph文档,可发现其有个get_operations()方法可以返回图上所有的Operation对象。
但我们现在需要的是激励函数创建的Tensor,能不能得到图上所有的Tensor对象呢?很遗憾,没有这样的API。但是没关系,找到了Operation,就可以找到其输出的Tensor。因为Tensor对象的命名方式是 “op:num”,就是产生该Tensor的Operation名,后面接该Tensor来自Operation的第几个输出。
这就好办了,可先通过tf.get_default_graph()得到默认的图对象,再通过tf.Graph.get_operations()得到图上的所有Operation,因为在调用激励函数leaky_relu时我给了名字,比如'conv1_out',所以可以通过这个来查看。
但查找的时候发现和我预想的不一样,没有名字为'conv1_out'的Operation对象,但有三个类似的:
,
,
,
这三个应该是在进行leaky_relu运算中的三个操作,我猜测找的应该是
所以对应的Tensor对象名就为'conv1_out/Maximum:0',再使用tf.get_default_graph().get_tensor_by_name得到该Tensor对象,这样的话可以使用下面代码来得到该Tensor对象。
tf.get_default_graph().get_tensor_by_name('conv1_out/Maximum:0')
# 结果为:
还有另一方法可得到该Tensor对象,因为tf.Operation类中有个属性,outputs,保存的是该op输出的Tensor对象列表。所以可以使用tf.get_default_graph().get_operation_by_name('conv1_out/Maximum')得到该Operation对象后,再访问outputs属性来得到目标Tensor对象。即:
tf.get_default_graph().get_operation_by_name('conv1_out/Maximum').outputs
# 结果为
可见二者是一样的。
说了这么多,终于到了显示网络状态的函数了,其实很简单,就是在Session中,对网络传入图片前向传播,将某层激励函数的输出都当做灰度图像显示。比如第一个卷积层输出了16个channel,那么就将这16个channel都当做灰度图片显示。代码如下:
# image_input为四维(batch, img_weight, img_height, channel)
# tf_activation就是激励函数输出的Tensor
# activation_min、activation_max、plt_num是对matplotlib显示图片的控制,不用管,使用默认值就好
# i指出使用image_input中的第几个图片
# 该函数要在Session会话中调用。
def outputFeatures(image_input, tf_activation, activation_min=-1, activation_max=-1 ,plt_num=1, i=0):
activation = tf_activation.eval(session=sess,feed_dict={x : image_input, keep_prob: [1.0,1.0,1.0,1.0,1.0]})
# 得到激励函数输出的channel数
featuremaps = activation.shape[3]
plt.figure(plt_num, figsize=(15,5))
for featuremap in range(featuremaps):
# 我这里看的是第一层卷积的输出,共有16个channel
# 所以这里subplot是2x8,如果是其他数目的channel需要修改
plt.subplot(2,8, featuremap+1) # sets the number of feature maps to show on each row and column
plt.title('FeatureMap ' + str(featuremap)) # displays the feature map number
if activation_min != -1 & activation_max != -1:
plt.imshow(activation[i,:,:, featuremap], interpolation="nearest", vmin =activation_min, vmax=activation_max, cmap="gray")
elif activation_max != -1:
plt.imshow(activation[i,:,:, featuremap], interpolation="nearest", vmax=activation_max, cmap="gray")
elif activation_min !=-1:
plt.imshow(activation[i,:,:, featuremap], interpolation="nearest", vmin=activation_min, cmap="gray")
else:
plt.imshow(activation[i,:,:, featuremap], interpolation="nearest", cmap="gray")
调用该函数显示第一层卷积的输出:
with tf.Session() as sess:
saver.restore(sess, './model/model.ckpt')
outputFeatures(im, tf.get_default_graph().get_tensor_by_name('conv1_out/Maximum:0'), i=8)
我上面的i=8,显示索引为8的图片,该图片本身为:
第一层卷积输出的16个channel显示如下:

下面再给些其他图片的结果: