参考:罗升阳的相关博客
https://blog.csdn.net/Luoshengyang/article/details/44513977
- 目录
BiBi - Android VM -0- 开篇
BiBi - Android VM -1- Dalvik
BiBi - Android VM -2- ART
BiBi - Android VM -3- Compacting GC
1. 简介
Android 4.4 中ART采用Mark-Sweep(MS)GC,到了Android 5.0,ART增加了对Compacting GC的支持,包括Semi-Space(SS)、Generational Semi-Space(GSS)和Mark-Compact (MC)三种。
-
Compacting GC 的定义
在进行GC的时候,同时对堆空间进行压缩,以消除碎片,因此它的堆空间利用率更高。
缺陷:对堆空间进行压缩,导致Compacting GC的GC效率不如Mark-Sweep GC。
解决:只要我们使用得恰当,是能够同时发挥Compacting GC和Mark-Sweep GC的长处的。例如,当Android应用程序被激活在前台运行时,就使用Mark-Sweep GC,而当Android应用程序回退到后台运行时,就使用Compacting GC。
优势:除了适合后台运行时之外,Compacting GC还适合用在内存分配时。在以往的Mark-Sweep GC时,由于碎片而产生的内存不足问题,是解决不了的,只能让应用程序OOM。但是有了Compacting GC之后,就可以在应用程序OOM之前,再作一次努力,那就是对原来的堆空间进行压缩一下,再尝试进行分配,这样就可以提高成功分配内存的概率。
ART运行时内部有Foreground和Background两种GC之分。由于Mark-Sweep GC和Compacting GC需要的堆空间结构是不一样的,因此,当发生Foreground GC和Background GC切换时,ART需要提供支持,以维护堆空间的正确性。
-
对象移动
Compacting GC的最大特点就是会对堆空间进行压缩,这意味着对象在堆空间的位置是会发生变化的。 一个对象被移动了,要保持它的使用者的正确性,无非就是两种方案:
第一种方案:使用者不是直接引用对象,而是间接引用。这就类似于操作系统里面的文件描述符。
否定原因:
(1)每次访问对象都需要有额外的开销,也就是影响效率。但是如果我们可以忽略在执行Compacting GC时的这个开销,是不是就可以使用了呢?答案是否定的。
(2)由于Foreground和Background两种GC的同时存在,ART内部可能同时存在着Mark-Sweep和Compacting两种类型的GC。如果我们在Compacting GC中使用了该方案,那么也意味着Mark-Sweep GC也必须是要间接地去访问对象,但是这完全是没有必要的。第二种方案:修改对象使用者的引用,使得它无论何时何地,总是直接指向对象的真实地址。
具体思路:对象使用者无非就是位于两个位置,一个是堆,一个栈。因此,当一个对象被移动时,我们只需要找到它在堆和栈上的使用者的位置,那就可以将它们的值修改为对象被移动后的新地址,那就达到目的了。
-
monitor_
32位的monitor_成员变量的责任重大,除了用来描述对象的Monitor和Hash Code信息外,还包括对象的移动信息。monitor_成员变量通过封装成一个LockWord对象来描述。
monitor_的高2位描述的是状态【包括kUnlocked、kThinLocked、kFatLocked、kHashCode和kForwardingAddress五种状态】,当monitor_的高2位值等于0x11时,表示它已经被移动过了,这时候它的低位30位描述的就是对象移动后的新地址。但30位够表示一个对象的地址吗?因为32位的体系架构中,内存的地址是32位的啊。答案是够的,对象的分配都是8字节对齐的,这意味着低3位都是0,因此这里用30位来描述对象的地址是足够的。
-
例子
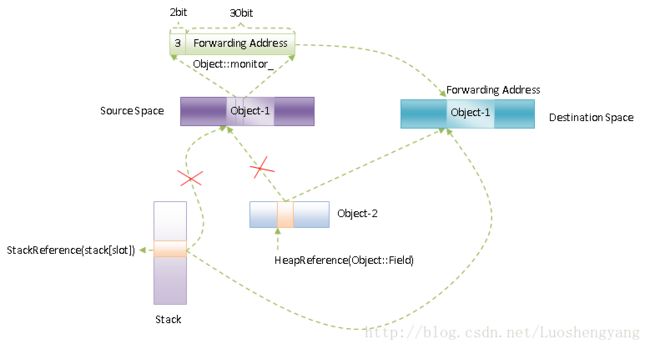
过程描述:
对象移动是发生在GC的过程中的,并且只有可达对象才需要移动,而可达对象都是从根集对象开始遍历的。假设Object-1是根集对象,并且是被栈上的slot引用。因此,当遍历到栈上的slot时,需要移动对象Object-1。这时候除了要将栈上的slot位置修改为Object-1在Destination Space上的位置之外,还需要将旧的Object-1【位于Source Space上】的成员变量monitor_的高2位设置为0x11,以及将低30位设置为新的Object-1【位于Destination Space上】的地址。
