| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 2020春季计算机学院软件工程(罗杰 任建) |
| 这个作业的要求在哪里 | 个人博客作业-软件案例分析 |
| 我在这个课程的目标是 | 完成一次完整的软件开发经历 并以博客的方式记录开发过程的心得 掌握团队协作的技巧 做出一个优秀的、持久的、具有实际意义的产品 |
| 这个作业在哪个具体方面帮助我实现目标 | 尝试着分析一个软件 学会规划分析软件的步骤和设计衡量方式 |
| 教学班级 | 006 |
简介
本文主要介绍邹欣老师团队的一项OCR识别表单的开源工作,并与同类型的轻量级OCR文本识别软件进行对比测试和分析。
本文将从以下几个方面进行比较:
- 安装(上手)的简易程度
- 识别正确率
- 识别速度
- 可扩展性
- BUG 比较
安装(上手)的简易程度
- 对于 MicroSoft 的OCR识别表单软件,有以下使用方式:
- 项目测试网站在线使用
- 使用官方提供的docker镜像
- 下载Github上源代码并在本地编译安装使用
后两种安装方式需要一定的计算机能力,具体安装步骤可参考MisTariano的博客
- 对于 ouyanghuiyu 的开源超轻量级中文 ocr,源代码即 python 文件,保存到本地进行运行即可。
踩坑细节
MicroSoft-OCR
- 首先体验的网站是部署在 Azure 上的,所以国内访问会延时较高,甚至会出现连接不上的情况,所以没有上网条件的朋友选择本地部署更佳,但是,本地部署需要一定的计算机能力,对于部分有需求的文字编辑来说又是一道门槛,所以如果能在国内的网站有部署上线的话受众范围更大。
- 其次,无论是网页版还是本地软件都是要通过 Azure 的云服务来实现进行文件操作的,这一点也是困扰了我和另外尝试的同学很久的点,Azure 的国际注册需要绑定 VISA 或 Master 来避免机器人注册或滥注册,所以这一步是不可跳过的,对于大部分没有这两种卡的学生而言,是一道门槛。在咨询 Azure 客服,告知我的目的之后,客服建议我在中国国内的Azure服务上进行注册,https://www.azure.cn/,国区的Azure支持支付宝,有一元体验活动。
- 但是,Azure 的配置稍微有点繁琐,包括 blob storage 和开通 OCR 服务等,比较难以找到,所以又是一个巨大的挑战。在这里感谢邹欣老师给我们几位测试同学提供的各种资料是我们免去了自己的配置工作,使得测试得以展开。
这里立一个Flag,在测试完成之后,笔者将探索一下如何使用自己的账户进行配置,将在一周内进行答复(即:2020年03月27日前)。笔者和几位一同测评的同学都没有找到在国内的Azure开通MS的OCR的方法,在此希望尝试成功的读者能在评论下留言~
ouyanghuiyu-chineseocr_lite
- 源代码的生产和测试环境应该是在 linux 下进行的,所以笔者在 windows 下部署的时候遇到了一些问题,其中以下问题都可以在这个博客中找到答案,强烈推荐按照这个博客的流程走:
ModuleNotFoundError: No module named 'psenet.pse.pse'RuntimeError: Cannot compile pse: : your\path\to\chineseocr_lite-master\psenet\pseUnicodeDecodeError: ‘gbk’ codec can’t decode byte 0xab in position 551: illegal multibyte sequence
- 遇到
AttributeError: module 'six.moves.urllib_parse' has no attribute 'unquote_to_bytes'等 web.py 相关的问题的时候,大多数是因为版本装错了,可以先卸载当前的webpip3 uninstall web.py并装上固定的版本pip3 install web.py==0.40.dev0 - 另外,该轻量级ocr是直接在本地进行利用神经网络做出预测,所以有一块GPU图形显卡是最好的,时间上会快很多。
- Windows 下
make命令无法找到:这是由于make下载下来的时候叫做mingw32-make.exe,只要找到自己的环境变量下的这个文件,将其复制改名为make.exe然后重新打开cmd即可。 - make 的时候找不到
Python.h,这是由于自己的Python安装有遗漏,具体开源上网搜索解决方案,我这里是利用 Windows 下的 WSL2 进行 make, WSL2 中的 Ubuntu 直接sudo apt-get install python3-dev和sudo apt-get install python3.x-dev即可保证安装完所需的python模块,第二条语句的3.x是具体的python版本,比如我的是python3.6.9则执行sudo apt-get install python3.6-dev即可,注意:编译时的python和后续运行的python最好版本号相同,具体不同会怎么样我也没有尝试过,欢迎留言告诉我。
使用方式
MicroSoft-OCR
- 登陆在线测试网站或登陆本机部署网站

