最近更新:2018-02-08
1.目标站点分析
2.页面分析
3."猫眼电影定向爬虫"实例数据解析
4.最终的代码
5.最终显示的结果:
注意:这篇文章的代码时根据Requests+正则表达式爬取猫眼电影Top100(一)以及"淘宝商品信息定向爬虫"实例的代码参考写的,多发散思维,学以致用.
1.目标站点分析
1.1爬取的内容
- 爬取的链接:猫眼电影
- 目标:爬取top100电影中的每一个电影包含排名/电影图片/电影名称/主演/上映时间/评分
- 理解:猫眼翻页的搜索接口,翻页的处理
- 技术路线:requests-re
1.2翻页链接的分析
第一页:http://maoyan.com/board/4
第二页:http://maoyan.com/board/10
第三页:http://maoyan.com/board/4?offset=20
第i页:http://maoyan.com/board/4?offset=10(i-1)
1.3定向爬虫的可行性
作为爬虫要确认猫眼是否允许用户在网页信息上爬取相关信息,因此要查看猫眼的robots协议:
http://maoyan.com/robots.txt

由图片可得到,猫眼允许任何的爬虫可进行爬取.
1.4程序的结构设计
- 步骤一:提交猫眼排名的搜索请求,循环获取页面
- 步骤二:对于每一个页面,提取猫眼电影的排名/电影图片/电影名称/主演/上映时间/评分
- 步骤三将信息输出屏幕并进行保存
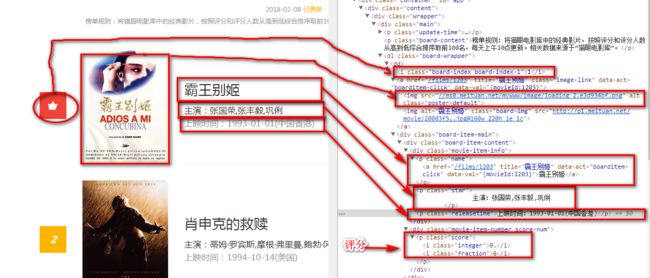
2.页面分析
2.1页面源代码
3."猫眼电影定向爬虫"实例数据解析
3.1getHTMLText(url)
getHTMLText这个是获得页面的函数.
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
3.2parsePage(ilt,html)
getHTMLText解析页面的数据.
def parsePage(ilt,html):
try:
indexs=re.findall('(.*?)',html,re.S)
images=re.findall('(.*?)',html)
stars=re.findall('"star">(.*?)',html,re.S)
releasetimes=re.findall('"releasetime">(.*?)',html,re.S)
score1s=re.findall('class="integer">(.*?)',html)
score2s=re.findall('class="fraction">(.*?)',html)
for i in range(len(indexs)):
index=indexs[i]
image=images[i]
title=titles[i]
star=stars[i].strip()[3:]
releasetime=releasetimes[i][5:]
score=score1s[i]+score2s[i]
ilt.append([index,image,title,star,releasetime,score])
except:
print("")
- indexs=re.findall('

- images=re.findall('

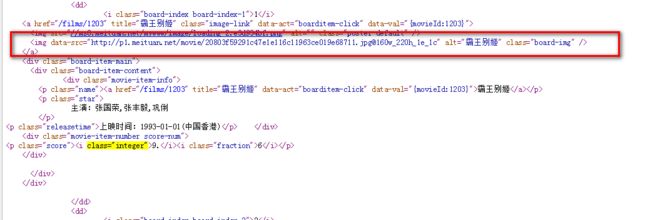
- titles=re.findall('
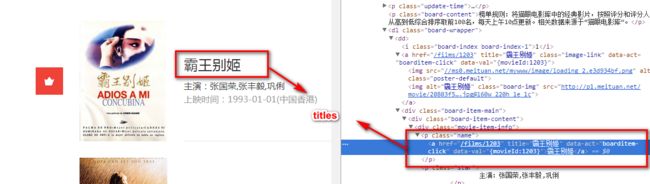
-
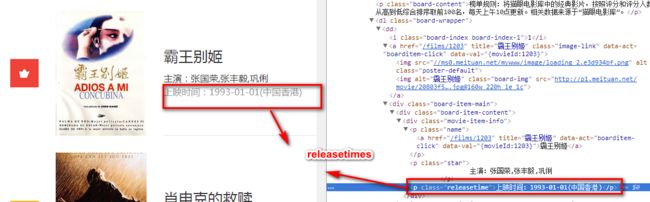
stars=re.findall('"star">(.*?)
',html,re.S)
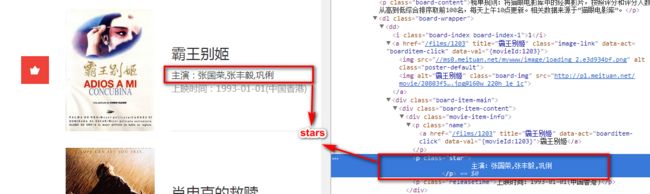
-
releasetimes=re.findall('"releasetime">(.*?)
',html,re.S)
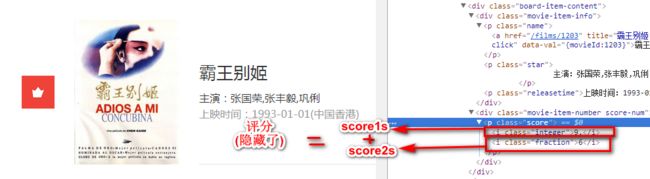
- score1s=re.findall('class="integer">(.?)',html)
score2s=re.findall('class="fraction">(.?)',html)
for i in range(len(indexs)): index=indexs[i] image=images[i] title=titles[i] star=stars[i].strip()[3:] releasetime=releasetimes[i][5:] score=score1s[i]+score2s[i]
1 )index=indexs[i]/image=images[i]/title=titles[i]提取列表的元素
2 )star=stars[i].strip()[3:],如截图,数据里面包含空格,故需要用strip()将空格去掉,而提取的数据是主演:XXX明星,只要求提取XXX明星即可,故从3位置切片,从而是[3:]
3 ) releasetime=releasetimes[i][5:]
理由通2)数据有空格,并将上映时间:这个字符切掉.
4 )score=score1s[i]+score2s[i]