我们再假设Object-2是一个可达对象,也就是说在栈上的slot被遍历之后的某一个时候,Object-2也会被遍历。在遍历Object-2的时候,我们会检查它的每一个引用类型的成员变量。当检查到其引用了Object-1的成员变量的时候,会发现它旧的Object-1【位于Source Space上】的成员变量monitor_的高2位已经被设置为kForwardingAddress状态,因此就直接将其低30位的值取出来,并且设置为Object-2对应的成员变量的值。这样就可以保证Object-2和栈上的slot位置引用的都是新的Object-1了。
-
Bump Pointer Space
对象移动是发生在Bump Pointer的Space里面的,也就是图中From Space和Destination Space均为Bump Pointer Space。
Android 4.4 ART运行时用来分配对象的Space称为Dl Malloc Space,这是一个使用C库内存管理接口来分配和释放内存的Space。
Android 5.0 ART运行时引入的Bump Pointer Space不是通过C库内存管理接口来分配和释放内存的,这是由于在它上面分配的对象具有可移动的特性,因此,就使用了另外一种更加合适的内存管理方法。
不同的Compacting GC对Bump Pointer Space的使用是略有不同的,因此又可以分为:Semi-Space GC、Generational Semi-Space GC和Mark-Compact GC三种情况。
-
Semi-Space GC
由两个Bump Pointer Space组成。
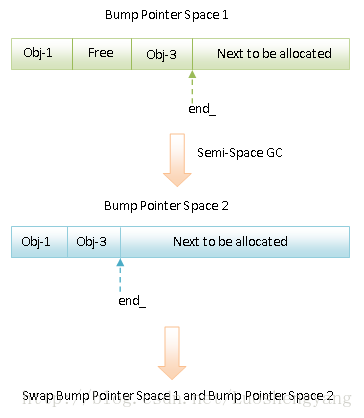
Bump Pointer Space 1和Bump Pointer Space 2分别称为From Space和To Space。其中,对象的分配发生在From Space中。在Bump Pointer Space中,有一个指针end_,始终指向下一次要分配的内存块的起始地址。因此,在Bump Pointer Space上分配内存很简单,只要前指针end_向前移动指定的大小即可。这也是Bump Pointer的由来。
当From Space不能满足内存分配要求时,就会触发一次Semi-Space GC,结果就是From Space和To Space互换了位置,并且原来在From Space上的Live Object按地址值从小到大的顺序移动到了原来的To Space上去。
-
Generational Semi-Space GC
由两个Bump Pointer Space 和一个是Promote Space【对象不移动】组成。
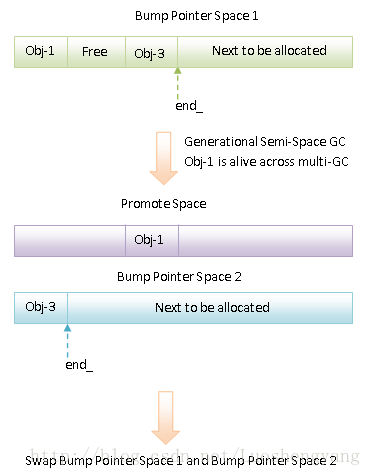
Generational Semi-Space GC与Semi-Space GC是基本相同的,只不过它在移动对象时,会考虑到对象的年龄。如果一个对象在多次GC中都能存活下来,那么就会将它移动到一个Promote Space中去。这是因为时间局部性原理,一个对象如果在前面几次GC中都能存活下来,那么它在下一次GC中也很有可能是存活的。因此,就把它移动到一个Promote Space中去。由于Promote Space是一个Non-Moving Space,因此以后在这个Space上的对象不会再被移动。通过这种方式,就可以有效地减少在Generational Semi-Space GC中要移动的对象的个数,从而提高GC效率。
-
Mark-Compact GC
由一个Bump Pointer Space 组成。
在执行Mark-Compact GC时,所有存活的对象都被移动到了另外一端,通过这种方式就达到压缩的效果。
-
Ros Alloc
Android 5.0 ART运行时还引进了另外一种称为Ros Alloc的Space。 Ros Alloc Space与Dl Malloc Space类似,都是用来分配不可移动对象的。但是Ros Alloc Space不像Dl Malloc Space一样使用C库内存管理接口来分配和释放内存,而是采用一种称为Ros(Runs-of-slots)的接口来进行内存分配和释放。
Ros算法其实与Linux内核使用的SLAB算法类似,它们的核心思想都是将内存分为若干个Bucket,每一个Bucket都管理着相同大小的内存块。这样在分配内存时,就会先根据要分配的内存大小找到最合适的Bucket,然后再从这个Bucket找到一块空闲的内存进行分配。这是一种Best Fit分配策略,好处是可以将大小相同的对象集中在一起分配,这样可以有效地减少内存碎片。