当我们决定把产品定位在企业市场时,因为企业的数据的多元化,数据经过整合后接入分析平台是很必要的。传统的办法是使用ETL来完成,而实际上我们期望这样的过程更加的平滑、可视,而且能跟hadoop生态圈,以及层出不穷的存储分析组件能对接起来。当看到Hortonworks的DataPlatform组件后,类似的产品概念更加清晰起来。Hortonworks是用NiFi做的,我们希望这样的数据传送平台,让我们从数据流动的维度,编排数据的处理过程,这种接近“万能”的工具就是工作流引擎。我们通过对NiFi从多个维度进行评价,以期在项目和产品中合理使用,提高数据转送的效率。
Apache NiFi 是一个web项目,安装部署好后,打开如上图的页面。可以通过拖拽的方式设置操作及节点和流程。

操作类型主要是Processor,NiFI提供的Processor有上百个,也支持自己封装新的Processor。Processor可以分为两大类
具体的功能性的Processor,比如putHDFS、ExecuteSQL、ConvertCSVToAvro
通用的Processor,可以在里面支持第三方的操作,比如ExecuteScript、ExecuteProcess

通过拖拽Processor,把操作拼接起来成为一个workflow。
下面是一个把PostgreSQL中一个表的数据导出到Apache HAWQ的过程。数据需要在HDFS缓存后,再load进HAWQ。
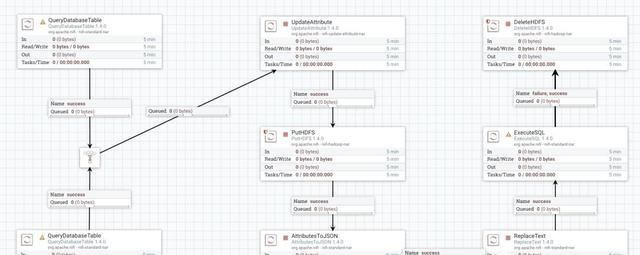
复杂的workflow可以保存成模板,以便以后复用。也可以封装Processor,Processor的开发基于maven进行,开发完成后放入NiFi的目录即可使用。
NiFi主要的特性有
Web-based user interface
Seamless experience between design, control, feedback, and monitoring
Highly configurable
Loss tolerant vs guaranteed delivery
Low latency vs high throughput
Dynamic prioritization
Flow can be modified at runtime
Back pressure
Data Provenance
Track dataflow from beginning to end
Designed for extension
Build your own processors and more
Enables rapid development and effective testing
Secure
SSL, SSH, HTTPS, encrypted content, etc...
Multi-tenant authorization and internal authorization/policy management
基于这些特性,我们主要从我们认为的产品生态方面,结合对Apache HAWQ的数据导入,对NiFi做了评估。
数据源的支持功能
ETL的功能
性能
实际项目中的使用场景
功能的扩展
离线文件导入数据库
以NiFi将文件写入HDFS然后执行SQL使用pxf插件进行数据导入。测试时在处理超过2GB的文件时会发生SQL执行超时报错,需要通过将文件进行预分割进行处理。
从数据库导入数据
通过NiFi将源数据库数据导出为avro格式并写入HDFS,然后使用HAWQ的pxf插件进行导入。源表过大时NiFi会发生栈空间不足,处理能力约在单表5000万条记录左右。
聚合等预处理的支持
NiFi自身没有对聚合计算提供processor,但可以通过自定义processor或调用脚本进行处理。
错误处理
没有健全的容错处理和重试机制。以Apache HAWQ的场景为例,所有数据导入都是通过外部表挂载,然后insert into table select * 的方式进行导入的,并且每个流程只能对单张表进行数据操作。在发生数据类型不匹配等错误时,当前处理的所有数据都会被丢弃,并且ExecuteSQL这个processor会留下报错的log。需要通过后续的更新配置进行重试。
NiFi的Cluster
NiFi支持cluster的方式并行执行workflow。无需配置主从,节点会自动进行选举。web页面访问任意节点均可,Dashboard会在所有节点间同步。使用资源可以监控,包括每个节点的uptime,queue资源,系统cpu信息,jvm信息,磁盘使用状况。但是只能进行监控不能进行调度,能够操作的只有将某个节点从cluster中断开。cluster模式下对于一些调用了本地文件的操作,比如getfile和puthdfs,需要所有节点在相同位置有同样的文件,否则processor无法运行。
第三方库的使用
NiFi是个运行框架,功能可以扩展。
分两种情况:
1)执行脚本,可以通过ExecuteScript直接对FLowFile进行处理,支持Clojure、Groovy、lua、python、ruby
2)直接调用服务器上的可执行文件,通过ExecuteProcess即可。
与Kettle协作
NiFi对ETL的支持非常有限,有一个美好的想法是用专业的ETL工具跟NiFi这种流转引擎协作使用。遗憾的是NiFi无法与Kettle直接结合使用,但是可以通过预先编写好Kettle的ktr转换文件,然后通过processor进行调用。
使用场景
1)在我们工业大数据平台项目中,NiFi可以做到整体替代Flume的作用,并且配置上较Flume相对更为简单,读取文件后可以直接将文件作为kafka的message发送。此外在替代Streaming组件直接进行数据文件解析并存入数据库这方面,理论上是可行的,但是处理能力有待验证,并且上述文件采集的具体性能也需要进行大量文件的实际验证。
2)在我们的金融数据仓库中,试用了两种更新策略,一是本地更新时同时保存一份增量csv数据文件,然后以离线数据文件方式导入;二是以增量表方式更新,原有数据库更新时的增量表不进行即时删除,而是待HAWQ同步完成后再行删除,使用NiFi是可以完成的。
UI的改造开发
NiFi的界面有些编程风格,需要有工程师习惯的人才好接受。是作为项目交付中的一个工具,还是作为一个开放的可配置的工作台,对交互的要求是不一样的。官方文档里提及了可以制作自定义UI,如果想改造,需要不少的二次开发的工作。
关于NiFI的使用案例
NiFi虽然是Apache的顶级项目了,实际用的人不多。在NiFi的官网上,给出了一些使用NiFi的公司,数量还比较少,也不是以案例分享的方式。另外在Github上,NiFi活跃度还不够。
总体来说,Apache NiFi是一个让人耳目一新的数据平台工具,在实际项目中,可以从数据流动的视图来定义开发流程。由于在实时处理和容错可靠性上有些不确定,目前判断适合在中小型项目中使用。我们会在后续的工作中,加深对NiFi的使用场景的理解。