AfterShip 自 2012 年成立以来,每年业务都可实现 100% 的复合增长。对于这家公司来说,组建团队是一件更重要的事情,并且尤为重视工程师团队文化的建设,他们推崇团队文化多元化及相互包容性,并要求团队每个人都要懂产品以及客户。
因此对于 AfterShip 来说,做好新员工培训成为了一场重要的“战役”。今天,AfterShip CTO & TGO 鲲鹏会会员洪小军,及其 AfterShip 的廖国添将分享每年营收翻倍的全球化 SaaS 公司 AfterShip 是如何体系化地做新员工培训的经验。
快速发展阶段的公司寻求快速、灵活和实用,AfterShip 新员工培训从启动到正式开始培训,前后总共是 2 周时间,期望分享一下在这个过程中的思考和实践。
为了帮助大家更好地了解培训主线,我们将培训整体内容分为了 6 个环节:
Day1:了解公司当前具体情况;
Day2:效率工具实战;
Day3:基于 Scrum 的敏捷开发实践;
Day4:项目实战 - 系统设计;
Day5:项目实战 - 流程和开发;
Day6:项目实战 - 系统发布。
前两日,我们已经将《每年营收翻倍的 AfterShip 是如何体系化做新员工培训(上)https://gocn.vip/topics/10120》发布,错过的小伙伴赶紧点击链接阅读吧。今天,我们来讲述下篇的内容。以下,Enjoy:
Day3:基于 Scrum 的敏捷开发实践
这个环节的关键目标是:
理解基于 Scrum 的完整开发流程;
理解公司和团队的 OKR;
理解产品需求和清楚如何进一步做分析。
这个环节由产品经理主导,产品经理将会为此针对性的设计业务需求,并写成产品 PRD 文档。
在开始环节,产品经理将与参会者一起探讨产品需求,产品需求的探讨是整个研发生命周期中非常关键的环节,AfterShip 提倡大家在深入理解产品需求后才继续下一步的工作。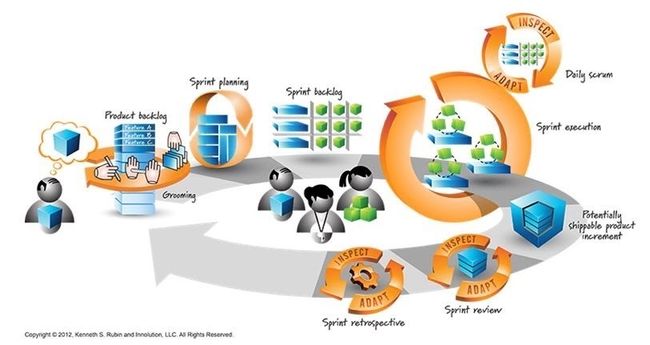
AfterShip 的项目中采用 SCRUM 的方式运转,两周一个 Sprint 迭代周期,每个迭代周期会有以下几个关键环节:
1、需求池管理:
AfterShip 使用 Jira 做项目和任务管理,产品经理将业务需求按照 Story 的方式写到 Jira Backlog 中,形成产品的需求池。任何人也可以在任何时候将需要做的事项写入到 backlog 中,包括但不限于产品需求建议、客户建议、Bug、技术改进事项等;
2、Grooming 会议:
确定这个 Sprint 的交付目标,从 Backlog 中选取相应的 Story,按照适合的粒度拆解 Story,同时进一步分析评估工作量,当前 AfterShip 基于 Planitpoker 来做点数评估;
3、每日早会:
每个团队会有 10-15 分钟的早会,每个人基于 Jira Board 简要介绍上一个工作日所做事项,会议的重点是集中探讨项目运转过程中碰到的问题。AfterShip 要求每个事项都要写到 Jira 中,包括每个事项的进展情况需要及时 Comment,养成这样的做事方式,也很利于跨区域的团队沟通协作。前一段时间因为疫情的原因,公司全员远程办公,从结果来看,整体沟通成本不会差异太多;
4、Sprint Review:
每个 Sprint 完成后,会召集所有相关的同事做一次 Sprint Review,包括技术支持团队和售前团队。Sprint Review 主要演示过去一个 Sprint 中所做的事项,大家也可以提一些改进建议;
5、OKR Review:
公司采用 OKR 的方式,每个 Sprint Review 的同时也会简要对一下 OKR,以确定目标完成情况及其是否有碰到问题,确保整体朝着预定方向运转。如果有发现目标变化,也会尽早识别并及时调整;
6、Retrospectives:
Sprint Review 结束后项目组人员留下来做 Retrospectives。AfterShip 使用 Funretro 来做这项工作,团队的每个人会写出过去一个 Sprint 中做得好及其需要改进的事项,包括团队、项目及其任何方面。完成之后将进入投票环节,每个人有 6 个选票,最终选择 2-3 个关键事项作为下一个 Sprint 要重点解决的,并写成 Jira Ticket 来跟进确保目标达成。
在新员工培训的这个环节中,产品经理会带着大家来完整体验这个过程,包括相关工具的使用演示。

Day4:项目实战 - 系统设计
这个环节的关键目标是:
如何做整体性的设计;
如何做 API 和 DB 设计。
AfterShip 有定义统一的系统架构设计模板,期望新开发的系统默认基于这个模板来做系统整体设计,在设计完成后会将先做一次设计方案 Review,确保在业务和技术目标上达成共识。
AfterShip 对于系统部署的层次结构也有清晰的定义,附上一个简化的版本: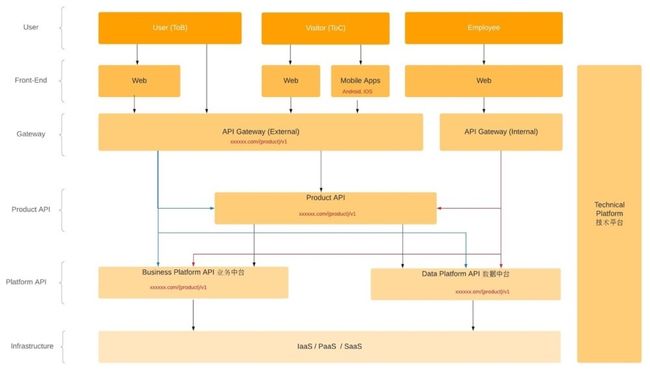
API 设计方面,AfterShip 在 API 设计上会有很明确的要求,需要很好的遵循 Restful 设计风格,并且语义定义上要足够的清晰。
原因也很简单,公司有可能随时开放 API 给客户使用,包括 API 也需要严格保持前后版本的兼容性,所以稳定的、语义清晰的 Restful 风格 API 尤其重要。
为此,公司也定义了专门和详细的 API 设计 Guideline 供设计时参考和借鉴。AfterShip 采用 Stoplight 来做 API 的管理,通过 Stoplight 也能做到更加高效的协作和沟通。
在这个环节里,更多会去体现公司所提倡的产品和设计先行的理念,也会尽可能多的提供各方面的模板和 Guideline 去帮助大家去做好这项工作。
Day5:项目实战 - 流程和开发
这个环节的关键目标是:
如何保证在研发流程上的更高效率;
如何保证更高的质量;
如何开发一款面向全球客户的产品。
在开始这部分工作之前,每个人会先准备好一个 Demo 项目,能基于公司现有技术体系之上跑起来的 Demo 项目。
AfterShip 没有设置单独的测试岗位,但是也期望保持很高质量的系统交付,对于很多新人来说这是一道坎。要达到这样的效果,需要在代码规范、Code Review、单元测试和集成测试方面做细做好,基于此公司在 TDD 和 BDD 方面也做了大量的实践和应用。
代码分支管理和部署环境管理,同样也是作为新人很关注的议题。AfterShip 从环境层面来看,分成开发环境、测试环境、Release 环境、预上线环境和线上环境,通过不同域名的方式来区分不同的环境,这在内部沟通和协作方面也有明显的好处。
开发一款面向全球客户的产品,有很多事项需要特别注意,比如多语言、多时区和多货币等;在安全隐私保护方面,面向欧美国家需要研究清楚 GDPR 和 CCPA,包括 AfterShip 已经通过的 ISO 27001 等的认证体系,也都需要严格遵循。
在这个环节中,重点期望大家能清楚有什么潜在的注意事项及其痛点,包括了解相应的最佳实践。
Day6:项目实战 - 系统发布
这个环节的关键目标是:
学习掌握发布流程及发布原则;
学习掌握监控告警机制;
学习掌握故障处理原则及流程。
AfterShip 使用一系列 SaaS 服务来快速搭建自动化的监控体系:
使用 New Relic 作为 APM 和分布式 Trace 系统;
使用 Pingdom 做系统运行状况的监测;
使用 PagerDuty 做报警;
使用 Grafana 在部分场景里做报表展示和监控;
使用 Statuspage.io 发布系统故障时的变更通知,以便客户可以快速了解到信息。
基于这个体系还有个很大的好处是,互相之间可以做简单和快速的集成,包括与公司所使用的 Slack、JIRA 等系统打通,能很方便的实现整体的自动化。
在此基础上,AfterShip 也搭建了一系列配套服务来达到更加的自动化。
比如我们期望能有一个统一的地方去获取到系统所有的发布变更通知,包括代码层面变更,以及各类系统变更(比如数据库、配置变更等)。
公司前端同事自发利用业余时间开发了一套 Release 系统,Release 系统会汇总所有的变更信息,有统一的 Dashboard 展示所有变更信息,有新变更也会实时同步到 Slack(公司使用 Slack 作为通讯工具)。
Release 系统通过对接发布系统( AfterShip 主体使用 Jenkins )实现了自动化的录入发布变更信息到系统中,系统同时也支持手工录入的方式(比如数据库变更)。
基于此,AfterShip 也定义了统一的 Release Log 格式。有了这套系统,当线上系统出现问题时,能比较方便的第一时间确定是否由于变更引起,对于问题排查能起到不少的帮助作用,毕竟变更是故障产生的关键影响因素之一。
我们期望公司全方面尽量做到更加简单和自动化,也很提倡大家朝着这个方向去努力。
对于构建高可用的系统,需要首先清楚有哪些方面的影响因素,进而针对性的去处理。
在此方面,AfterShip 也专门梳理总结了一系列 Checklist,比如对于系统设计阶段、系统发布前和发布后需要注意哪些事项。期望帮助大家做好自检,同时也不断去提升大家在这方面的认知和能力。
以下为系统发布之前的 Checklist:
以下为系统发布之后的 Checklist:
公司也制定了故障管理制度,在故障处理方面,采用 5-13 原则,期望至少在 5 分钟内感知到故障发生并且开始进行线上操作,需要能在 13 分钟内完成故障的处理和服务的恢复。
当然,这是考虑到各种场景之下的基线值,比如半夜收到报警快速的开机连接到系统等的场景。提倡先快速解决问题,不管使用什么方式,扩容、回滚或者其他尽可能快的方式。
所有人都不期望故障的发生,但是故障很难完全避免。本着“从故障中学习,不再犯第二次错误,尽量少出故障,出现故障尽早恢复”的原则,鼓励团队从故障中学习和成长,所以也设定故障奖罚机制。奖惩不是目的,而是期望未来能不断做得更好。
公司会奖励在工具建设和乐于助人等方面有突出表现的团队和个人,同时也会基于故障制度会有一些惩罚机制,惩罚的方式为根据故障的级别不同去做不同工作量的工具系统建设,通过工具建设实现整体的更加自动化。
经验总结
基于以上内容,我做了一个简单的经验总结:
第一,新员工培训从正式启动立项到开始进行培训.
刚好也是在一个 Sprint 的时间内(2 周内)。这个过程也很辛苦各位组织者和讲师,需要在日常工作之外去很好落实这个事情,这是 1.0 的版本,快速发展阶段的公司先做比起一开始就想做得很好重要很多,也期待接下来的 2.0 和 3.0 版本能做得更好。
第二,整个过程会需要耗费大家一定的时间精力.
包括组织人员、讲师和新同事的时间投入。因此,为了让这个活动产生更直接和更大的价值,我们需要不断地探索,并及时做一些适当的调整。比如这个活动里,如何把所有环节有机连接起来,也是需要持续打磨好。
第三,WorkShop 的方式对于讲师来说也是一个不小的挑战.
因为他不仅是一个分享者,更是一个引导者,他需要不断地引导大家去思考和实践。原计划期望是所有的环节都基于 WorkShop 的方式进行,但是在具体的执行过程中,也适当做了折中,我们也是推崇 2-8 原则,先利用 20% 的时间做好 80% 的事情,后续可以再不断迭代优化。
第四,参加者的反馈很重要。
因此,我们会让每位参与者提交反馈,让组织者更清晰知道做得好和做得不好的地方,这样在下一期的活动中才能加以改进,做得更好。
第五,在业务快速发展过程中的团队,不仅需要权衡好业务发展和人员成长方面的平衡,而且要帮助现有业务快速发展,还要从中长期发展角度来做好成长体系。
这时,难免会产生一定的冲突和挑战,所以我们需要尽可能地维持平衡,这是非常重要的一点。
最后,以上每个环节的详细介绍,基于篇幅的原因,主要以几个关键点简要说明,也希望能有更多的机会与大家一起来更加深入的沟通和交流。