- 先在 connection 添加自己的 Azure blob container 的连接

- 回到 home 新建 Project
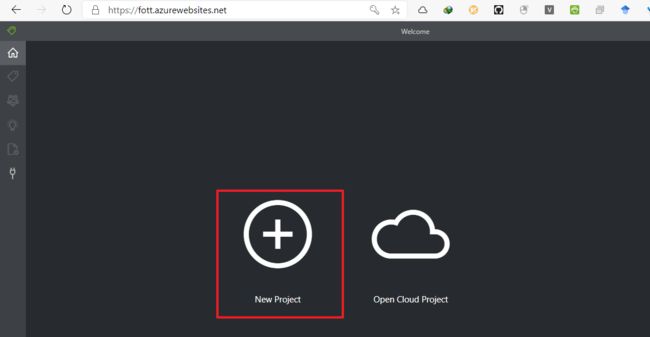
- 填入Project相关的参数
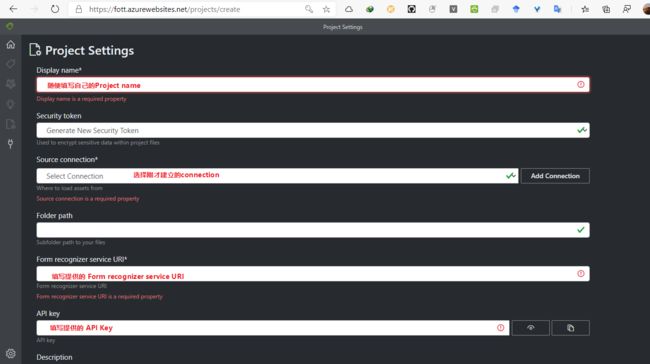
- 进入 Project 之后点击 tag 自己设定要识别的文本标签,这里建议有至少5份的相同排版格式的表单文件,否则训练样本过少效果不能得到保证

- 上一步中对每一份的标签打完之后点击左侧的 Train 进行模型的训练
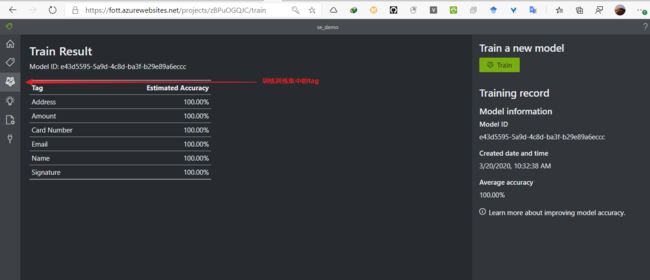
可以看到这里在我们提供的5份训练样本中达到了每一项都100%的最佳效果 - 点击左侧的 Predict 可以上传文件格式相同的pdf进行预测提取

可以看到我们需要的每一个标签下的识别结果,并附上了识别的准确率,可以直接导出json格式 - 上传的待标记文件需要提前存放在 Azure 的云端存储中,不能从网页端 直接上传训练集,网页端只能上传测试集
ouyanghuiyu-chineseocr_lite
- 在本地环境中配置好后命令行运行python
python app.py 8000,其中 8000 是本地web 的端口号,可以进行修改

