BeautifulSoup
与lxml一样,beautifulSoup4也是一个XML/HTML解析器。
它用于解析和提取HTML/XML数据,lxml只会遍历局部文档,而beautifulSoup能遍历整个HTML DOM树,载入整个文档,解析整个DOM树,因此消耗的时间和内存都很大。
beautifulSoup的特点
Beautiful Soup提供一些简单的方法和python式函数,用于浏览,搜索和修改解析树,它是一个工具箱,通过解析文档为用户提供需要抓取的数据
Beautiful Soup自动将转入稳定转换为Unicode编码,输出文档转换为UTF-8编码,不需要考虑编码,除非文档没有指定编码方式,这时只需要指定原始编码即可
Beautiful Soup位于流行的Python解析器(如lxml和html5lib)之上,允许您尝试不同的解析策略或交易速度以获得灵活性。
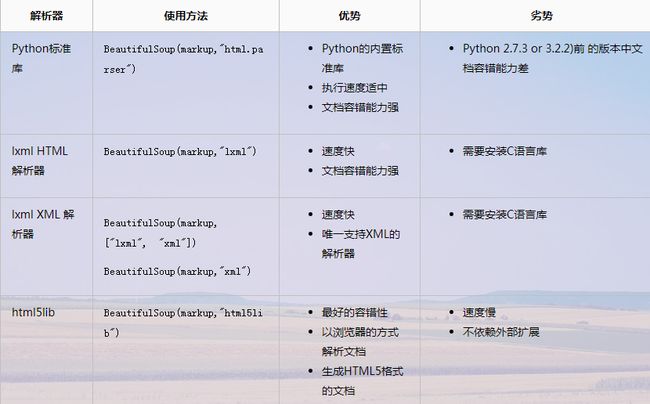
beautifulSoup与其它解析器lxml、html5lib的比较:
三种解析器的安装
解析器的安装非常简单,可以直接在命令模式下安装即可:
# 安装beautifulSoup
pip install beautifulSoup
# 安装lxml
pip install lxml
# 安装html5lib
pip install html5lib
基本用法
beautifulSoup的使用格式:需要导入bs4包,然后使用它的beautifulSoup4模块
# 首先创建beautifulSoup实例对象
soup = BeautifulSoop(html_doc, "lxml") # 参数为文档名、解析器类别
# 然后用这个实例对象用操作、提取文档中的数据
soup.prettify()
简单使用
使用beautifulStop4来提取html文档内容,这里以百度首页为例,将整个百度的首页打印下来。
from bs4 import BeautifulSoup
from urllib import request
# 以下文本为本次测试文本
html_doc = """
评价水果和蔬菜
水果
西瓜
Apple
Pear
蔬菜
大白菜
芹菜
green pepper
这是一篇关于水果和蔬菜的文章,用以评价各种水果和蔬菜!
"""
# 创建beautifulSoup对象
soup = BeautifulSoup(html_doc, "lxml")
soup1 = BeautifulSoup("", "lxml")
tag = soup.a
navstr = tag.string
comment = soup1.b.string
# Tag标签对象
print(type(tag))
# Comment对象包含文档和注释内容
print(type(comment))
# NavigableString对象包含字符串内容
print(type(navstr))
# BeautifulSoup对象为文档的全部内容
print(type(soup))
# 返回head标签下所有内容
print(soup.head)
结果:
评价水果和蔬菜
运行程序后,分别打印了四种Python对象。其中还返回了关于
节点的所有内容,包括它的属性和子节点等。注: 要想使用beautifulSoup4模块,需要导入bs4包。
beautifulSoup4支持的类型
BeautifulSoup将HTML文档转换成复杂的树形结构,结构中的所有节点均是Python对象。
BeautifulSoup相当于选择器,如同CSS一样,可以通过规则选定HTML DOM中的所有节点。
这些对象可以归纳为四种类型:
- Tag(节点选择器):包括Name、
- NavigableString(对字符串进行操作)
- BeautifulSoup
- Comment
Tag(节点选择器)
Tag是HTML文档中的所有节点,直接调用节点的名称就可以访问节点。
# 返回head标签下所有内容
print(soup.head)
# 返回h1标签的内容
print(soup.h1)
# 返回p标签下的b标签
print(soup.p.b)
# 获取a标签下的文本
print(soup.a.string)
结果:
评价水果和蔬菜
水果
水果和蔬菜
西瓜
从结果可以看到,普通的节点选择,它只会选择就近的节点,不会将所有节点提取出来。
Name选择器
这个Name是标签的名称,不是name属性。
# 获取body的name
print(soup.body.name)
# 获取h1标签的name
print(soup.h1.name)
# 获取li标签的name
print(soup.li.name)
结果:
body
h1
li
获取到的是标签的名称。
同时,如果修改了tag的name,那么也会改变所有通过当前BeautifulSoup对象的HTML文档。
# 修改tag的name
print(tag.name)
tag.name = "p"
print(tag)
查看结果:
a
西瓜
可以看到,修改之前是a标签,通过name修改之后就变成了p标签。当然,这只是通过BeautifulSoup对象中的HTML文档修改了,原本的文档没有改变。
attrs属性选择器
attrs表示获取节点的所有属性,也可以字典的形式直接获取某单一属性,返回的可能是列表或字典,需要根据节点的属性决定。同时,也可以由attrs选择器来更改(修改、添加)节点的属性值。
属性的获取有两种方式:
获取节点的所有属性:soup.h1.attrs
获取节点的某一属性:soup.h1.attrs["id"]、soup.h1["class"]
# 获取属性,要么以list形式返回,要么以字典形式返回
# 获取节点的所有属性
print(soup.h1.attrs)
print(soup.h2.attrs)
print(soup.li.attrs)
# 直接获取某单一属性
print(soup.h2["id"])
print(soup.h2.attrs["class"])
结果:
{'id': 'fruits', 'class': ['水果'], 'name': '水果name'}
{'id': 'Vegetables', 'class': ['蔬菜'], 'name': '蔬菜name'}
{'class': ['瓜类']}
Vegetables
['蔬菜']
可以通过attrs来修改节点的某属性值,它会影响到整个通过BeautifulSoup对象的HTML文档。当然,原HTML文档是没有改变的。
# 可以修改某属性,这只是对于通过beautifulSoup对象的文档修改了,原文档没有改变。
soup.h2.attrs["class"] = "Vegetables"
print(soup.h2.attrs["class"])
结果得到修改,但原文档并没有改变:
Vegetables
除了可以修改属性值外,还可以为节点添加新的属性。当然,这只是影响通过BeautifulSoup对象的文档,原HTML文档是不受影响的。
# 可以为节点添加新的属性,不影响原HTML文档
soup.h2.attrs["title"] = "蔬菜"
print(soup.h2.attrs["title"])
结果:
蔬菜
string字符串
通过string可以得到tag标签中的字符内容(text文本内容)。
注: 如果之前有通过“name = xx”的方式修改过某标签,那么string获取到的文本内容就是修改过后的标签下的文本内容。
# 通过string得到tag的文本内容
print(soup.title.string)
# 之前已将第一个标签修改了p标签,所以这里显示的内容是原第一个a标签中的内容。
print(soup.p.string)
结果:
html5 评价水果和蔬菜 西瓜
注: 因为在此之前有过如下操作,所以原来的第一个a标签已经变成了p标签,所以现在获取到的文本内容不是文档中最后一个p标签的内容,而是第一个a标签修改前的内容。
# 这是让tag指向a标签
tag = soup.a
# 这实际上的操作就是将a标签变成p标签
tag.name = "p"
# 此时获取到的文本内容是第一p标签的内容,也就是原第一个a标签的内容
print(soup.p.string)
注意: 通过这一系列的操作可以发现,如果没有特殊指定,通过beautifulSoup对象获取到的节点的数据均是文档中“第一个”节点的数据。
contents 获取直接子节点
获取直接子节点,以列表的形式返回内容。
注: 获取的是直接子节点,不包括子孙节点,并返回的是节点下的所有内容(包括空白文本节点_\n、子节点等)。
# 获取节点的直接子节点,以列表形式返回内容,而不是子孙节点
print(soup.head.contents)
print(soup.body.contents)
print(soup.p.contents)
结果:
['\n', , '\n', 评价水果和蔬菜 , '\n']
['\n', 水果
, '\n',
,
西瓜
, '\n',
Apple
, '\n',
Pear
, '\n', 蔬菜
, '\n',
,
大白菜
, '\n',
芹菜
, '\n',
green pepper
, '\n', 这是一篇关于水果和蔬菜的文章,用以评价各种水果和蔬菜!
, '\n']
['这是一篇关于', 水果和蔬菜, '的文章,用以评价各种水果和蔬菜!']
从结果可以看出,contents返回的不仅是节点下的直接节点的内容,还返回文本节点内容,连换行符_\n都返回,换行符也属于文本内容。
同时,我们也可以通过访问列表的方式来访问返回结果的某一元素内容:soup.body.contents[1]获取body中第二个元素的内容。
children 获取直接子节点
获取直接子节点,以生成器的形式返回,可以使用for循环遍历返回的内容。
# 获取节点的直接子节点,以生成器返内容,因此需要用for循环访问内容
child = soup.body.children
for i in child:
print(i)
结果:
水果
西瓜
Apple
Pear
蔬菜
大白菜
芹菜
green pepper
这是一篇关于水果和蔬菜的文章,用以评价各种水果和蔬菜!
从这个结果可以看出,返回的元素均是body节点的直接子节点,也就是说,生成器的每个元素是body节点的直接子节点,而直接子节点中又包含它自己的子节点。
descendants 获取子孙节点
获取子孙节点,以生成器形式返回,可以使用for循环遍历。
注: descendants会将每个子孙节点返回一次,也就是说,只要属性父节点的子孙节点,均会返回。子孙节点包括文本节点、标签节点等。
# 获取子孙节点,返回生成器.
# 将每个子孙节点返回一次
descend = soup.body.descendants
for i in descend:
print(i)
结果:
水果
水果
西瓜
西瓜
西瓜
Apple
Apple
Apple
Pear
Pear
Pear
蔬菜
蔬菜
大白菜
大白菜
大白菜
芹菜
芹菜
芹菜
green pepper
green pepper
green pepper
这是一篇关于水果和蔬菜的文章,用以评价各种水果和蔬菜!
这是一篇关于
水果和蔬菜
水果和蔬菜
的文章,用以评价各种水果和蔬菜!
从结果可以看到,程序将body的所有子孙节点全部返回。子孙节点包括:直接子节点、子孙节点、子孙节点中的文本节点。
parent父节点和parents祖父节点
parent指返回直接上层节点。parents指返回上层节点的上层节点、或更高层的节点,返回生成器。
获取节点的父节点:
# 返回父节点
print(soup.a.parent)
结果:
西瓜
获取节点的祖父节点(包括父节点、父节点的父节点、或更上层节点):
# 返回祖父类节点,返回生成器,用for循环遍历
parents = soup.a.parents
for i in parents:
print(i)
结果:
西瓜
水果
西瓜
Apple
Pear
蔬菜
大白菜
芹菜
green pepper
这是一篇关于水果和蔬菜的文章,用以评价各种水果和蔬菜!
评价水果和蔬菜
水果
西瓜
Apple
Pear
蔬菜
大白菜
芹菜
green pepper
这是一篇关于水果和蔬菜的文章,用以评价各种水果和蔬菜!
评价水果和蔬菜
水果
西瓜
Apple
Pear
蔬菜
大白菜
芹菜
green pepper
这是一篇关于水果和蔬菜的文章,用以评价各种水果和蔬菜!
可以看到,不仅返回了a标签的父节点li,还返回了li节点的父节点body和更上层节点html。
next_sibling 和previous_sibling
next_sibling返回下一个兄弟节点,previous_sibling返回上一个兄弟节点。所谓兄弟节点:同缩进下的元素节点。
注: 空文本节点(换行符、空白行)也为一个兄弟节点,所以多数时候会返回空白行节点。
next_sibling下一个兄弟节点:
print(soup.li.next_sibling)
结果:
西瓜
next_siblings 和 previous_sibling
分别返回前面和后面的所有兄弟节点,返回生成器,需要用for循环遍历。空白行也算兄弟节点
next_element 和previous_element
next_element获取解析过程中下一个被解析的对象(字符串或tag),previous_element获取解析过程中上一个被解析的对象。
next_elments 和 previous_elements
方法选择器
前面是通过节点属性来选择的,这种方法非常快。但对于一些复杂的选择就不是那么容易的,所以BeautifulSoup提供了两种方法作参考:find_all()和find()。
find_all(name, attrs, recursive, text, **kwargs, limit):查找 所有符合条件的元素。
- name:标签名tag_name、或者正则表达式、True、列表。
- attrs:通过属性来查找,属性以字典的形式传入。如:attrs = {"id" : "a"}。由于class属性是Python中的关键字,所有需要在前面加下划线,如:class_ = "attrs"。
- recursive:如果只搜索直接子节点就为False。
- text:匹配节点的文本,可以是字符串,也可以是正则表达式对象。
- limit:限制查找的数量。
find(name, attrs, recursive, text, **kwarge):查找符合条件的单个节点,也就是返回第一个匹配到的节点。
# 查找所有li标签,然后返回2个li标签,
print(soup.find_all("li", limit = 2))
# 查找class为瓜类的节点
print(soup.find_all("li", class_ = "瓜类"))
结果:
[
,
西瓜
]
[
]
