读完MySQL必知必会系列一,我们可以进一步了解MySQL中的数据处理函数,分组查询,联结表,以及组合查询的相关内容,方便我们进一步查询数据,处理成我们想要的结果
- 一 数据处理函数
- 函数
- 文本处理函数
- 日期和时间处理函数
- 日期比较
- 数值处理函数
- 二 汇总数据
- 聚集函数
- AVG()
- COUNT()
- MAX()
- MIN()
- SUM()
- 聚集不同值
- 组合聚集函数
- 聚集函数
- 三 分组数据
- 创建分组 GROUP BY
- 过滤分组 HAVING
- 分组和排序
- SELECT 子句顺序
- 四 使用子查询
- 作为计算字段使用子查询
- 五 联结表(重点)
- 关系表
- 外键
- 可伸缩性(scale)
- 为什么使用联结?
- 笛卡儿积
- 创建联结
- 内部联结
- 联结多个表
- 总结(重点)
- 六 创建高级联结
- 使用表别名
- 自联结
- 自然联结
- 外部联结
- 带有聚合函数的联结
- 七 组合查询
- 创建组合查询
- UNION规则
- 包含或取消重复的行
- 对组合查询结果排序
- 总结
一 数据处理函数
函数
SQL 支持利用函数来处理数据。函数一般是在数据上执行的,它给数据的转换和处理提供了方便
如果你决定使用函数,应该保证做好代码注释,以便以后你(或其他人)能确切地知道所编写 SQL 代码的含义。
- 用于处理文本串(如删除或填充值,转换值为大写或小写)的文本函数
- 用于在数值数据上进行算术操作(如返回绝对值,进行代数运算)的数值函数
- 用于处理日期和时间值并从这些值中提取特定成分(例如,返回两个日期之差,检查日期有效性等)的日期和时间函数
- 返回 DBMS 正使用的特殊信息(如返回用户登录信息,检查版本细节)的系统函数。
文本处理函数


//Upper() 将文本转换为大写
select vend_name,UPPER(vend_name) AS vend_name_upcase from vendors ORDER BY vend_name
+--------------+------------------+
| vend_name | vend_name_upcase |
+--------------+------------------+
| ACME | ACME |
| Anvils R Us | ANVILS R US |
| Furball Inc. | FURBALL INC. |
| LT Supplies | LT SUPPLIES |
+--------------+------------------+
4 rows in set (0.00 sec)
日期和时间处理函数
日期和时间采用相应的数据类型和特殊的格式存储,以便能快速和有效地排序或过滤,并且节省物理存储空间
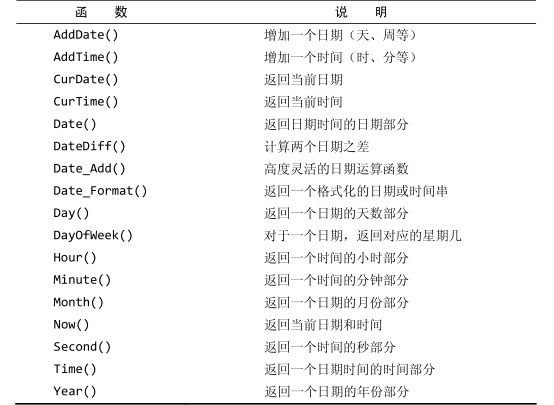
MySQL 使用的日期格式。无论你什么时候指定一个日期,不管是插入或更新表值还是用 WHERE 子句进行过滤,日期必须为格式 yyyy-mm-dd
select * from orders WHERE order_date='2005-09-01'
order_date 的数据类型为 datetime 。这种类型存储日期及时间值, 比如,存储的 order_date 值为2005-09-01 11:30:05 ,则WHERE order_date = '2005-09-01' 匹配失败
解决办法是指示 MySQL 仅将给出的日期与列中的日期部分进行比较,而不是将给出的日期与整个列值进行比较如果要的是日期,请使用 Date().使用 Date() 是一个良好的习惯
select * from orders WHERE DATE(order_date)='2005-09-01'
+-----------+---------------------+---------+
| order_num | order_date | cust_id |
+-----------+---------------------+---------+
| 20005 | 2005-09-01 00:00:00 | 10001 |
+-----------+---------------------+---------+
1 row in set (0.00 sec)
日期比较
如果你想检索出 2005 年 9 月下的所有订单
- 方案一:
BETWEEN 操作符用来把 2005-09-01 和 2005-09-30 定义为一个要匹配的日期范围
select * from orders WHERE DATE(order_date) BETWEEN '2005-09-01' AND '2005-09-30';