5)ilt.append([index,image,title,star,releasetime,score])
将数据添加到列表
3.3printGoodsList(ilt):
这个是将淘宝信息输入到屏幕上
tplt="{:3}\t{:20}\t{:16}\t{:10}\t{:10}\t{:6}"
print(tplt.format("排名","图片","电影名","主演","上映时间","评分"))
for g in ilt:
print(tplt.format(g[0],g[1],g[2],g[3],g[4],g[5]))
print("")
3.4write_to_file(infoList)
是将文件以json格式储存
def write_to_file(infoList):
with open("result.txt","a",encoding="utf-8") as f:
f.write(json.dumps(infoList,ensure_ascii=False) + "\n")
f.close()
3.5main()
这个是主程序,记录程序运行的相关过程
def main():
start_url='https://maoyan.com/board/4'
infoList=[]
i=0
for i in range(10):
try:
url='https://maoyan.com/board/4?offset='+str(10*i)
html=get_maoyan(url)
parsePage(infoList,html)
except:
continue
printGoodsList(infoList)
write_to_file(infoList)
- infoList=[]对输出结果定义一个变量
- 当所有的页面信息解析之后,通过 printGoodsList将信息打印出啦,这里的信息是保持在infoList
- 通过for循环的方式,对每一个页面进行访问.
- get_maoyan获得网页源代码
- parsePage获得页面的解析
4.0最终的代码
import requests
import re
import json
#传入 URL ,通过 requests 库获取其 html 代码
def get_maoyan(url):
r=requests.get(url)
r.raise_for_status()
return r.text
def parsePage(ilt,html):
try:
indexs=re.findall('(.*?)',html,re.S)
images=re.findall('(.*?)',html)
stars=re.findall('"star">(.*?)',html,re.S)
releasetimes=re.findall('"releasetime">(.*?)',html,re.S)
score1s=re.findall('class="integer">(.*?)',html)
score2s=re.findall('class="fraction">(.*?)',html)
for i in range(len(indexs)):
index=indexs[i]
image=images[i]
title=titles[i]
star=stars[i].strip()[3:]
releasetime=releasetimes[i][5:]
score=score1s[i]+score2s[i]
ilt.append([index,image,title,star,releasetime,score])
except:
print("")
def printGoodsList(ilt):
tplt="{:3}\t{:20}\t{:16}\t{:10}\t{:10}\t{:6}"
print(tplt.format("排名","图片","电影名","主演","上映时间","评分"))
for g in ilt:
print(tplt.format(g[0],g[1],g[2],g[3],g[4],g[5]))
print("")
def write_to_file(infoList):
with open("result.txt","a",encoding="utf-8") as f:
f.write(json.dumps(infoList,ensure_ascii=False) + "\n")
f.close()
def main():
start_url='https://maoyan.com/board/4'
infoList=[]
i=0
for i in range(10):
try:
url='https://maoyan.com/board/4?offset='+str(10*i)
html=get_maoyan(url)
parsePage(infoList,html)
except:
continue
printGoodsList(infoList)
write_to_file(infoList)
if __name__ == '__main__':
main()
5.0最终显示的结果:
