本文共计约七千字,读完大概需要20分钟。
谨以此文献给我的26岁生日和这片土地。
一、背景介绍
山东省既是总GDP名列中国第三的经济大省、人口过亿的人口大省,也是能源消耗大省、大气污染物排放大省。根据2018年《中国能源统计年鉴》、《中国环境统计年鉴》,山东省工业+居民生活所消耗的能源,换算成标准煤约为4亿吨,排名全国第一。与之对应的,是山东省排名全国第一的工业废气排放量。以二氧化硫(SO2) 为例,2018年山东省工业二氧化硫排放量超过了120万吨。是因为山东省的经济结构以国企重工业为主,偏重于化工业、重金属冶炼业、矿产开采等。因此山东省在京津冀区域性空气污染中发挥的作用也引起了中央政府的注意,鲁西北的传统重工业城市被列为京津冀大气污染传输通道(济南、淄博等)。
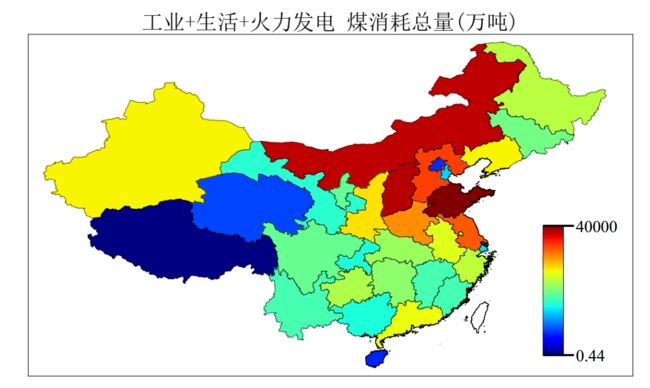
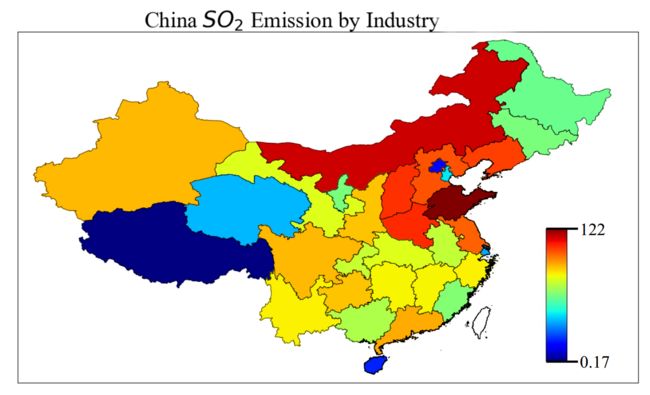
由于京津冀空气污染区域联防政策波及,2018年11月,山东省人民政府印发《关于加快七大高耗能行业高质量发展的实施方案的通知》,提出到 2020年要实现新旧动能的转换,重点化解钢铁、煤炭、电解铝、火电、建材等行业过剩产能。其中要求力争用5年左右时间,大幅压减、转移京津冀大气污染传输通道城市的钢铁产能。目前山东省具有日照钢铁、山钢日照、青岛特钢、山钢莱钢、山钢永锋钢铁、青岛特钢、潍坊特钢等22家钢企,2018年粗钢产量超过7000万吨。山东省目前制定的计划是,在确保日照、青岛、临沂和莱芜、泰安空气质量完成国家和省下达目标的基础上,将目前分散在12个市的钢铁企业和钢铁产能,逐步向日照-临沂沿海和莱芜—泰安内陆生产基地转移。到2025年,青岛董家口、日照岚山、临沂临港等沿海地区钢铁产能占比提升到70%以上。
日照市位于中国东部沿海主轴线与新亚欧大陆桥的交汇处、环渤海经济圈与长三角经济圈的结合部,因此是一带一路的重要节点。2025年山东省将有共计8000万吨钢铁产能,其中有一半布局在日照。根据《日照市钢铁及配套产业提升计划实施方案(2017—2021年)》, 全市规模以上钢铁及配套企业16家, 2020 年钢铁产能达到 4800 万吨,总产值突破万亿。而按照山东省“十三五减排计划”,至 2020 年日照空气质量 PM2.5 年均浓度必须控制在 35 µg/m3以下。 如何充分利用最新的、科学的技术手段,转变环保管理模式,提高环境管理和服务的效率是当前污染防治和大气保护发展的迫切需求。本文利用机器学习中流行的随机森林算法,选择网络公开发布的历史数据,以2013年-2017年数据为训练集,以2018-2019年数据为未知的测试集,预测日照市空气污染物浓度,解析控制其变化的主要影响因子,并给出AQI决策树的判定阈值。本文为追求可解释性,所用模型较为简单,存在一定的分析误差,特此说明,仅供参考(模型的不确定性分析见下文的方法论部分)。
二、方法论
1. 原理与假设
日照市主要工业废气排放源是钢铁工业和化工业,且由于地处北方,冬季采暖期居民排放亦不容忽视。根据《中国能源统计年鉴》,钢铁工业所需能源主要是焦炭,约消耗了86%的焦炭,16%的煤,而焦炭又是从煤中经炼焦过程提炼。以2017年为例,对于山东省,煤消耗总量为40927万吨,焦炭消耗总量为3704万吨,焦炭消耗量约占煤消耗量的8%,所以钢铁工业的能源消耗量约为(换算为万吨标准煤)EC-ISF= 16%EC+8%86%*EC=23%EC,EC代表Energy Consumption (工业能耗),亦即约占五分之一的工业总能耗。故在此选取三个与工业排放的特征:EC_L, EC_H, EC_ISF。分别代表轻工业总能耗、重工业总能耗、钢铁行业的能耗。
特征工程:在机器学习里,特征可以理解为用以区分事物的突出特质,类似于自变量X。特征可以有成百上千个,用来预测一个因变量y。数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。特征工程目的是最大限度地从原始数据中提取有效特征以供算法和模型使用。“特征做不好,调参调到老,效果还不好”。
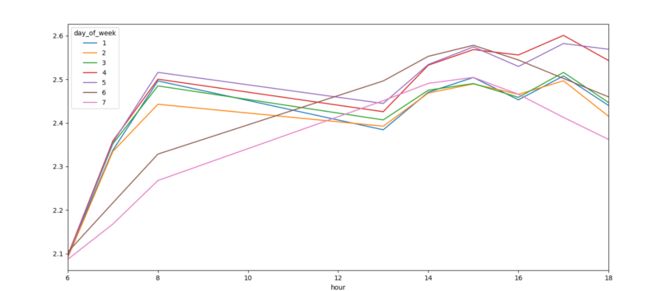
至于交通排放源,由于获得其排放源强极其困难,且面源随着时间变化较大,不稳定,难以量化。笔者认为交通排放源与时间相关,故只建立时间特征。根据常识,车流量在工作日是比较多的,而在一天之内,上下班高峰期也直接影响交通排放源强,而假期也是很影响大家的出行的。下图为典型的一周内不同时间段居民出行时间,来自于Github。可以看出,周六和周日的变化趋势是相似的,因为它们属于周末;而周一到周五变化趋势相同,因为他们属于工作日。而在周末中,周六的出行时间相对高一些,说明出行在周六更多一些;而在工作日,周五在下班时期出行时间要高一些,说明有一部分人需要往其他地方赶,比如北京的周五下班就有很多人往燕郊通州赶。所以把星期和小时作为一个组合特征比单独两个特征在模型里表现更好。在此,笔者把周1,2,3,4,5归为一类,周6,7归为一类;小时里也分两类为白天和夜晚,这样共有四个特征,编码为(0,0), (0,1), (1, 0), (1,1), 分表代表工作日的夜间、工作日的白天、周末的夜间、周末的白天。假期的编码就简单多了,以0,1编码即可,1为法定节假日,0为非假日。工具包见Github。
日照市属于北方沿海城市,其空气污染物的扩散与内陆情况不同,尤其是受海陆风环流的影响较大。海陆风对空气污染物的扩散影响体现在动力学和热力学两个方面(虽然二者经常耦合作用)。从单纯的动力学角度来讲,污染物从污染源排出后,通过陆风输送扩散到一定距离外,但是昼夜交替时,风向转换,扩散出去的污染物又被海风输送回源地附近,造成污染物的累积,使污染物浓度升高,污染加重。风向转换的时间可能不是恰好在傍晚和清晨。

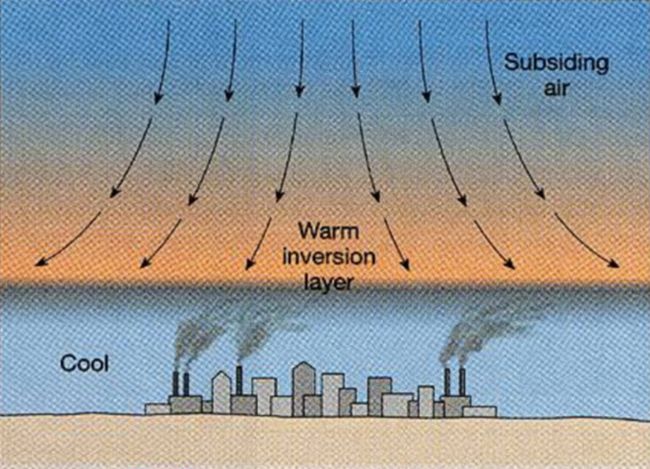
从热力学的角度来讲,海风带来的空气较为稳定,风向单一,利于空气污染物的长距离传输过程,倘若止于此,不会造成地面的污染物累积。但是陆地的地表粗糙度和海洋不同,地面受到长波辐射加热,形成的大气层不稳定,术语称之为“热内边界层”,使污染物更倾向于扩散至地面。如下图:

大气边界层内(1-2 公里高度以下)的气象因子之间具备一定的互斥性。气象因子随着高度增加而非线性变化:500 米以下为摩擦层,风、温、湿受到粗糙不平的地面的影响。污染物基本上在1500 米高度以下混合均匀。1500 米以上主要是自由大气,意思是不受地面加热造成的湍流和地表粗糙度的影响,主要受大尺度环流控制。如下图:
在海陆风环流较弱、无降水事件发生的前提下,大气颗粒物PM2.5浓度在地面的累积主要受夜边界层的控制,而污染物的扩散主要是白天地面加热引起的湍流造成。此时颗粒物浓度的昼夜变化特征和边界层的变化特征类似,极大值出现在早上06:00-8:00,这正是夜间边界层最强烈的时候。之后空气污染物扩散均匀,浓度逐渐下降。除了夜边界层带来的近地面逆温外,当大气边界层顶部出现逆温和下沉气流时,也会带来污染物的累积。
注: 逆温不利于污染物扩散的原理是冷空气密度大而下沉,暖空气密度小而上浮,逆温正好形成稳定的结构。但是这个原理必须在风速较小、无降水的情况下才能成立。
2. 数据与来源
(1)日照市轻重工业产值:日照市统计局月报(http://www.rztj.gov.cn/ctnlist.php/mid/)。
(2)日照市轻重工业能源消耗:日照统计年鉴(https://www.ceicdata.com/zh-hans/china/)。
(3)日照市地面观测气象数据(温、湿、压、风、云量、降水、能见度)来自NCDC(美国国家气候数据中心National Climatic Data Center)公开FTP服务器ftp://ftp.ncdc.noaa.gov/pub/data/noaa/isd-lite/,世界气象组织WHO的共享气象站(日照站ID = 549450) 。
(4)日照市高空再分析气象数据来自欧洲气象中心 (ECMWF) http://apps.ecmwf.int/datasets/ (ERA-interim 0.125°×0.125°)。再分析模型同化所采用的地面观测数据为上文提到的WHO共享气象站(日照站ID = 549450) 。提取日照市所在网格(边长约12-15公里)的1000-850 hPa(约0-1500 m)的风温廓线。
(5)日照市环境监测站发布的AQI数据,中国各城市AQI数据均已网络开源。取三个监测站均值。选取时间从2013年11月到2019年3月。
3. 模型的建立与不确定性
本文使用的机器学习工具包为Python语言的sklearn,特此向研发者致谢。
(1)模型选取
随机森林和决策树属于概率模型,概率模型不需要对原始数据进行归一化预处理,因为它们不关心变量的值,而是关心变量的分布和变量之间的条件概率。随机森林算法鉴于决策树容易过拟合的缺点,采用多个决策树的投票机制来改善决策树。如果用全样本去训练决策树显然是不可取的,全样本训练忽视了局部样本的规律,对于模型的泛化能力是有害的。随机森林是一个集成工具,它建立多个这样的决策树,然后将他们合并在一起以获得更准确和稳定的预测。 这样做最直接的好处是,在这一组独立的预测结果中,用投票方式得到一个最高投票结果,这个比单独使用最好模型预测的结果要好。
机器学习算法应用的原则是由简入繁、由浅入深,先试用简单的算法,检查结果是否可以进一步优化,再决定是否使用复杂的算法。笔者在使用随机森林之前,已经使用决策树回归,对上文提到公开历史数据提取的特征和目标变量AQI进行了拟合。下文是决策树在训练集和测试集上的表现随着深度的变化,可以看出,当决策树的深度大于6层时,虽然在训练集上的准确度接近于1,也就是完美,但是模型在测试集上的表现提升不明显,准确度为稳定在0.6到0.7之间。故决策树深度选择6-8之间是个明智的取舍。

(2)特征选取
决策树预测目标变量的方式,是通过询问一些关键特征,答案只需要两个结果:是或者不是,就能一步一步接近真相。比如,你根据一个班级体测结果判断某个同学是男生还是女生,第一个问题是身高,大于180 cm有很大概率是男生;第二个问题是体重,体重小于45kg的很大概率是女生。第三个问题可能是问100米成绩了。基本上3-4层决策树就能确定分类结果。这是分类问题,对于回归问题,比如预测AQI小时浓度,也是同样的道理,通过询问各个特征的值,大于/小于某个数时,空气污染物的浓度就大于/小于某个值。在一颗决策树里面,当因子分别到达某个阈值并且组合起来发挥作用时,空气污染物浓度便超环境健康限值。
经过数据探索,我选取19个特征,如下图。将其字符串格式的特征例如假期和工作日时间以0/1编码后,特征数变为为22个。
Features=['EC-L',
'EC-H',
'vacation',
'week_hour',
'AT',
'AP',
'RH',
'WS',
'WD',
'VIS',
'Prec',
'T_950',
'RH_950',
'U_950',
'V_950',
'T_850',
'RH_850',
'U_850',
'V_850']
要预测的目标变量如下:
Targets=['PM2.5','PM10','SO2','NO2','O3']
(3)模型不确定性分析
模型的不确定性一个来自数据方面,是对缺测值的暴力丢弃处理破坏了时间序列的连续性,对空气污染物异常值的忽视也会给模型带来很大误差。笔者认为,只要有一个变量缺测,该时间段的所有数据全部应该舍弃。例如,某个时间段的O3浓度因为仪器等原因缺测,那么所有的空气污染物浓度数据和气象数据均予以舍弃。对于异常值,目前流行的做法是取95%分位数的值,大于该值便舍弃,但是笔者没有这么做。一方面,空气污染物浓度的异常高值可能是重要的科学现象,另一方面,过于“干净”的数据在真实世界中并不存在,一旦用洁净的数据训练出了模型,放在真实世界中,可能不适用。经验丰富的数据科学家甚至会刻意的引入一些噪音数据。
模型的另一个不确定性来自于对决策树的修剪和信息熵的压缩。众所周知,人的大脑对于一个复杂信息的理解能力是有限的。语言学家指出,当一个句子超过四行,读者便没有兴趣读下去。对于一颗树来说,主干的粗壮比枝叶的繁茂更加重要。同样的道理,一个信息既要全面,又要简洁,这实际上是个权衡取舍难题。笔者对随机森林所得的决策树进行了剪枝处理,将其可视化,保留核心主干。在此过程中,可能会修剪掉一些关键的物理机制。
在信息论中,熵(entropy)是接收的每条消息中包含的信息的平均量,又被称为信息熵、信源熵、平均自信息量。这里,“消息”代表来自分布或数据流中的事件、样本或特征。
为了避免信息熵过大,笔者限制模型使用的最大特征数为15,限制决策树的最大深度为8,只保留最关键的特征和主干。参数的选取与个人经验有关。随机森林算法的其他参数较为复杂,与计算学有关,与科学关联甚少,概不赘述其参数优化过程。
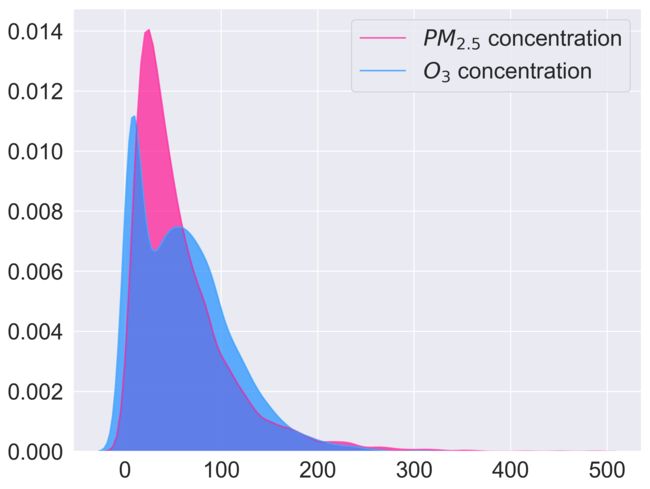
需要注意的是,臭氧的生成与消亡机制与颗粒物迥然不同。下图是日照市PM2.5和O3浓度的概率分布,可以看出,PM2.5是正常的单峰正态分布,而O3是反常的双峰分布。PM2.5的来源主要是地面源,所以从统计学理论上确实应该是正态分布,当然由于颗粒物爆发性增长,高值有些长尾分布。臭氧在0-80 µg/m3的第一个峰可以看作是标准正态分布,来源主要是地面排放的NO2、VOCs等前体物经光化学氧化而成。而在50 µg/m3左右出现了第二个峰,这个峰可能是其他过程的叠加效果。地面O3 浓度的升高可能来自高空向下的输送。现在夏季观测到的臭氧浓度高值是否可以称之为O3污染,是需要反复争吵辩论的。所以臭氧来源的复杂性也是模型不确定性来源之一。

本文的原理假设未考虑沙尘过程、工业脱硫设施的更新、汽车新国标的实施等关键因子,相应地,模型预测大颗粒PM10、二氧化硫SO2、二氧化氮NO2的表现不尽如意。
三、日照市2013-2019年空气污染特征分析
即使是采用机器学习这样的大杀器,对数据挖掘探索也是个不能免去的繁琐过程。这是进入决赛场之前必须的预(qian)赛(xi)。
1. 时间特征
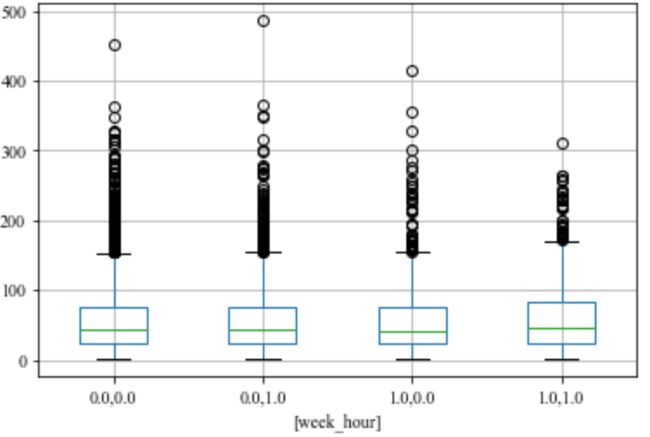
我们先探索要预测的因变量AQI。为节省篇幅,以PM2.5为例。方法论中提到过,我构建了几个和时间有关的特征。编码为(0,0), (0,1), (1, 0), (1,1), 分表代表工作日的夜间、工作日的白天、周末的夜间、周末的白天。从下图可以看出,对于日照市来说,周末的白天,大气颗粒物PM2.5平均浓度比其它的时间段平均浓度稍高,但是工作日出现较多极端高值。
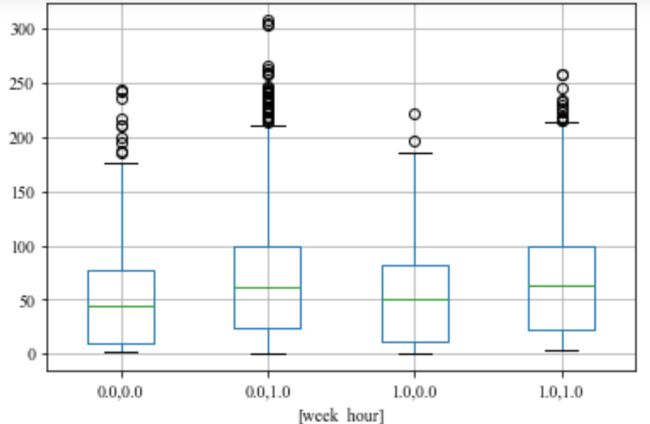
至于臭氧,平均浓度的大小顺序是:周末白天> 工作日白天> 周末白天> 工作日夜晚。起主要作用的是昼夜,工作日的作用较弱。这一点从臭氧的前体物之一NO2的变化也可以看出,工作日夜间NO2均值最高而O3浓度最低,而周末白天NO2浓度均值最低而O3浓度最高。这可能是因为臭氧的浓度变化和二氧化氮的浓度变化不是同步的,臭氧浓度在白天的增加需要前夜的前体物积累。

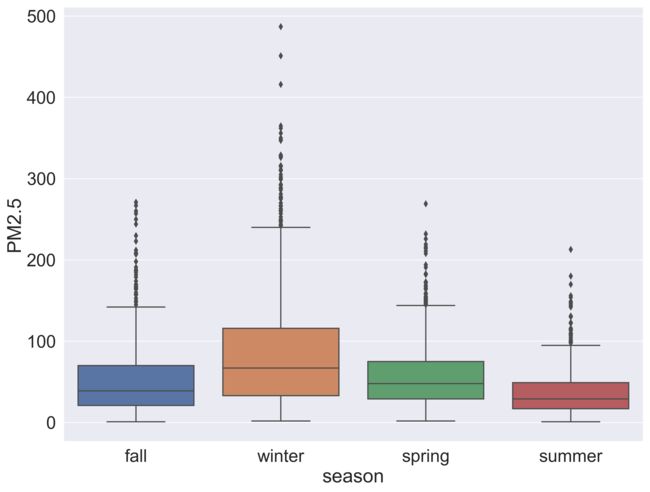
下面三张图是日照市PM2.5浓度的时间变化,分别是一周滑动平均、年均值、季节均值。注意2013年(只有11月-12月)和2019年(只有1-3月)数据不全,年均值只看2014-2018年即可。可以看出,由于“十二五”和“十三五”环保政策的实施,空气污染物年均浓度逐年下降的。

2. 非时间特征
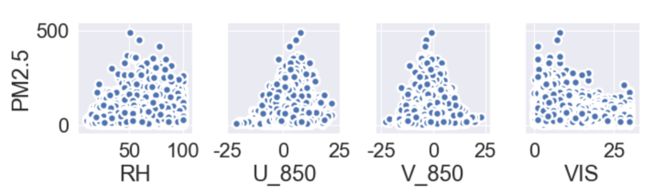
一开始根据常识,能见度、风、湿这几个气象因子容易和大气颗粒物浓度关联起来。在风速较小时污染物会累积,颗粒物经过米氏散射阳光,使能见度下降,但是在低云、海雾现象中水汽和液滴也会使能见度下降。从下图可以看出,PM2.5浓度峰值出现相对湿度50-70%、风速接近于0、能见度10公里左右。这说明海雾等现象对大气颗粒物浓度起到一定的增加作用。
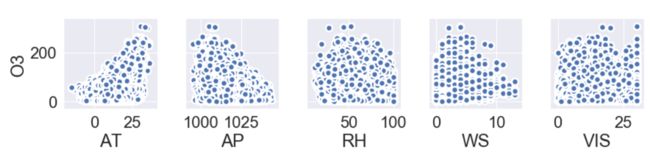
至于臭氧,从下图可以看出,其浓度高值发生在气温20摄氏度以上、低压气旋天气,而相对湿度和云雾低能见度天气的影响不明显,风速只有大于 6 m/s时才有可能起到清除臭氧的作用。高温低压上升气流反而会增加地面的臭氧浓度,这一点笔者表示十分疑惑。夏季低压一般带来阴雨天气,光化学氧化效应较弱,可能的解释是气旋破坏了稳定层结,使高空臭氧与近地面臭氧混合。另外,台风中心是上升气流,但是台风外侧却是辐合下沉气流。
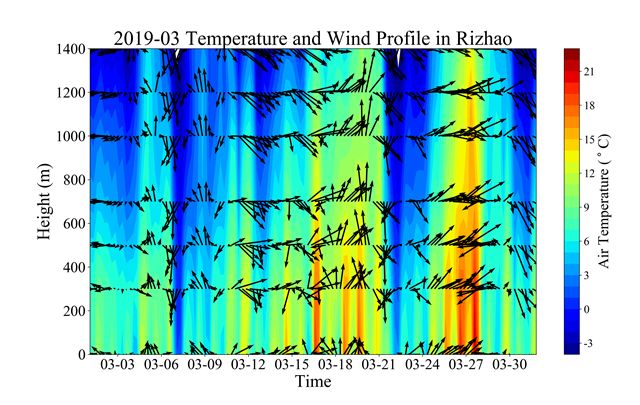
由于空气污染物的累积过程发生在整个大气边界层(1-2公里高度以下),单纯看地面的特征是不合适的,需要结合垂直廓线上的气象因子的分布。以2019年3月为例,3月上旬以颗粒物污染为主,3月中下旬以臭氧污染为主。从风温廓线可以看出,3月上旬日照市大气边界层内风速较小,偏静稳状态下颗粒物在近地面累积。而三月下旬风力增大,伴随着几次升温过程,颗粒物浓度下降,但是臭氧浓度的变化和气象因子关系不明显, 尤其是3月9日和3月22日的两次来自北方的冷空气过境,颗粒物浓度明显下降至40 µg/m3,但是臭氧浓度仍然上升至接近100 µg/m3,倒像是与时间周期有关的序列。
3. 日照市AQI预测决策树及控制因子
(1)随机森林预测PM2.5
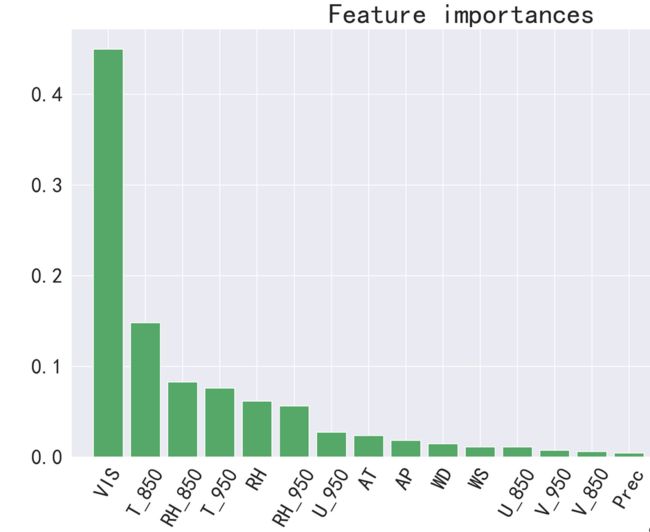
随机森林算法可以给出各个特征在决策中的重要程度,最大为1,最小为0。下图为控制PM2.5浓度的各个特征重要性。 可以看出,起主要作用的特征是能见度、边界层顶部1500米高度的温度和湿度、地面相对湿度、海陆风(海陆风环流发生在1000米高度以下,U_950可以代表约500米高度的东西方向风)。这说明云雾天气和海陆风环流的耦合效应对日照市大气颗粒物的增长具有突出贡献。
下图是经过提炼和剪枝后的PM2.5浓度的决策树:

可以得出如下结论:
海陆风环流、云雾过程在不同季节、 不同气象条件下发挥的作用不一样甚至是相反的。
极端重污染过程发生的条件是冬季的低温高湿但不形成降水的时间段。
非采暖季节,云雾过程虽然带来了低能见度天气,但是带来的降水会将颗粒物浓度清除至40 µg/m3 以下。
采暖季节,云雾过程既让能见度下降,又会使颗粒物浓度上升至60-100 µg/m3。
非采暖季节,陆风较弱,不利于颗粒物等污染物向海上扩散。而海风也有扩散效应,但是风力较弱时也不会使颗粒物浓度造成明显下降。所以日照市在海陆风环流较弱的情况下,最普遍的颗粒物浓度是80 µg/m3左右。这种良至轻微污染情况会在强北风下消散。
日照市的轻重工业能耗对于颗粒物浓度的效应不明显,处于决策树的末端枝叶,这说明自然条件占据主导。
(2)随机森林预测O3
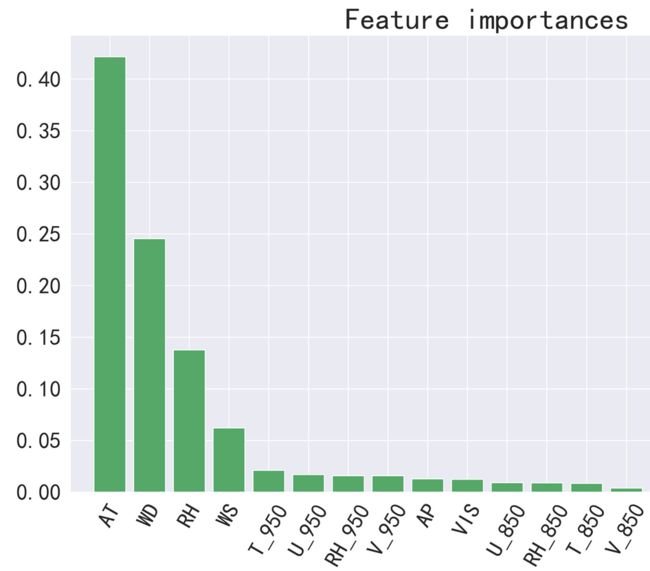
从下图特征重要性可以看出,地表气温、地表湿度、地表风向风速是控制臭氧浓度的决定性因子,占90%以上的比重。
下图是经过提炼和剪枝后的O3浓度的决策树:

可以得出如下结论:
冬季偏西的陆风有利于臭氧浓度维持在一个质量等级优良的水平,而冬季偏东的海风会让臭氧达到轻度污染水平。
在非采暖季,相对湿度< 83%,未发生云雾过程时,偏南风带来的暖气流使臭氧浓度上升至> 100 µg/m3。但是从西北方向来的冷空气也会使臭氧浓度偏高。
在非采暖季,相对湿度>83%,亦即发生云雾过程时,臭氧浓度较低 (< 70 µg/m3),但是东南风会使臭氧浓度升高。这说明臭氧高空向下传输更倾向于发生在偏暖的气流条件下。
夏季,边界层内晴朗干燥时,臭氧浓度上升至严重污染等级。
日照市的轻重工业能耗对于臭氧浓度的效应也不明显,处于决策树的末端枝叶,这说明自然条件占据主导。
(3)随机森林预测PM10
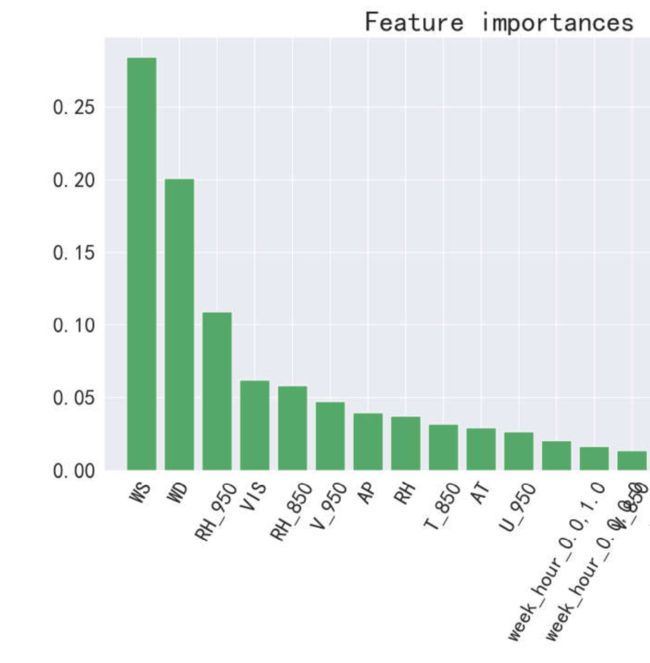
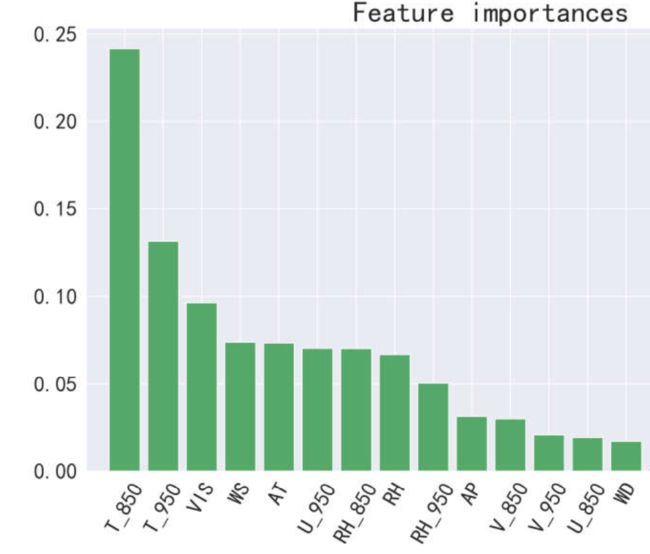
随机森林预测PM10、NO2、SO2的误差较大,决策树可能不准确。本文的原理假设未考虑沙尘过程、工业脱硫设施的更新、汽车新国标的实施等关键因子,相应地,模型预测大颗粒、二氧化硫、二氧化氮的表现不尽如意。以下只给出特征重要性。

(4)随机森林预测NO2
(5)随机森林预测SO2
四、尾声
每个行业、每个企业都在受到天气和环境的影响。美国航空航天局NASA指出,美国至少有三分之一的经济产值与气象和空气污染有关。如何将将分散的气象、环境、水文、地质、社会经济等数据汇集并融合,是提高环境预测结果、解析污染特征、防范环境风险的关键,而机器学习算法只是统计学上的胜利而已。我们相信,学科之间界限的打破、人工智能技术的发展和数据孤岛之间的连接会使我们更好地来描绘整个自然界,让人们更好地认知环境。