OKHttp的使用和类关系
本文目的是对OkHttp 框架及其中的常用概念(类)做简单性介绍。
简介
OKHttp 是 Square 公司开发的一款网络框架,其设计和实现的目的就是高效。OkHttp框架完整的实现了 HTTP 协议,支持的协议有 HTTP/1.1、SPDY、HTTP/2.0 。在 Android 4.4 的源码中 HttpURLConnection 已经被替换成OkHttp。
既然 OkHttp 的招牌是高效,那它是如何实现的呢?
- 采用连接池技术减少
- 默认使用 GZIP 数据压缩格式,降低传输内容的大小
- 采用缓存避免重复的网络请求
- 支持SPDY、HTTP/2.0,对于同一主机的请求可共享同一socket连接
- 若SPDY或HTTP/2.0 不可用,还会采用连接池提高连接效率
- 网络出现问题、会自动重连(尝试连接同一主机的多个ip地址)
- 使用 okio 库简化数据的访问和存储
简单使用
下面是一个使用 OkHttp 的同步 GET 请求的简单例子,这个例子要做的就是用 GET 请求 https://publicobject.com 域名上的一个名叫helloworld.txt 的文本资源,并将其内容打印(实际上打印文本前先打印的响应头)。那么它是怎么做的呢?第一步,用 URL 描述该资源,并用其构建一个 Request 对象;第二步,OkClient 把 Request 封装成一个 Call 对象,第三步执行Call 的execute()方法,得到 Response 响应;第四步,打印响应头和响应体。整体逻辑还是比较清楚的,如果你对 Request、Response、Call等感到困惑,继续看下文就对了。
本文不对使用教程做更多介绍,更多范例可参考官方wiki或者OkHttp使用教程。
private final OkHttpClient client = new OkHttpClient();
public void run() throws Exception {
Request request = new Request.Builder()
.url("http://publicobject.com/helloworld.txt")
.build();
Response response = client.newCall(request).execute();
if (!response.isSuccessful()) throw new IOException("Unexpected code " + response);
Headers responseHeaders = response.headers();
for (int i = 0; i < responseHeaders.size(); i++) {
System.out.println(responseHeaders.name(i) + ": " + responseHeaders.value(i));
}
System.out.println(response.body().string());
}
Okhttp常用概念
OkHttpClient
OkHttpClient 可以说是整个OkHttp 框架的一个门面(Facade 模式),在使用 OkHttp 框架时只需同OkHttpClient 打交道,而不用考虑其内部复杂的构成。这个类的职责就是配置参数和生成 Call 对象,配置参数包括:超时时间(连接、读、写)、代理服务器、Dns、协议和连接规范、缓存配置,拦截器、证书验证等。
官方建议是一个工程只配置一个 OKHttpClient 来处理所有的网络请求。
Request & Response& Call
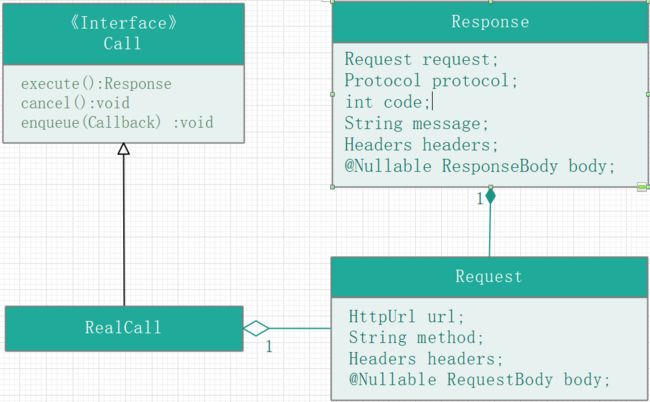
Request
Request 是 一个基本的 HTTP 网络请求,包括要请求的URL,同 HTTP 规范一样,它需要包含请求行,请求头,请求体(可以为空)。
Response
An HTTP response. Instances of this class are not immutable: the response body is a one-shot value that may be consumed only once. All other properties are immutable.
Response 即为网络响应,包括响应行,响应头和响应体(允许为空), 响应体只能被消费一次,且除响应体外的属性不可变。
Call & RealCall
A call is a request that has been prepared for execution. A call can be canceled. As this object represents a single request/response pair (stream), it cannot be executed twice.
Call 是一个接口,实现了对 Request 的封装,可以看做是一次请求任务,可以同步(execute)、异步(enqueue)执行,也可以取消 (cancel) 或者查询当前任务状态 。RealCall 是 Call 的一个子类,对其接口中定义的方法做了实现。
Connections
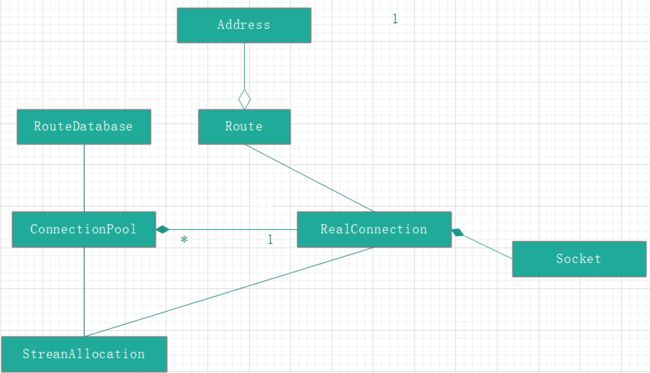
OKHttp 对用户很友好,使用时只需传入一个 URL 就可以了。但是对于OkHttp 内部实现来说,它需要3种类型的数据:URL、Address、Route。
URLs
URLs (like https://github.com/square/okhttp) are fundamental to HTTP and the Internet. In addition to being a universal, decentralized naming scheme for everything on the web, they also specify how to access web resources.
URLs (例如 https://github.com/square/okhttp) 是 HTTP 和互联网的基础。除了为互联网上的事物提供通用的命名方案之外(如 http、ftp、smtp 等),还规定了如何访问网络资源。
URLs are abstract:
- They specify that the call may be plaintext (http) or encrypted (https), but not which cryptographic algorithms should be used. Nor do they specify how to verify the peer's certificates (the HostnameVerifier) or which certificates can be trusted (the SSLSocketFactory).
- They don't specify whether a specific proxy server should be used or how to authenticate with that proxy server.
URLs 是抽象的,他们规定一次 Call 可以是明文的(http)也可以是加密的(https),但是既不指定加密算法,也不指定如何校验对方证书; 既不指定是否使用特定的代理服务器,也不指定如何认证到代理服务器。
They're also concrete: each URL identifies a specific path (like /square/okhttp) and query (like ?q=sharks&lang=en). Each webserver hosts many URLs.
URLs 同时也是具体的,每一个URL 标识一个特定的路径(如 /square/okhttp)和查询(? q = sharks&lang = en)。每一个Web 服务器 可以持有很多URLs。
小结:以上是对官方 WiKi 对 URL 的解释,其实就是在讲 URI(URL 是 URI 的子集) 的语法,明白语法就明白一切了。语法可参考 URI详解 。
Address
- Address 指定了一个 web 服务器(如 github.com)的地址和所有连接到此服务器所必须的静态配置: 端口号、https设置,首选网络协议(如 HTTP/2.0、SPDY)。
- 持有同一Address的 URLs 可以共享底层的 socket 连接,共享连接在性能上有巨大的优势: 低延迟、高吞吐量(主要由于 TCP 的慢启动)、低耗电。OkHttp 采用连接池自动重用 HTTP/1.x 的连接和复用 HTTP/2.0 和 SPDY 的连接。
- 在 OkHttp 中,Address 的一些字段来自 URL(如协议名、主机名、端口号),其余配置信息来自 okHttpClient 。
Route
Route 提供了连接到 Web 服务器所需要的动态信息,包括特定的 IP 地址(如经过 DNS 查询后返回的地址队列),要使用的代理服务器,TLS 版本信息等。
对于一个 Address 可能有多个 Route 信息。
Connection
Connection 代表指向源服务器或代理服务器的一个真实连接,在这个连接上可以传输 HTTP 请求、响应。
当用 OkHttp 请求一个 URL 的时候,它将会:
- 1、它会用 URL 和已经配置好的 okhttpClient 创建一个 Address 对象,这个 Address 指定我们将如何连接到 web服务器。
- 2、尝试从连接池中检索与此 Address 对应的连接是否存在
- 3、如果该连接不存下,则它将尝试选择一个 Route 去连接。这也就意味着 从发送一个请求去解析服务器的 IP 地址,如果有必要的话选择一个代理服务器和 TLS 版本。
- 4、如果这是一个新的 Route,则有三种连接方式:直接的 Socket 连接;TLS 隧道(在代理服务器上使用 HTTPS 的时候);直接的 TLS 连接。必要的时候会进行 TLS 握手。
- 5、连接建立后便可以发送请求和读取响应了。
当 Connection 发生问题的时候,OkHttp 会重新选择一个 Route 并且重试。这意味着当服务器的IP 地址的一个子集不可用的时候,OkHttp 可以重新尝试连接。并同样适用于ConnectionPool 中的连接失效或者所选 TLS 版本不受支持的情况。
ConnectionPool
Manages reuse of HTTP and SPDY connections for reduced network latency. HTTP requests that share the same Address may share a Connection. This class implements the policy of which connections to keep open for future use.
The system-wide default uses system properties for tuning parameters:
- http.keepAlive true if HTTP and SPDY connections should be pooled at all. Default is true.
- http.maxConnections maximum number of idle connections to each to keep in the pool. Default is 5.
- http.keepAliveDuration Time in milliseconds to keep the connection alive in the pool before closing it. Default is 5 minutes. This property isn’t used by HttpURLConnection.
The default instance doesn’t adjust its configuration as system properties are changed. This assumes that the applications that set these parameters do so before making HTTP connections, and that this class is initialized lazily.
由于持有同一 Address 的 Request 可以共享一个 Connection,为了减少网络延迟而选择了重用 Connection。ConnectionPool 就是实现管理这些连接的一个策略类,它规定了连接池中哪些类可以重用。
HTTP 或者 SPDY 连接默认是长连接,且默认会添加到连接池中;连接池有最大空连接数限制,默认值为5;一个空连接能保持的最大时长为 5 分钟,超过这个时间这个 Connection 对象将会被回收。
StreamAllocation
字面意思为“流分配”,这个流指的是在 物理连接上传输的数据流 ,数据流就是逻辑上的就是 HTTP Request/Response 键值对。
这个类的职责是协调三个实体之间的关系:Connections、Streams、Calls。
- Connection 的建立有可能会很慢,因此有必要在建立 Connection 的过程中可以取消。
- Streams,每个 Connection 有自己的流分配策略:在一个连接上最大可承载多少 Streams.HTTP/1.x 只能承载一个,SPDY 和 HTTP/2.0 可以由于可多路复用可承载多个。
- Calls ,是 Streams 组成的逻辑序列,典例就是最初的 Request 请求和 该请求的一系列重定向请求。
Interceptors
拦截器是一个功能强大的机制,可以监视,重写和重试 Call。通常情况下,拦截器用来添加、移除和转换 Request 和 Response 的头部信息。
在 OkHttp 中,对于对请求 Request 的不同处理,细化出多个拦截器,例如
BridgeInterceptor:负责把用户构造的请求转换为发送到服务器的请求、把服务器返回的响应转换为对用户友好的响应。
RetryAndFollowUpInterceptor:负责连接失败后重试和重定向。
CacheInterceptor:缓存拦截器,负责读取缓存和更新缓存。
ConnectInterceptor:连接拦截器,负责从客户端到服务器的连接工作。
CallServerInterceptor:负责向服务器发送请求数据,并从服务器读取响应数据。
networkInterceptors:网络拦截器,配置 OkClient 时设置的拦截器,主要应用于真正发生网络请求的地方。
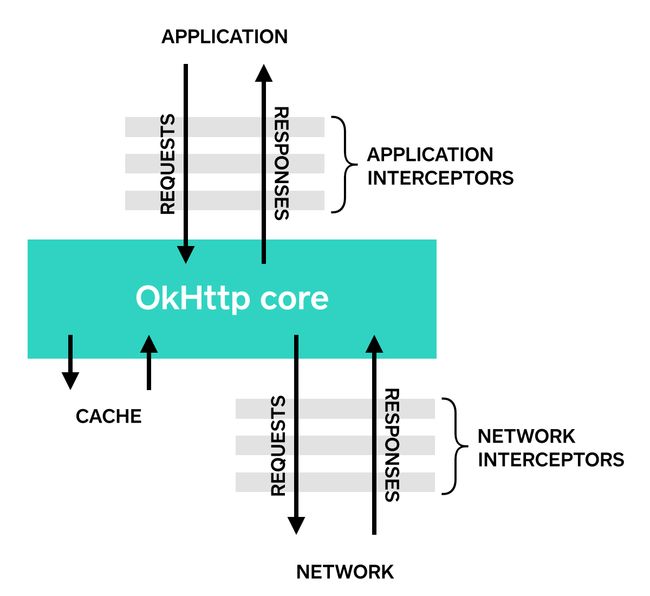