- 方案二:
Year() 是一个从日期(或日期时间)中返回年份的函数。类似,Month() 从日期中返回月份
select * from orders WHERE YEAR(order_date) = 2005 and MONTH(order_date)=9;
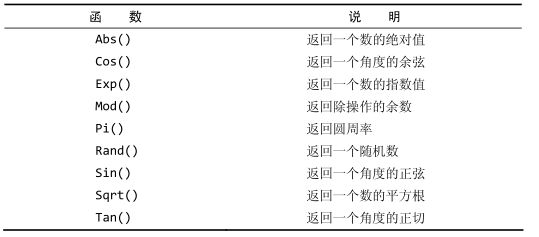
数值处理函数
数值处理函数仅处理数值数据。这些函数一般主要用于代数、三角或几何运算
二 汇总数据
我们经常需要汇总数据而不用把它们实际检索出来,MySQL 提供了专门的函数。使用这些函数,MySQL 查询可用于检索数据,以便分析和报表生成
聚集函数

AVG()
通过对表中行数计数并计算特定列值之和,求得该列的平均值
SELECT AVG(prod_price) as avg_price from products
SELECT AVG(prod_price) as avg_price from products WHERE vend_id=1003
COUNT()
利用 COUNT() 确定表中行的数目或符合特定条件的行的数目
- 使用 COUNT(*) 对表中行的数目进行计数,不管表列中包含的是空值( NULL )还是非空值
select count(*) from products
- 使用 COUNT(column) 对特定列中具有值的行进行计数,忽略 NULL
select count(cust_email) from customers
MAX()
返回指定列中的最大值。 MAX() 要求指定列名
MIN()
返回指定列的最小值。与 MAX() 一样, MIN() 要求指定列名
SUM()
用来返回指定列值的和(总计)。
举一个例子, orderitems 表 包含订单中实际的物品,每个物品有相应的数量( quantity )。可如下检索所订购物品的总数(所有 quantity 值之和)
select SUM(quantity) as items_ordered from orderitems where order_num=20005
//总销售量
select SUM(quantity*item_price) as total_price from orderitems where order_num=20005
聚集不同值
以上 5 个聚集函数都可以如下使用:
- ALL 为默认值, 对所有的行执行计算,指定 ALL 参数或不给参数;
- 只包含不同的值,指定 DISTINCT 参数
// 指定 DISTINCT 参 因此平均值只考虑各个不同的价格
SELECT avg(DISTINCT prod_price) as avg_price from products
组合聚集函数
select count(*) as num_items,MIN(prod_price),MAX(prod_price),AVG(prod_price) from products
三 分组数据
创建分组 GROUP BY
分组是在 SELECT 语句的 GROUP BY 子句中建立的
select vend_id,count(*) as num_prods from products GROUP BY vend_id
使用 WITH ROLLUP 关键字,可以得到每个分组以及每个分组汇总级别(针对每个分组)的值
select vend_id,count(*) as num_prods from products GROUP BY vend_id WITH ROLLUP
过滤分组 HAVING
HAVING 子句。 HAVING 非常类似于 WHERE,唯一的差别是 WHERE 过滤行,而 HAVING 过滤分组
//过滤 COUNT(*) >=2 (两个以上的订单)的那些分组
select cust_id,count(*) as ordersTotal from orders GROUP BY cust_id HAVING COUNT(*) >=2
HAVING 和 WHERE 的差别 这里有另一种理解方法, WHERE 在数据分组前进行过滤, HAVING 在数据分组后进行过滤。这是一个重要的区别,WHERE 排除的行不包括在分组中。这可能会改变计算值,从而影响 HAVING 子句中基于这些值过滤掉的分组。
分组和排序
一般在使用 GROUP BY 子句时,应该也给出 ORDER BY 子句。这是保证数据正确排序的唯一方法。千万不要仅依赖 GROUP BY 排序数据。
SELECT 子句顺序
| 子句 | 说明 | 是否必须使用 |
|---|---|---|
| select | 要返回的列或表达式 | 是 |
| FROM | 从中检索数据的表 | 仅在从表选择数据时使用 |
| WHERE | 行级过滤 | 否 |
| GROUP BY | 分组说明 | 仅在按组计算聚集时使用 |
| HAVING | 组级过滤 | 否 |
| ORDER BY | 输出排序顺序 | 否 |
| LIMIT | 要检索的行数 | 否 |
四 使用子查询
查询(query) 任何 SQL 语句都是查询。但此术语一般指 SELECT 语句,子查询(subquery),即嵌套在其他查询中的查询
products 表包含产品目录,每行一个产品
customers 表存储所有顾客的信息
orders 表存储顾客订单 ,orders 表不存储客户信息。它只存储客户的 ID
orderitems 表存储每个订单中的实际物品
//prod_id 为 TNT2 的所有订单物品
select order_num from orderitems WHERE prod_id="TNT2";
//下一步,查询具有订单 20005 和 20007 的客户ID
select cust_id from orders where order_num in(20005,20007)
//得到了订购物品 TNT2 的所有客户的ID。下一步是检索这些客户ID的客户信息
select cust_name,cust_contact from customers where cust_id in (10001,10004)
现在组合成一条语句,MySQL 实际上必须执行 3 条 SELECT 语句,可见,在 WHERE 子句中使用子查询能够编写出功能很强并且很灵活的 SQL 语句,不过在实际使用时由于性能的限制,不能嵌套太多的子查询
SELECT
cust_name,
cust_contact
FROM
customers
WHERE
cust_id IN (
SELECT
cust_id
FROM
orders
WHERE
order_num IN (
SELECT
order_num
FROM
orderitems
WHERE
prod_id = "TNT2"
)
)
作为计算字段使用子查询
假如需要显示 customers 表中每个客户的订单总数
SELECT
cust_id,
cust_name,
(
SELECT
COUNT(*)
FROM
orders
WHERE
orders.cust_id = customers.cust_id
) AS total
FROM
customers
ORDER BY
total
相关子查询语法:任何时候只要列名可能有多义性,就必须使用这种语法(表名和列名由一个句点分隔)
五 联结表(重点)
SQL 最强大的功能之一就是能在数据检索查询的执行中联结,表联结是利用 SQL 的 SELECT 能执行的最重要的操作,在能够有效地使用联结前,必须了解关系表以及关系数据库设计的一些基础知识面的介绍,并不是这个内容的全部知识,但作为入门已经足够了
关系表
假如有一个包含产品目录的数据库表,其中每种类别的物品占一行。对于每种物品要存储的信息包括产品描述和价格,以及生产该产品的供应商信息
现在,假如有由同一供应商生产的多种物品,那么在何处存储供应商信息(如,供应商名、地址、联系方法等)呢? 将这些数据与产品信息分开存储的理由如下:
1. 因为同一供应商生产的每个产品的供应商信息都是相同的,
对每个产品重复此信息既浪费时间又浪费存储空间
2. 如果供应商信息改变(例如,供应商搬家或电话号码变动),只需改动一次即可
3. 如果有重复数据(即每种产品都存储供应商信息),
很难保证每次输入该数据的方式都相同。不一致的数据在报表中很难利用
关系表的设计就是要保证把信息分解成多个表,一类数据一个表。各表通过某些常用的值(即关系设计中的关系(relational))互相关联,在这个例子中,可建立两个表,一个存储供应商信息,另一个存储产品信息。 vendors 表包含所有供应商信息,每个供应商占一行,每个供应商具有唯一的标识。此标识称为主键(primary key),products 表只存储产品信息,它除了存储供应商 ID( vendors 表的主键)外不存储其他供应商信息。 vendors 表的主键又叫作 products 的外键,它将 vendors 表与 products 表关联,利用供应商 ID 能从 vendors 表中找出相应供应商的详细信息。
外键
外键(foreign key) 外键为某个表中的一列,它包含另一个表的主键值,定义了两个表之间的关系,总之,关系数据可以有效地存储和方便地处理。因此,关系数据库的可伸缩性远比非关系数据库要好
可伸缩性(scale)
能够适应不断增加的工作量而不失败。设计良好的数据库或应用程序称之为可伸缩性好(scale well)
为什么使用联结?
