简介
Caffeine,是一种建立在java8基础上的高性能缓存框架。它是一种本地缓存,功能类似Guava cache,可以理解为其是Guava cache的一个加强版本。 下图是其官网给出的性能比较:
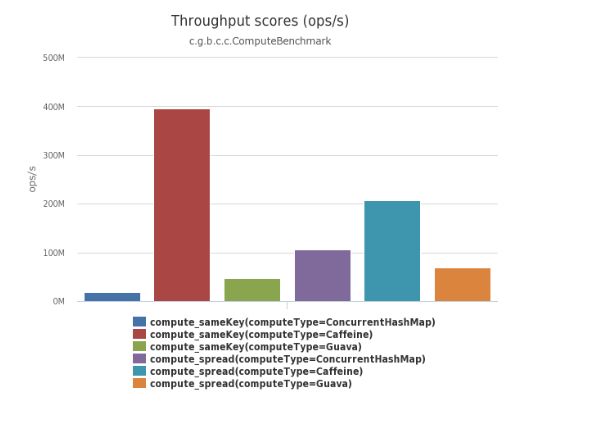
本文主要介绍了Caffeine的基本用法并对其实现原理进行一些探讨。
功能介绍
Caffeine的Api几乎和Guava cache一样,如果对Guava cache比较熟悉的话,那么熟悉Caffeine的api将会很容易,下面简单的展示一下Caffeine的用法。
缓存加载方式
Caffeine提供了三种使用方式:手动加载、同步加载、异步加载方式,如下所示:
/**
* 手动加载
*/
@Test
public void testManual() {
Cache cache = Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES)
.maximumSize(10_000)
.build();
cache.get("key", k -> createExpensiveGraph("key"));
}
/**
* 同步加载
*/
@Test
public void testLoading() {
LoadingCache cache = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.build(this::createExpensiveGraph);
System.out.println(cache.get("key"));
}
/**
* 异步加载
*/
@Test
public void testAsyn() throws ExecutionException, InterruptedException {
AsyncCache cache = Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES)
.maximumSize(10_000)
.buildAsync();
CompletableFuture graph = cache.get("test", k -> createExpensiveGraph("test"));
System.out.println(graph.get());
}
缓存淘汰策略
与Guava cache一样,也提供了三种缓存淘汰策略,分别是基于大小、时间、引用方式。
LoadingCache cache = Caffeine.newBuilder()
//基于数量的配置
.maximumSize(1000)
//基于权重
.maximumWeight(1000)
//指定计算权重的方式
.weigher(this::caculateWeight)
//指定缓存在写入多久后失效。
.expireAfterWrite(1000,TimeUnit.SECONDS)
//指定缓存在访问多久后失效。
.expireAfterAccess(1000,TimeUnit.SECONDS)
//多种时间过期策略组合使用。
.expireAfter(new Expiry() {
public long expireAfterCreate(Key key, Graph graph, long currentTime) {
long seconds = graph.creationDate().plusHours(5)
.minus(System.currentTimeMillis(), ChronoUnit.MILLIS).getSeconds();
return TimeUnit.SECONDS.toNanos(seconds);
}
public long expireAfterUpdate(Key key, Graph graph,long currentTime, long currentDuration) {
return currentDuration;
}
public long expireAfterRead(Key key, Graph graph,long currentTime, long currentDuration) {
return currentDuration;
}
})
.build(this::load);
异步刷新
Caffeine和Guava cache一样,也提供了异步刷新的功能,通过refreshAfterWrite方法指定刷新的时间,实例如下所示:
LoadingCache cache = Caffeine.newBuilder()
.expireAfterWrite(10,TimeUnit.SECONDS)
.refreshAfterWrite(2,TimeUnit.SECONDS)
.executor(Executors.newFixedThreadPool(1))
.build(this::load);
Caffeine的刷新是异步执行的,默认的刷新线程池是ForkJoinPool.commonPool(),也可以通过executor方法指定为其它线程池。刷新操作的触发时机是在数据读取之后,通过判断当前时间减去数据的创建时间是否大于refreshAfterWrite指定的时间,如果大于则进行刷新操作。一般refreshAfterWrite常和expireAfterWrite结合使用,需要注意的是:refreshAfterWrite设置的时间要小于expireAfterWrite,因为在读取数据的时候首先通过expireAfterWrite来判断数据有没有失效,数据失效后会同步更新数据,如果refreshAfterWrite时间大于expireAfterWrite,那么refresh操作永远不会执行到,设置了refreshAfterWrite也没有任何意义。
缓存的清除策略
Caffeine的缓存清除是惰性的,可能发生在读请求后或者写请求后,比如说有一条数据过期后,不会立即删除,可能在下一次读/写操作后触发删除。如果读请求和写请求比较少,但想要尽快的删掉cache中过期的数据的话,可以通过增加定时器的方法,定时执行cache.cleanUp()方法,触发缓存清除操作。
其它功能
Caffeine还提供了其它的功能,如:缓存监控、事件监听等功能,感兴趣的同学可以去其wiki查看。
原理
高效的缓存淘汰算法
缓存淘汰算法的作用是在有限的资源内,尽可能识别出哪些数据在短时间会被重复利用,从而提高缓存的命中率。常用的缓存淘汰算法有LRU、LFU、FIFO等。
LRU(Least Recently Used)算法认为最近访问过的数据将来被访问的几率也更高。LRU通常使用链表来实现,如果数据添加或者被访问到则把数据移动到链表的头部,链表的头部为热数据,链表的尾部如冷数据,当数据满时,淘汰尾部的数据。其实现比较简单,但是存在一些问题,如:当存在数据遍历时,会导致LRU命中率急剧下降,缓存污染情况比较严重。LRU算法也并非一无是处,其在突发流量下表现良好。
LFU(Least Frequently Used)算法根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。根据LFU的思想,如果想要实现这个算法,需要额外的一套存储用来存每个元素的访问次数,会造成内存资源的浪费。
Caffeine采用了一种结合LRU、LFU优点的算法:W-TinyLFU,其特点:高命中率、低内存占用。在搞懂W-TinyLFU算法之前,首先了解一下TinyLFU算法:TinyLFU是一种为了解决传统LFU算法空间存储比较大的问题LFU算法,它可以在较大访问量的场景下近似的替代LFU的数据统计部分,它的原理有些类似BloomFilter。首先回顾一下BloomFilter原理:在BloomFilter中,使用一个大的bit数组用于存储所有key,每一个key通过多次不同的hash计算来映射数组的不同bit位,如果key存在将对应的bit位设置为1,这样就可以通过少量的存储空间进行大量的数据过滤。在TinyLFU中,把多个bit位看做一个整体,用于统计一个key的使用频率,TinyFLU中的key也是通过多次不同的hash计算来映射多个不同的bit组。在读取时,取映射的所有值中的最小的值作为key的使用频率,TinyLFU算法如下图所示:

在Caffeine中,维护了一个4-bit CountMinSketch用来记录key的使用频率。4-bit也就意味着,统计的key最大使用频率为15,具体的实现逻辑可以参考源代码中的FrequencySketch类。
TinyLFU有一个缺点,在应对突发流量的时候,可能由于没有及时构建足够的频率数据来保证自己驻留在缓存中,从而导致缓存的命中率下降,为了解决这个问题,产生了W-TinyLFU算法。W-TinyLFU由两部分组成,主缓存使用SLRU回收策略和TinyLFU回收策略,而窗口缓存使用没有任何回收策略的LRU回收策略,增加的窗口缓存用于应对突发流量的问题,如下图所示:
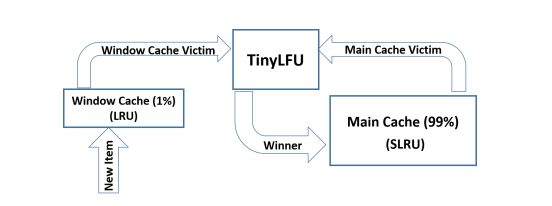