- 本地浏览器输入
localhost:8000之后可以看到软件的布局和功能
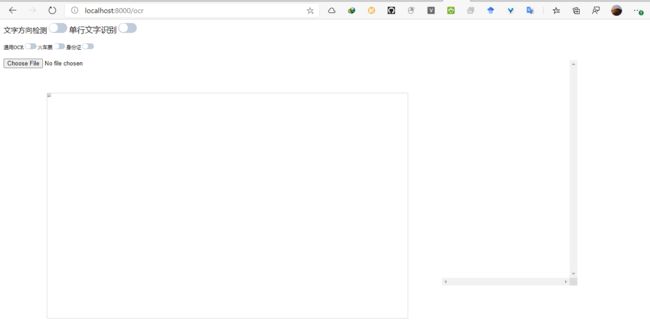
可以看到上面有 文字方向检测 和 单行文字识别,这两个开关都是给有特定需求的使用,如竖版文字识别等,下方有 通用OCR、身份证和火车表三种识别方式,上面的两个选项是可以随意开关的,下面的三个选项是必选其一且互斥的 - 点击
Choose file上传后,后台的python会相应执行,识别成功后前端返回结果如下:

可以看到在后台会执行相应的操作,在网页右侧会显示识别的耗时和结果,结果可以进行复制
本轮结果
| 项目 | MicroSoft-OCR | chineseocr_lite |
|---|---|---|
| 连接 | 受限于国内网络环境难以连接 | 不进行连接,本地运行 |
| 运行 | 需要依附于 Azure blob Storage,国内不方便 | 需要Python环境的支持,且需要一定的计算机基础 |
| 上传文件 | 需要上传到Azure同步 | 直接本地选择文件 |
| BUG | 外部原因导致登陆麻烦,登陆成功后使用简单 | 需要自己进行大量的配置,对计算机小白不友好,配置成功后使用简单 |
识别正确率
对于OCR软件而言,正确率无疑是重中之重,没有优秀的识别率无论多么美观都是纸糊的,所以首先测试一下识别率。
MicroSoft-OCR
对于上传的pdf而言,MS的OCR会先进行一个全文档的识别,然后按照空白符进行单词的分割,分割的粒度表现很好,如下图所示:
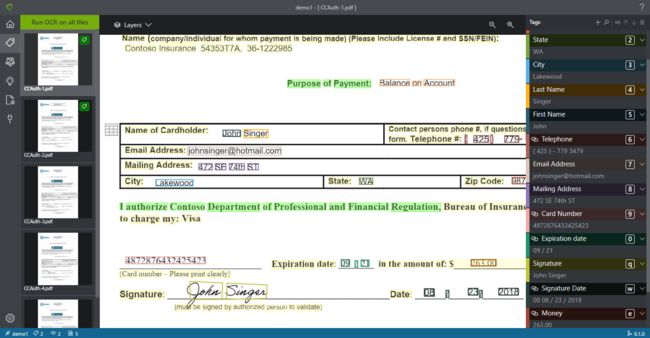
非要从鸡蛋中挑骨头的话,对于斜杠"/"的处理没有做到分开,但是从现实的语义来讲,斜杠一般表示或的意思,也不应该分开。
在这里特别要佩服MS的OCR的地方在于手写字体的识别,如上图所示,OCR可以识别出来 Signature 处的 John Singer 的签名,这一点要归功于模型背后的训练,在很少地方能减少识别手写字体的OCR。
ouyanghuiyu-chineseocr_lite
识别英文场景
在本轮中,轻量级OCR实属不该,为了公平对比也拿表单交给其识别,但正确率惨不忍睹,具体如下:

从右侧可以看出虽然是自动分割,但是分割粒度很差,"Contact phone number" 完全没有区别开来,甚至还将后面的一个 "f" 带来上去,实属不该。自动分割出来的东西几乎不能使用,如 "Contactpersonsphonef" "NameotCardholder" "Telephone#" "ACaciaAvenue" 等等。
识别中文场景
考虑到这个轻量级OCR前面带有中文二字,为了公平起见,还对其加入了中文的测试,但是没能如愿:

在我们最常见的学生整理笔记的使用OCR的场景下,不仅句子内部会被无规律断开,甚至出现了句子前后顺序调换的情况,令人咂舌。
识别特殊场景
看到这个项目在GitHub上有3.1k的stars时,我依然坚信这个软件一定在某方面有着过人之处,于是开始了其提供的身份证和火车票的场景识别。
在火车票场景中,也有点令人汗颜:

对于红纸的普通快车火车票,居然只能识别出来一个票价,对于车次,发车时间,座位等完全忽视。 注:图中的红色框线是后来加上去的,在识别的时候并没有任何干扰。

对于蓝色的高铁票时,能准确识别出发车的日期和时间,而票价???
图中我标出红色的地方在识别的时候是没有的,只是怀疑票价里面的 194 是不是将 19车识别了进去?
在身份证场景下,不知道是不是我的操作出现了问题:

只识别出来了一个地址,而且头部还多了一个 “住址” 的址,基本的名字性别民族等非常规范化排布的其他信息都无法识别,我不禁看了一眼我手机里面平时使用的OCR,居然能识别车牌、身份证、驾驶证、房产证等等一些列证件,有点怀疑这3.1k的star是怎么来的。
本轮结果
不需要列出比较的表格了,可以说是MS家的完胜,至于这个chineseocr-lite我也不知道是出了什么状况,是训练不到位吗?
MS家的能识别手写的英文字体令人非常佩服,毕竟很多签名有大量的连笔和变形在里面。
至于算得上是 chineseocr-lite 的特色的身份证和火车票识别也没有表现出众,这种排布非常规范化的识别场景完全可以交由 MicroSoft的OCR 来做,和合同中的标记一样,在特定的位置标记上想要的文字,就可以直接输入新的样本来进行预测了。
识别速度
有人认为识别速度是在识别准确率能够达标的基础之上的,也有人认为为了识别的速度牺牲一点准确率也无可厚非,这一点上大家求同存异,抛开准确率来测试一下。
MicroSoft-OCR
首先这是一款部署在国外的在线测试网站,所以有延迟是很正常的,亲测这样一张A4纸的内容翔实的合同从点击到识别完成里面的全部内容大概需要 10s~1min 不等,波动较大:

在训练阶段则是非常迅速,因为不需要用网络加载图像,所以实测在13s左右就可以训练完成返回训练结果:
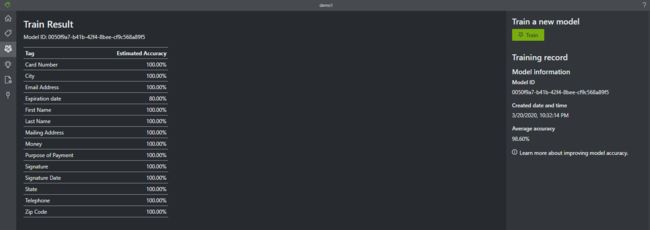
注:训练集大小是5个文件各有14个tag
ouyanghuiyu-chineseocr_lite
在不考虑正确性的情况下,我使用的是电脑自带的 Nvidia 1050Ti 的GPU显卡进行加速,识别同样大小同样内容的A4合同的时间只需要4s,对于简单的截图识别都在1s左右,由于是本地运行的原因所以不用考虑网络的环境延时。

本轮结果
考虑到网络延时的因素,其实这样的对比并不是非常公平,要是使用的是腾讯云、阿里云等国内的服务器,可能二者的差距就没有那么明显了。
可扩展性
MicroSoft-OCR
对于微软的OCR识别而言,只要提前做好标记便可以做到“查用户想查”。比如在轻量级OCR中的身份证识别,微软OCR只需要5张的身份证照片做训练集,在需要的信息后面进行标注tag即可做到对应信息的提取。同理,火车票可以看作是也是规范布局的表单,只需要定位相应的信息,通过训练一个新的模型就可以实现信息的提取。甚至如果需要识别所有文字的情况下,只需要新建一个比如叫做 "all" 的 tag,然后训练样本上全选,那么测试样本上也会选中所有的文本。
对于测试的样本,既可以是pdf格式,也可以是图片的格式,非常灵活。
ouyanghuiyu-chineseocr_lite
可以进行文字方向检测,由于手头上没有竖版文字的图片所以借用了项目中的GitHub的README中的样例图:

本轮结果
MS的OCR可以覆盖到轻量级OCR的两个特殊场景检测——身份证和火车票,但是不能做到轻量级OCR的文字方向检测,但鉴于文字方向检测和单行文字识别这两个功能的利用率可能1%都不到,所以还是微软的OCR更胜一筹。
Bug 寻找
这个环节对于选择其他软件进行分析的同学来说是非常痛苦的,因为像是VSCode和MSVS这种由专门的开发团队定时进行迭代的开源生产力项目,加上微软内部的“自己的狗粮自己吃”的测试理念,能被人发现的bug已经很少了,但是对于我今天测评的两款软件来说,还在开发测试阶段,所以很容易就能发现一些端倪。
MicroSoft-OCR
- 首先是 tutorial 的缺乏,这一点不算是 technical bug,而算是广义的bug。不知道是不是这款开源软件仍处于测试阶段的原因,进入网站完全找不到任何tutorial教学,完全是自己摸索,这一点对于同学们还好,但对于有一定年纪的不是经常捣鼓电脑的人来说,相当吃力。就算是我们计算机专业在读每天接触各种软件和代码的同学来说,也不免地遇到了一些麻烦。
比如我在进行tag标记的时候,由于网络延时的原因,电话号码被我选择之后没有立刻投放到电话号码的tag里面,而是跟着后面选择的邮寄地址一同分类到了邮寄地址的tag中,这时候我想删除里面的电话号码但是发现找不到一个删除内容的键,迫不得已只能删除整个tag之后重新加入tag。后来邹欣老师告诉了我解决方案是选中要删除的内容,然后按删除键(del),在这里分享给找不到删除键的朋友们。这种删除的方式就特别像是一个人的个人习惯,就像是让新手退出vim一样困难,我好几次遇到要删除的问题的时候都没有想到删除键,这一点没有告诉给使用者确实有点令人费解。我觉得对于这种增删改查的操作,在有实体按键的前提下加上键盘上就能操作的快捷键是再好不过了,就像PhotoShop一样顺手。 - 识别的正确率虽然很高,但是在识别数字的时候总是会出现奇怪的重复识别的问题:

比如上面的电话前的区号的 913 会被识别两次,画上两个框,所以在标记tag的时候一不注意直接选中就会导致电话变成了 "(913 913)",还有就是中间的分隔符会出现跑到后面的情况,这一点也不是偶然现象。
这种数字的框出现重复的情况即使在标记的过程中人工去除了重复值,但是在训练的时候还是会被网络自动选中详尽的区域的所有框线,导致在预测新样本的时候再次出现重复的数字: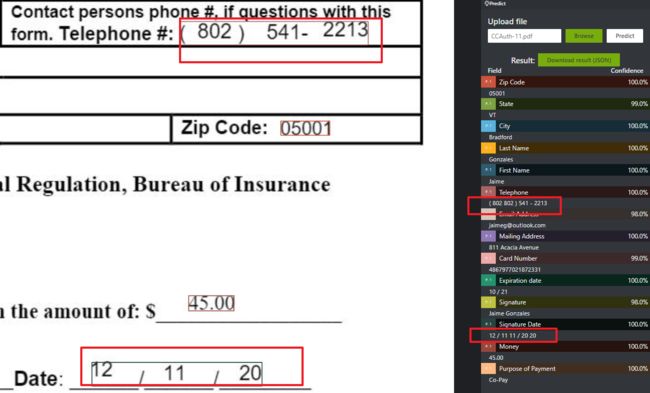
上图中就是因为训练的时候将相邻的位置的选框整合到了一起,所以最后选取整个大的合并选框的时候就会带来重复数字,是一个千真万确的bug。
其他方面感觉都非常不错,预测出来的14个tag除了重复数字的bug之外都是全对的,就连手写字体识别也准确地“一字母不差”。
测试识别效果:

ouyanghuiyu-chineseocr_lite
- 首先是识别的准确率太低了,这个已经不能称之为bug了,到达了产品的缺陷的地步,无论是对英文的还是对中文的,英文出现了字母和数字不分的情况,中文则是出现识别错误和前后语句顺序颠倒的情况,并且无论什么语言都有胡乱分割的现象,一个完整的句子不考虑语义被拆分成长短不同的几块并分别编序号。
翻车现场:
- 其次还是特色功能并没有展现出其特色,在上文中已经贴出来了身份证和火车票的识别结果,除了能识别的信息极少意外还出现了误识别的现象。
- 应该是受限于python的实现,在识别成功一个结果之后如果再对上面的识别选项做出修改是没有反应的,必须先传输一张不同的照片,然后再传输当前的照片才能开始识别,这一点是比较难受的,因为如果一开始忘了要切换识别身份证或者火车票则需要经过很多额外的步骤。
- 自动分割的功能。这个功能其实挺好的,估计初衷是想按照空格或者换行等分隔符将语句分开,但是在识别的准确率低的情况下,就成了一个累赘,分割出来的语句有点“狗屁不通”,忽略背后的语义,反而增大了使用者复制的难度。
本轮结果
两款OCR软件都有一定的BUG存在,但是相对于微软OCR的识别正确了但重复了的BUG而言,轻量级OCR的识别错误且混乱带来的用于体验和效果更差,所以这一轮还是微软OCR胜出。
个人使用体验
本章节仅代表个人的使用感受,大家看看就好。
非常荣幸在邹欣老师提供的帮助下完成了本次的软件对比测评,之前的时间一直在做前期准备——收集清晰度不同的pdf文档进行对照,但是知道真正上手的时候才知道自己准备的文档并没有什么用处,测评路上的艰难险阻太多了。
光是登陆一个Azure账户就被VISA卡的认证卡住,有的人进行学生认证也被卡住,最终在Azure的客服的见一下在国内的Azure网站注册后又被不熟悉的Blob Storage卡住,最后还是邹欣老师给我们提供了API和URI才使得测试得以进行下去。在测试轻量级ocr的时候也遇到了一些环境上的配置问题,也是查阅了很多博客才得以解决,不过上午中午配置完之后下午得以有时间好好玩一下两个软件。
其实刚开始拿到这个作业的时候挺吃惊的,腾讯云、阿里云还是很有厂商都已经推出了成熟的OCR的API接口,要这个微软的开源项目有什么用呢? 但是直到上手之后才发现 “术业有专攻”。
微软的这一款开源项目是专门针对表单识别的,就像是我贴出来的测试中的各种银行的表单,上面可能有开户人的姓名、联系电话、联系地址、邮政编码、个人签名等等,而且表单的形式带来的是更复杂的识别场景,是普通的OCR不能应对的。就像是上面出现的表格等内容,很容易被普通的OCR识别得一团糟。其次,微软的OCR是可定制的,这里就和轻量级OCR表现出了明显的不同,两者都可以提取识别的文字信息,但是微软OCR确定了识别的文字的具体位置和内容,甚至你在创建tag的时候还可以选择存储的类型——是字符串?数字?日期?甚至是时间?但与之相比是轻量级OCR的自动分割,这种分割效果需要大量的样本的训练,甚至因为语义上的分割还需要学习自然语言之间的联系,什么时候该短句?什么时候是同一个意群?这些其实远超了OCR自身识别的需要了。
使用这两款软件给我最大的感受就是——微软的OCR是toB的,是成熟的、投入市场中可以使用的,而轻量级OCR更像是一个深度学习入门的小白的一个玩具,两者其实在最开始就不应该放在一起进行比较,以至于出现了比较中经常看到的“降维打击”。微软的OCR在很多商业的场景下会被使用到,比如上面提到的银行业务,很多都是先让你填写表单,然后打印签字,抑或是邮政业务,打印带有收件人信息和寄件人信息的寄送单并让收件方签字等等,在这种情况下,所有的待识别的文档都具有一个固定的格式,只要填写在 "Email Address" 的后面,就一定是个人的电子邮箱,都有固定的位置进行相应的信息的提取,也正是因为微软OCR的这种 “用户可定制性” ,使得轻量级OCR的特色功能也相形见绌,只要提供给微软OCR几张身份证照片和火车票样张并加上tag进行训练,微软OCR完全可以hold住这种信息量少而且规范格式的特定场景识别。