拦截器可以分为Application Interceptors (应用拦截器)和Network Interceptors(网络拦截器)。
先看图中的数据流向,从应用层看,只需关注上半部分即可,Application 发送一个 Request 给 OkHttp core , 再收取由 OkHttp core 返回的 Responses 。但是对于 OkHttp core 内部实现来说,这个 Response 有可能是从缓存获取的,也有可能是实际从服务器端拉取的数据。当从服务器拉取数据时,网络拦截器便派上用场了。
Interceptor.Chain
拦截器链,顾名思义就是由许多拦截器组成的链,对于一个 Request 从发送到接收 Response 过程中,许多拦截器都要参与其中。对其工作方式的理解可以参考责任链模式,因为 OkHttp 中的拦截器链正是这一设计模式的实现。在链上拦截器是有处理顺序的,它们的排列顺序就是拦截器处理 Request 的顺序,如代码所示。
在职责链模式里,很多对象由每一个对象对其下家的引用而连接起来形成一条链。请求在这个链上传递,直到链上的某一个对象决定处理此请求。发出这个请求的客户端并不知道链上的哪一个对象最终处理这个请求,这使得系统可以在不影响客户端的情况下动态地重新组织链和分配责任。
Response getResponseWithInterceptorChain() throws IOException {
// Build a full stack of interceptors.
List interceptors = new ArrayList<>();
interceptors.addAll(client.interceptors());
interceptors.add(retryAndFollowUpInterceptor);
interceptors.add(new BridgeInterceptor(client.cookieJar()));
interceptors.add(new CacheInterceptor(client.internalCache()));
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket) {
interceptors.addAll(client.networkInterceptors());
}
interceptors.add(new CallServerInterceptor(forWebSocket));
Interceptor.Chain chain = new RealInterceptorChain(
interceptors, null, null, null, 0, originalRequest);
return chain.proceed(originalRequest);
}
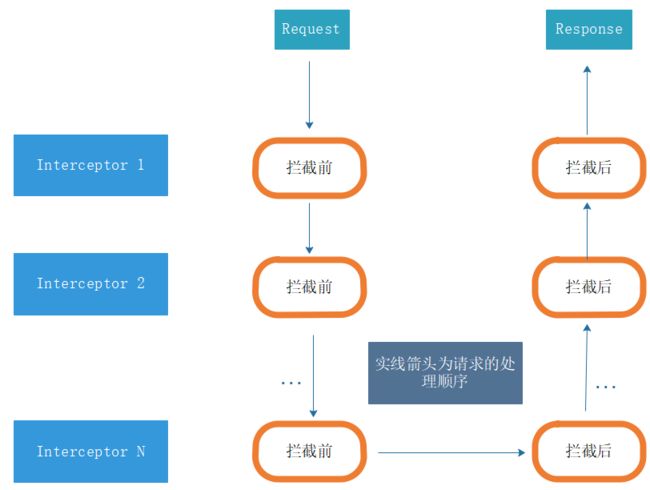
下图是拦截器链的工作方式,拦截器链是对 AOP(Aspect Oriented Programming,面向切面编程) 设计的一种实现,针对 Request 和 Response 做了切面处理。在拦截前,主要针对Request 做相关处理;拦截后,对 Response 做相关处理。拦截器N 多为实际发生网络请求的地方,对应的拦截器为 CallServerInterceptor 。
Cache & CacheStrategy
Cache 即缓存,是对于某一特定 Request 的缓存,缓存的内容为该 Request 的 Response ,缓存多以<请求、响应>键值对的形式存在。缓存可以为内存,也可以为硬盘,缓存可以进行失效时间、最大容量、缓存目录等设置。
CacheStrategy 即缓存策略,即当用 OkHttp 请求一个 Request 时,是采用缓存还是网络还是两者皆用。
参考文献
https://github.com/square/okhttp/wiki