窗口缓存占用总大小的1%左右,主缓存占用99%。Caffeine可以根据工作负载特性动态调整窗口和主空间的大小,如果新增数据频率比较高,大窗口更受欢迎;如果新增数据频率偏小,小窗口更受欢迎。主缓存内部包含两个部分,一部分为Protected,用于存比较热的数据,它占用主缓存80%空间;另一部分是Probation,用于存相对比较冷的数据,占用主缓存20%空间,数据可以在这两部分空间里面互相转移。
缓存淘汰的过程:新添加的数据首先放入窗口缓存中,如果窗口缓存满了,则把窗口缓存淘汰的数据转移到主缓存Probation区域中。如果这时主缓存也满了,则从主缓存的Probation区域淘汰数据,把这条数据称为受害者,从窗口缓存淘汰的数据称为候选人。接下来候选人和受害者进行一次pk,来决定去留。pk的方式是通过TinyFLU记录的访问频率来进行判断,具体过程如下:
- 首先获取候选人和受害者的频率
- 如果候选人大于受害者,则淘汰受害者
- 如果候选人频率小于等于5,则淘汰候选人
- 其余情况随机处理。
Caffeine中的pk代码:
boolean admit(K candidateKey, K victimKey) {
int victimFreq = frequencySketch().frequency(victimKey);
int candidateFreq = frequencySketch().frequency(candidateKey);
if (candidateFreq > victimFreq) {
return true;
} else if (candidateFreq <= 5) {
// The maximum frequency is 15 and halved to 7 after a reset to age the history. An attack
// exploits that a hot candidate is rejected in favor of a hot victim. The threshold of a warm
// candidate reduces the number of random acceptances to minimize the impact on the hit rate.
return false;
}
int random = ThreadLocalRandom.current().nextInt();
return ((random & 127) == 0);
}
读写优化
Caffeine的底层数据存储采用ConcurrentHashMap。因为Caffeine面向JDK8,在jdk8中ConcurrentHashMap增加了红黑树,在hash冲突严重时也能有良好的读性能。
Caffeine的缓存清除动作是触发式的,它可能发生在读、写请求后。这个动作在Caffeine中是异步执行的,默认执行的线程池是ForkJoinPool.commonPool()。相比较Guava cache的同步执行清除操作,Caffeine的异步执行能够提高读写请求的效率。针对读写请求后的异步操作(清除缓存、调整LRU队列顺序等操作),Caffeine分别使用了ReadBuffer和WriterBuffer。使用Buffer一方面能够合并操作,另一方面可以避免锁争用的问题。
在时间的过期策略中,Caffeine针对不同的过期策略采用不同的实现:针对写后过期,维护了一个写入顺序队列;针对读后过期,维护了一个读取顺序队列;针对expireAfter指定的多种时间组合过期策略中,采用了二维时间轮来实现。Caffeine使用上述这些策略,来提高其在缓存过期清除时的效率。
总结
本文对Caffeine的使用和原理进行了简单的介绍,其在细节设计上有很多优化,如果想要更加深入的了解内部设计细节,可以参考下方给出的参考资料。Caffeine是一个非常不错的缓存框架,无论是在性能方面,还是在API方面,都要比Guava cache要优秀一些。如果在新的项目中要使用local cache的话,可以优先考虑使用Caffeine。对于老的项目,如果使用了Guava cache,想要升级为Caffeine的话,可以使用Caffeine提供的Guava cache适配器,方便的进行切换。
参考
- https://github.com/ben-manes/caffeine/wiki
- https://arxiv.org/pdf/1512.00727.pdf
- https://github.com/google/guava/wiki/CachesExplained