分解数据为多个表能更有效地存储,更方便地处理,并且具有更大的可伸缩性。但这些好处是有代价的,如果数据存储在多个表中,怎样用单条 SELECT 语句检索出数据?
答案是使用联结。简单地说,联结是一种机制,用来在一条 SELECT
语句中关联表,因此称之为联结。使用特殊的语法,可以联结多个表返
回一组输出,联结在运行时关联表中正确的行。
笛卡儿积
笛卡儿积(cartesian product):由没有联结条件的表关系返回的结果,就称为为笛卡儿积。检索出的行的数目将是第一个表中的行数乘以第二个表中的行数。
select * from vendors,products
where vendors.vend_id=products.vend_id
order by vend_name,prod_name
笛卡尔乘积是指在数学中,两个集合X和Y的笛卡尔积(Cartesian product),又称直积,
表示为X×Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员 [3] 。
假设集合A={a, b},集合B={0, 1, 2},
则两个集合的笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}。
类似的例子有,如果A表示某学校学生的集合,B表示该学校所有课程的集合,
则A与B的笛卡尔积表示所有可能的选课情况。
A表示所有声母的集合,B表示所有韵母的集合,
那么A和B的笛卡尔积就为所有可能的汉字全拼。
创建联结
SELECT
vend_name,
prod_name,
prod_price
FROM
vendors,
products
WHERE
vendors.vend_id = products.vend_id
ORDER BY
vend_name,
prod_name
内部联结
目前为止所用的联结称为等值联结(equijoin),它基于两个表之间的相等测试。这种联结也称为内部联结
对于这种联结可以使用稍微不同的语法来明确指定联结的类型以 INNER JOIN 指定。在使用这种语法时,联结条件用特定的 ON 子句而不是 WHERE 子句给出。传递给 ON 的实际条件与上面案例传递给 WHERE 的相同
SELECT
vend_name,
prod_name,
prod_price
FROM
vendors
INNER JOIN products ON vendors.vend_id = products.vend_id
ORDER BY
vend_name,
prod_name
联结多个表
SQL 对一条 SELECT 语句中可以联结的表的数目没有限制。创建联结的基本规则也相同。首先列出所有表,然后定义表之间的关系,然后用 where 定义联结关系
select order_name,vend_name,prod_name,prod_price
from table1,table2,table3
where table2.a=table3.a
and table1.b=table2.b
and order_num=2000
总结(重点)
- 性能考虑:MySQL 在运行时关联指定的每个表以处理联结。这种处理可能是非常耗费资源的,因此应该仔细,不要联结不必要的表。联结的表越多,性能下降越厉害
- 为执行任一给定的 SQL 操作,一般存在不止一种方法。很少有绝对正确或绝对错误的方法。性能可能会受操作类型、表中数据量、是否存在索引或键以及其他一些条件的影响。因此,有必要对不同的选择机制进行实验,以找出最适合具体情况的方法。
六 创建高级联结
使用表别名
表别名只在查询执行中使用。与列别名不一样,表别名不返回到客户机,可以帮助我们缩短 SQL 语句,允许在单条 SELECT 语句中多次使用相同的表
SELECT
cust_name,
cust_contact
FROM
customers AS c,
orders AS o,
orderitems AS oi
WHERE
c.cust_id = o.cust_id
AND oi.order_num = o.order_num
AND prod_id = 'TNT2'
自联结
假如你发现某物品(其 ID 为 DTNTR)存在问题,因此想知道生产该物品的供应商生产的其他物品是否也存在这些问题。此查询要求首先找到生产 ID 为 DTNTR 的物品的供应商,然后找出这个供应商生产的其他物品。
SELECT
prod_id,
prod_name
FROM
products
WHERE
vend_id = (
SELECT
vend_id
FROM
products
WHERE
prod_id = "DTNTR"
)
现在来看使用联结的相同查询
WHERE(通过匹配 p1 中 的 vend_id 和 p2 中的 vend_id)首先联结两个表,然后按第二个表中的 prod_id 过滤数据,返回所需的数据
SELECT
p1.prod_id,
p1.prod_name
FROM
products AS p1,
products AS p2
WHERE
p1.vend_id = p2.vend_id
AND p2.prod_id = "DTNTR"
自然联结
无论何时对表进行联结,应该至少有一个列出现在不止一个表中(被联结的列)。标准的联结(前一章中介绍的内部联结)返回所有数据,甚至相同的列多次出现。自然联结排除多次出现,使每个列只返回一次。
怎样完成这项工作呢?答案是,系统不完成这项工作,由你自己完成它。自然联结是这样一种联结,其中你只能选择那些唯一的列。这一般是通过对表使用通配符(SELECT *),对所有其他表的列使用明确的子集来完成的。
事实上,迄今为止我们建立的每个内部联结都是自然联结,很可能我们永远都不会用到不是自然联结的内部联结。
外部联结
许多联结将一个表中的行与另一个表中的行相关联。但有时候会需要包含没有关联行的那些行。例如,可能需要使用联结来完成以下工作:如:
- 对每个客户下了多少订单进行计数,包括那些至今尚未下订单的客户;
- 列出所有产品以及订购数量,包括没有人订购的产品;
- 计算平均销售规模,包括那些至今尚未下订单的客户。
在上述例子中,联结包含了那些在相关表中没有关联行的行。这种类型的联结称为外部联结
外部联结语法类似。为了检索所有客户,包括那些没有订单的客户,可如下进行
SELECT
c.cust_id,
o.order_num
FROM
customers AS c
LEFT OUTER JOIN orders AS o ON c.cust_id = o.cust_id;
类似于上一章中所看到的内部联结,这条 SELECT 语句使用了关键字 OUTER JOIN 来指定联结的类型(而不是在 WHERE 子句中指定)。但是,与内部联结关联两个表中的行不同的是,外部联结还包括没有关联行的行。在使用 OUTER JOIN 语法时,必须使用 RIGHT 或 LEFT 关键字指定包括其所有行的表(RIGHT 指出的是 OUTER JOIN 右边的表,而 LEFT 指出的是 OUTER JOIN 左边的表)。上面的例子使用 LEFT OUTER JOIN 从 FROM 子句的左边表(customers 表)中选择所有行
带有聚合函数的联结
此 SELECT 语句使用 INNER JOIN 将 customers 和 orders 表互相关联。GROUP BY 子句按客户分组数据,因此函数调用 COUNT(orders.order_num) 对每个客户的订单计数
SELECT
c.cust_id,
c.cust_name,
COUNT(o.order_num) AS order_total
FROM
customers c
INNER JOIN orders o ON c.cust_id = o.cust_id
GROUP BY
c.cust_id
七 组合查询
多数SQL查询都只包含从一个或多个表中返回数据的单条 SELECT 语句,MySQL允许执行多个查询(多条 SELECT 语句),并将结果作为单个查询结果集返回。这些组合查询通常称为并(union)或复合查询(compound query)
基本场景:
- 在单个查询中从不同的表返回类似结构的数据
- 对单个表执行多个查询,按单个查询返回数据。
创建组合查询
假如需要价格小于等于 5 的所有物品的一个列表,而且还想包括供应商 1001 和 1002 生产的所有物品(不考虑价格)。当然,可以利用 WHERE 子句来完成此工作,不过这次我们将使用 UNION