**其它类似于find_all()和find()的方法:
# 另外还有许多查询方法,其用法和前面介绍的find_all()方法完全相同,只不过查询范围不同,参数也一样。
# find_parents(name, attrs, recursive, text, **kwargs )和find_parent(name, attrs, recursive, text, **kwargs ):前者返回所有祖先节点,后者返回直接父节点。
# find_next_siblings(name , attrs , recursive , text , **kwargs )和find_next_sibling(name , attrs , recursive , text , **kwargs ):对当前tag后面的节点进行迭代,前者返回后面的所有兄弟节点,后者返回后面第一个兄弟节点
# find_previous_siblings(name , attrs , recursive , text , **kwargs )和find_previous_sibling(name , attrs , recursive , text , **kwargs ):对当前tag前面的节点进行迭代,前者返回前面的所有兄弟节点,后者返回前面的第一个兄弟节点
# find_all_next(name , attrs , recursive , text , **kwargs )和find_next(name , attrs , recursive , text , **kwargs ):对当前tag之后的tag和字符串进行迭代,前者返回所有符合条件的节点,后者返回第一个符合条件的节点
# find_all_previous()和find_previous():对当前tag之前的tag和字符串进行迭代,前者返回节点后所有符合条件的节点,后者返回第一个符合条件的节点
CSS选择器
select()方法中传入字符串,即可使用CSS来选择节点。
通过tag名选择节点:
# 通过普通CSS来选择tag
print(soup.select("title"))
print(soup.select("li"))
print(soup.select("p"))
结果:
[评价水果和蔬菜 ]
[
,
西瓜
,
Apple
,
Pear
,
,
大白菜
,
芹菜
,
green pepper
]
[这是一篇关于水果和蔬菜的文章,用以评价各种水果和蔬菜!
]
通过tag逐层选择:
# 逐层选择
print(soup.select("li a"))
# 查找直接子节点
print(soup.select("body > p"))
结果:
[西瓜, Apple, Pear, 大白菜, 芹菜, green pepper]
[这是一篇关于水果和蔬菜的文章,用以评价各种水果和蔬菜!
]
a标签是所有li标签下层的节点。p标签是通过body的直接子节点。
通过类和ID查找
在CSS中,类名用“.”表示,ID用“#”表示。
# 通过类来查找节点
print(soup.select(".fruits"))
# 通过ID来查找节点,ID为Pear的li标签
print(soup.select("li#Pear"))
结果:
[水果
]
[
Pear
]
通过属性值查找
# 通过属性值查找
print(soup.select("li[id = 'Pear']"))
结果:
[
Pear
]
Tag修改方法
- append()向节点中添加内容
- tag(name, attrs = value):新添加节点,需要设置参数,及标签名和属性及属性值。
- string:修改标签中的文本内容。
html_2 = "Baidu"
soup2 = BeautifulSoup(html_2, "lxml")
# 通过string修改文本内容
soup2.a.string = "百度"
print(soup2.a)
# 为a标签添加文本内容
soup2.a.append("一下")
print(soup2.a)
结果:
百度
百度一下
修改节点的文本内容,然后向节点中添加文本内容。
通过tag修改方法在li标签内添加新的标签a,并为新标签添加文本内容。
# 创建BeautifulSoup对象
soup3 = BeautifulSoup("", "lxml")
# 创建新的tag,参数至少有tag名和属性
new_tag = soup3.new_tag("a", href = "http;//www.python.org")
# 将新的tag添加到li的文本内容中
soup3.li.append(new_tag)
# 为新的tag添加文本内容
new_tag.string = "Python"
print(soup3.li)
结果:
Python
tag中的其它修改方法:
insert() #将元素插入到指定的位置
inert_before() #在当前tag或文本节点前插入内容
insert_after() #在当前tag或文本节点后插入内容
clear() #移除当前tag的内容
extract() #将当前tag移除文档数,并作为方法结果返回
prettify() #将Beautiful Soup的文档数格式化后以Unicode编码输出,tag节点也可以调用
get_text() #输出tag中包含的文本内容,包括子孙tag中的内容
soup.original_encoding # 属性记录了自动识别的编码结果
from_encoding #参数在创建BeautifulSoup对象是可以用来指定编码,减少猜测编码的运行速度
BeautifulSoup
BeautifulSoup对象表示整个HTML文档。它没有特定的name和属性,但有时也能查看它的.name。它的.name为[document]。
print(soup.name)
结果:
[document]
Beautiful Soup异常处理
HTMLParser.HTMLParseError:malformed、start、tag
HTMLParser.HTMLParseError:bad、end、tag
这个两个异常都是解析器引起的,解决方法是安装lxml或者html5lib
更多关于BeautifulSoup的内容:
BeautifulSoup文档