微软OCR的toB其实也可以从识别文件的输入输出方式看出,在网页端是无法进行训练集的上传的,训练集中的文档都是存储在 Azure 的 storage 特定的文件夹中,只能使用 Azure 客户端、网页端进行管理或使用 Azure storage explorer 进行管理,更加规范,并且格式都是标准的pdf文件格式而不是图像,这也符合规范的商业表单都是pdf整理的特点,最后微软的OCR还提供了 JSON格式的输出,可以直接将结果导出进行成分分析,在商业中可能经过一个python文件处理,表单中的信息就进入到数据库中了,实现了完全的自动化。
轻量级OCR在这次的测试中令人比较失望,可能是因为没有自己本地进行训练的原因,但和GitHub主页上的3.1k赞也大相径庭,在轻量级OCR的README中给的样例都是字体特别大的而且分割开的,准确率确实不错,但是在测试中对于同学们一个正常的识别知识点和题目的场景下都不能表现出色实在令人匪夷所思,可能是因为其重点在于“轻”而不在于“准”所导致的。就像我前面说的,它更像是一个MNIST手写字体识别一样,是深度学习入门的人的一个玩物,大家可以对照着它“轻量级”的代码仓库进行学习,还可以加上自己的个性化定制,比如改变里面的lstm网络等等,学习意义大于使用意义。
听邹欣老师说后面将会提供中文的表单识别,让我们拭目以待。
作业第二部分:分析
预估完成项目所需时间
使用此服务的所有功能,估计这个软件/网站/服务做到这个程度大约需要多少时间(团队人数6人左右,计算机大学毕业生,并有专业UI支持)。
对于轻量级OCR而言,难点在于保持准确度的情况下压缩模型到项目README中所说的
"轻量的backone检测模型 psenet(8.5M, crnn_lstm_lite(9.5M) 和行文本方向分类网络(1.5M)"
同时还要加上特殊的任意方向文字检测,识别时判断行文本方向的功能。
所以在 团队人数6人左右,计算机大学毕业生,并有专业UI支持 的前提条件下,全身心投入大概需要花半个月的时间就能够实现。
但是对于微软的OCR表单识别而言,需要达到细粒度的单词的划分和手写字体识别的准确性,加上在 Azure 上进行部署提供测试网站使用,全身心投入的话保守至少在1个月以上到两个月的时间。
分析这个软件目前的优劣
对于轻量级OCR而言,个人认为学习的意义大于实际使用的意义,因为实际的识别准确率从今天的多种测试结果来看都惨不忍睹,远不如我手机上的OCR软件,所以 在教育意义上排名靠前,在实用意义上几乎垫底。
对于微软的OCR表单识别而言,首先这是一种比较新颖的OCR文本识别的方向——标记tag,训练模型,对同一种样式的表单进行持久的预测,其次是软件的可定制能力强大,对于待识别的样本,可以自定义想要什么部分,丢弃什么部分,只提供用户希望得到的值的预测结果,最后是识别准确率相当之高,所以在同类的产品中可以排到前列。
作业第三部分:建议和规划
这里只讨论微软的OCR,因为轻量级的OCR从各个角度而言都太不成熟了,不适合讨论一下的具体发展的问题。
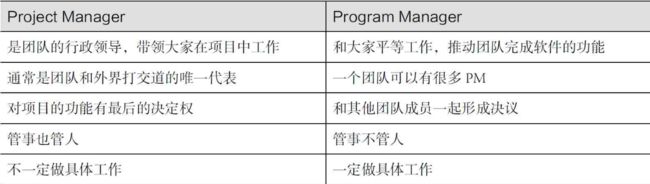
现在假设我是微软OCR开源软件的PM,在微软中PM是Program Manager,这里可以重温一下Program Manager的定义和任务:
- 一句话来讲:
做开发和测试之外的所有事情 - 展开来讲:
- 和客户交谈,组织用户调查,发现用户需求
- 了解和比较竞争对手的产品
- 怎么让软件变得可用(Usable)、有用(Useful)
- 怎么改进团队的流程
- 对比来讲:
- 比喻来讲:
PM就是龙舟队里面的舵手,掌控着龙舟前进的方向,如果舵手也参与到划船中,可能小船的速率会快一些,但是小船的方向、稳定性会出问题。
市场有多大?潜在的用户有多少?
微软OCR面向的是生活中的一切要用到规范化的表单的地方,无论是政府机构签署协议还是金融机构签署成交单,只要有表单出现的地方都可以使用,市场需求极大,潜在的客户极多。
同类产品比较
这里拿阿里云市场中的一个OCR表单识别服务进行比较,可以看出:
- 首先阿里云提供的是接口服务,需要有计算即能力的人进行编程和API的配置,但微软OCR提供线上的网站使用,无需配置API,只需要存放文件到 Azure 并进行网站上的配置。
微软在线使用网站:
阿里云市场售卖的API:
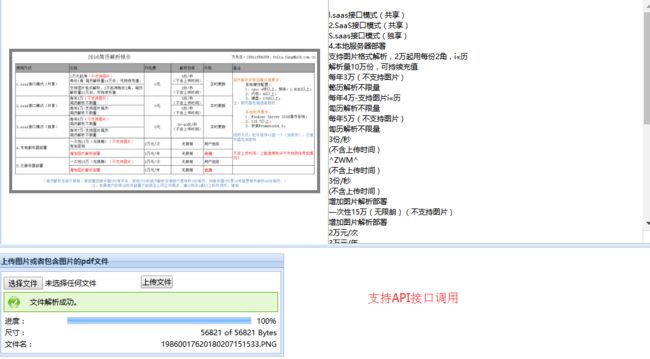
- 其次,微软OCR支持自定义识别区域,得到想要的,丢弃无用的,无需进行表单的裁剪,直接选择即可,返回得到的结果都存放在tag内,以JSON文件形式输出,可以提供给python直接进行数据处理;但阿里云市场提供的API服务一次识别一个表单,不能设置需要的内容,只能全部返回,并且使用前需要对待识别表单进行裁剪,返回的是识别的所有文字进行简单的换行分割的结果,需要人工选取里面的有效数据。
- 最后,微软OCR可以识别手写字体;阿里云市场提供的OCR服务只能识别印刷文字表格,功能较为单一薄弱。
产品的核心用户群定位
个人认为,微软OCR是一款toB的开源软件,主要还是提供给商业用途。用户画像为成熟的商业客户,需要处理大量的同等样式的表单文件,需要此服务进行自动化的有效信息提取并整理。
潜在需求可能是希望能够再提供一个直接连接数据库的功能,识别完成后直接将对应的信息存至云端(如Azure)的数据库的各个对应字段中。
设计功能
- 目前认为最需要的功能是提供多元的云端存储服务,而不是仅限于Azure一家,但这其实也是自家的产品竞争力的体现,如果开通了腾讯云和阿里云等国内的云服务厂商,用户数量虽然会增加,但是无法带动微软自身的云服务的兴起,是需要权衡的一个点。
- 还有就是上面所说的再提供一个optional的数据库连接接口,使得整套 表单识别-信息提取-数据存储 一条龙服务,实现完全自动化,不需要用户手动处理JSON文件的识别结果。
- 最后一个也是比较难实现的——表单预提取,意思是在遇到一个表单中的表格时,预先将表格中可能出现的tag 和对应的 value 提取出来直接供用户勾选需要的 tag-value,这样可以使得标签的制作更加高效。我自己在尝试制作标签的时候就发现,其实微软的OCR自己是已经看到表格的,看到表格之后其实就可以根据空格和换行和横竖线进行每一个小块的文字的提取了,一般而言,tag在前,value在后,中间用空格或冒号进行分割,我认为其实已经可以做到了。

团队规划
如果你有钱可以招聘6个人,有4个月的时间,你作为项目经理,应该如何配置角色(开发,测试,美工等等)?描述你的团队在16周期间每周都要做什么,才能在第16周如期发布软件的改进版本,并取得预想中的成绩。
这个问题我有些不好回答,因为我确实没有团队开发的经历,在这里回答也只是天马行空,没有背后的经验作为支撑,言论不堪一击,所以我希望老师和助教能够在这道题上给我一些启发和建议,也让我在后期的团队任务中能够亲身经历和践行。
参考连接
- MicroSoft | 智能表单信息抽取识别
- 智能表单信息抽取识别在线测试网站
- ouyanghuiyu | 超轻量级中文ocr
- MisTariano | OCR-Form-Tools项目本地试玩记录
- CSDN | Python构建快速高效的中文文字识别OCR
- cnblogs | python3使用web.py遇到的找不属性的错误解决
- 阿里云 | OCR表单识别(愚公OCR)