-- select * from products WHERE prod_price <=5;
-- select * from products WHERE vend_id in(1001,1002)
-- UNION 指示MySQL执行两条 SELECT 语句,并把输出组合成单个查询结果集
select * from products WHERE prod_price <=5
UNION select * from products WHERE vend_id in(1001,1002)
在这个简单的例子中,使用 UNION 可能比使用 WHERE 子句更为复杂。
但对于更复杂的过滤条件,或者从多个表(而不是单个表)中检索数据
的情形,使用 UNION 可能会使处理更简单。
UNION规则
UNION 必须由两条或两条以上的 SELECT 语句组成,语句之间用关键字 UNION 分隔(因此,如果组合4条 SELECT 语句,将要使用3个UNION 关键字)
UNION 中的每个查询必须包含相同的列、表达式或聚集函数(不过各个列不需要以相同的次序列出)
SELECT
prod_id,
prod_name
FROM
products
WHERE
prod_price <= 5
UNION
SELECT
prod_id,
prod_name
FROM
products
WHERE
vend_id IN (1001, 1002);
- 列数据类型必须兼容:类型不必完全相同,但必须是DBMS可以
隐含地转换的类型(例如,不同的数值类型或不同的日期类型)。
包含或取消重复的行
UNION 从查询结果集中自动去除了重复的行(换句话说,它的行为与单条 SELECT 语句中使用多个 WHERE 子句条件一样)。因为供应商 1002 生产的一种物品的价格也低于 5 ,所以两条 SELECT 语句都返回该行。在使用UNION 时,重复的行被自动取消
-- 第一条 SELECT 语句返回4行,第二条 SELECT 语句返回5行。
-- 但在用 UNION 组合两条 SELECT 语句后,只返回了8行而不是9行
`
-- selec`t * from products WHERE prod_price <=5;
-- select * from products WHERE vend_id in(1001,1002)
这是 UNION 的默认行为,但是如果需要,可以改变它。事实上,如果想返回所有匹配行,可使用 UNION ALL 而不是 UNION 。
UNION 几乎总是完成与多个WHERE 条件相同的工作。 UNION ALL 为 UNION 的一种形式,它完成WHERE 子句完成不了的工作。如果确实需要每个条件的匹配行全部出现(包括重复行),则必须使用 UNION ALL 而不是 WHERE
对组合查询结果排序
在用 UNION 组合查询时,只能使用一条 ORDER BY 子句,它必须出现在最后一条 SELECT 语句之后
对于结果集,不存在用一种方式排序一部分,而又用另一种方式排序另一部分的情况,因此不允许使用多条 ORDER BY 子句。
SELECT
prod_id,
prod_name,
vend_id,
prod_price
FROM
products
WHERE
prod_price <= 5
UNION
SELECT
prod_id,
prod_name,
vend_id,
prod_price
FROM
products
WHERE
vend_id IN (1001, 1002)
ORDER BY
vend_id,
prod_price
这条 UNION 在最后一条 SELECT 语句后使用了 ORDER BY 子句。虽然 ORDER BY 子句似乎只是最后一条 SELECT 语句的组成部分,但实际上MySQL将用它来排序所有 SELECT 语句返回的所有结果
总结
利用 UNION ,可把多条查询的结果作为一条组合查询返回,不管它们的结果中包含还是不包含重复。使用 UNION 可极大地简化复杂的 WHERE 子句,简化从多个表中检索数据的工作。