数据挖掘入门系列教程(二)之分类问题OneR算法
数据挖掘入门系列博客:https://www.cnblogs.com/xiaohuiduan/category/1661541.html
项目地址:GitHub
在上一篇博客中,我们通过分析亲和性来寻找数据集中数据与数据之间的相关关系。这篇博客我们会讨论简单的分类问题。
分类简介
分类问题,顾名思义我么就是去关注类别(也就是目标)这个变量。分类应用的目的是根据已知类别的数据集得到一个分类模型,然后通过这个分类模型去对类别未知的数据进行分类。这里有一个很典型的应用,那就是垃圾邮件过滤器。
在这片博客中,我们使用著名Iris(鸢尾属)植物作为数据集。这个数据集共有150条植物数据,每条数据都给出了四个特征:sepal length、sepal width、petal length、petal width(分别表示萼片和花瓣的长与宽),单位均为cm。一共有三种类别:Iris Setosa(山鸢尾)、Iris Versicolour(变色鸢尾)和Iris Virginica(维吉尼亚鸢尾)
数据集准备
在scikit-learn库中内置了该数据集,我们首先pip安装scikit-learn库
下面的代码表示从sklearn中的数据集中加载iris数据集,并打印数据集中的说明(Description)。
from sklearn.datasets import load_iris
dataset = load_iris()
print(dataset.DESCR)
# data 为特征值
data = dataset.data
# target为分类类别
target = dataset.target截一个数据集中的说明图:

在数据集中,数据的特征值一般是连续值,比如说花瓣的长度可能有无数个值,而当两个值相近时,则表示相似度很大。(这个是由自然界决定的)
与之相反,数据的类别为离散值。因为一种植物就肯定是一种植物,通常使用数字表示类别,但是在这里,数字的相近不能够代表这两个类别相似(因为这个类别是人为定义的)
数据集的特征为连续数据,而类别是离散值,因此我们需要将连续值转成类别值,这个称之为离散化。
而将连续数据进行离散化有个很简单的方法,就是设定一个阈值,高于这个阈值为1,低于这个阈值为0。具体怎么实现我们在下面再说。
OneR算法
OneR(one rule)算法很简单,当时挺有效的。on rule,一条规则,以上面的iris植物为例,就是我们选择四个特种中分类效果最好的一个作为分类依据。这里值得注意的是,选择一个,选择一个,选择一个。
下面是算法的具体步骤,为《Python数据挖掘入门与实践》的原文。
算法首先遍历每个特征的每一个取值,对于每一个特征值,统计它在各个类别中的出现次数,找到它出现次数最多的类别,并统计它在其他类别中的出现次数。
举例来说,假如数据集的某一个特征可以取0或1两个值。数据集共有三个类别。特征值为0的情况下,A类有20个这样的个体,B类有60个,C类也有20个。那么特征值为0的个体最可能属于B类,当然还有40个个体确实是特征值为0,但是它们不属于B类。将特征值为0的个体分到B类的错误率就是40%,因为有40个这样的个体分别属于A类和C类。特征值为1时,计算方法类似,不再赘述;其他各特征值最可能属于的类别及错误率的计算方法也一样。
统计完所有的特征值及其在每个类别的出现次数后,我们再来计算每个特征的错误率。计算方法为把它的各个取值的错误率相加,选取错误率最低的特征作为唯一的分类准则(OneR),用于接下来的分类。
如果大家对OneR算法为什么能够对花卉进行分类感到迷惑的话,可以继续往下看,后面有说明。
在前面的前面我们介绍了特征值的离散化,通过设定一个阈值,我们可以将特征值变成简单的0和1。具体怎么做呢?可以看下面的图片:

假如一共有三个类别,120条数据形成一个(120 × 3的矩阵),然后我们进行压缩行,计算每一列的平均值,然后得到阈值矩阵(1 × 3的矩阵)。这个时候,我们就可以原先的数据进行离散化,变成0和1了。(这一步可以看示意图)
在python的numpy中有一个方法,numpy.mean,里面经常操作的参数为axis,以m*n的矩阵为例:
- axis = None,也就是不加这个参数,则是对m*n 个求平均值,返回一个实数
- axis = 0:压缩行,对各列求均值,返回 1* n 矩阵
- axis =1 :压缩列,对各行求均值,返回 m *1 矩阵
average_num = data.mean(axis = 0)
import numpy as np
data = np.array(data > average_num,dtype = "int")
print(data)通过np.array去构建一个新的数组,当data 大于average_num的时候(为矩阵比较),就为True,否则为False,然后指定类型为int,则True变成了1,False变成了0。结果如下图:

算法实现
既然是去构建一个分类模型,那么我们既需要去构建这个模型,也需要去测试这个模型。so,我们既需要训练集,也需要测试集。根据二八法则,一共150条数据,那么就有120个训练集,30个测试集。
幸运的是sklearn提供了这个划分训练集的库给我们,train_test_split中0.2 代表的是测试集所占的比例(在我上传到GitHub的源代码中,没有设置这个值,默认是0.25),14代表的是随机种子。
from sklearn.model_selection import train_test_split
# 随机获得训练和测试集
def get_train_and_predict_set():
data_train,data_predict,target_train,target_predict = train_test_split(data,target,test_size=0.2, random_state=14)
return data_train,data_predict,target_train,target_predict
data_train,data_predict,target_train,target_predict = get_train_and_predict_set()
这里有一点需要注意,同时也是困扰了我一段时间的问题。那就是在OneR算法中,只凭借1个特征,2种特征值,凭什么能够对3种花卉进行识别??实际上,不能,除非有3个特征值。在《Python数据挖掘入门与实践》,用花卉这个例子举OneR算法不是很恰当,因为当算法实现的时候,只能够识别出两种花卉。如下图:
如果想看一个合适的例子,大家可以去看:https://www.saedsayad.com/oner.htm,在里面最后识别的结果只有yes和no。
具体的训练步骤是怎么样的呢?
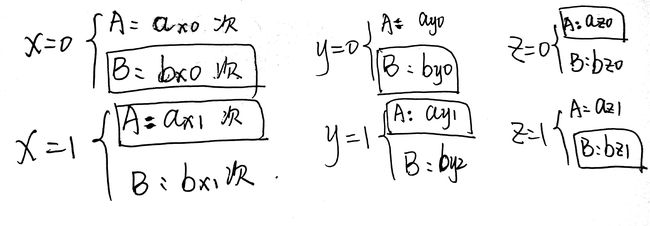
首先我们假设有x,y,z三个特征,每个特征的特征值为0和1,同时有A,B两个类。因此我们可以得到下面的统计。
对于每一个特征值,统计它在各个类别中的出现次数:

既然我们得到了统计,这时候,我们就开始来计算错误率。首先我们找到某个特征值(如 $X = 0$)出现次数最多的类别。在下图中,被框框圈住的部分就是出现次数最多的特征值(如果有三个类别,任然是选择次数最多的类别)。
再然后我们就是计算出每一个特征的错误率了,下面以$X$为例

同理,我们可以得到$Y$,$Z$的错误错误率,然后选择最小的错误率作为分类标准即可。
说了这么多,现在来写代码了。
下面是train_feature函数,目的是得到指定特征,特征值得到错误率最小的类别。也就是上面图中的$b_{x0},a_{x1}$等等。
from collections import defaultdict
from operator import itemgetter
def train_feature(data_train,target_train,index,value):
"""
data_train:训练集特征
target_train:训练集类别
index:特征值的索引
value :特征值
"""
count = defaultdict(int)
for sample,class_name in zip(data_train,target_train):
if(sample[index] ==value):
count[class_name] += 1
# 进行排序
sort_class = sorted(count.items(),key=itemgetter(1),reverse = True)
# 拥有该特征最多的类别
max_class = sort_class[0][0]
max_num = sort_class[0][1]
all_num = 0
for class_name,class_num in sort_class:
all_num += class_num
# print("{}特征,值为{},错误数量为{}".format(index,value,all_num-max_num))
# 错误率
error = 1 - (max_num / all_num)
return max_class,error在train函数中,我们对所有的特征和特征值进行计算,得到最小的特征错误率。
def train():
errors = defaultdict(int)
class_names = defaultdict(list)
# 遍历特征
for i in range(data_train.shape[1]):
# 遍历特征值
for j in range(0,2):
class_name,error = train_feature(data_train,target_train,i,j)
errors[i] += error
class_names[i].append(class_name)
return errors,class_names
errors,class_names = train()
# 进行排序
sort_errors = sorted(errors.items(),key=itemgetter(1))
best_error = sort_errors[0]
# 得到最小错误率对应的特征
best_feature = best_error[0]
# 当特征值取 0 ,1对应的类别。
best_class = class_names[best_feature]
print("最好的特征是{}".format(best_error[0]))
print(best_class)
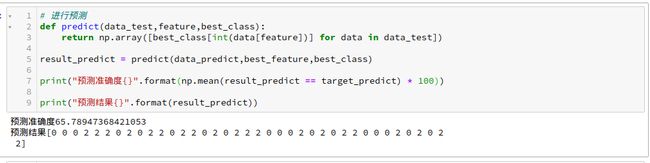
训练完成后,我们就可以进行predict了。predict就是那测试集中数据进行测试,使用自己的模型进行预测,在与正确的作比较得到准确度。看下图predict的流程:

下面是预测代码以及准确度检测代码:
# 进行预测
def predict(data_test,feature,best_class):
return np.array([best_class[int(data[feature])] for data in data_test])
result_predict = predict(data_predict,best_feature,best_class)
print("预测准确度{}".format(np.mean(result_predict == target_predict) * 100))
print("预测结果{}".format(result_predict))结果
在以下条件下:
- 分割测试集和训练集的随机种子为14
- 默认的切割比例
最后的结果如下如所示:
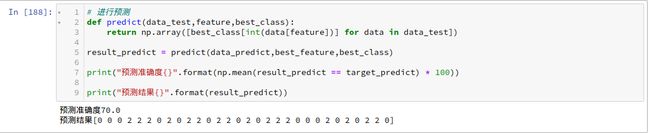
在以下条件下:
- 切换比例为2:8
- 随机种子为14
结果如下图所示
OneR算法很简单,但是在某些情况下却很有效,没有完美的算法,只有最适用的算法。
结尾
GitHub地址:GitHub
参考书籍:Python数据挖掘入门与实践
感谢蒋少华老师为我解惑。