时间:2020年3月22日 22:08,
距离 “ 武汉发布 ”官方发布《湖北省内外人员返汉、省内人员离汉政策来了》 30分钟,
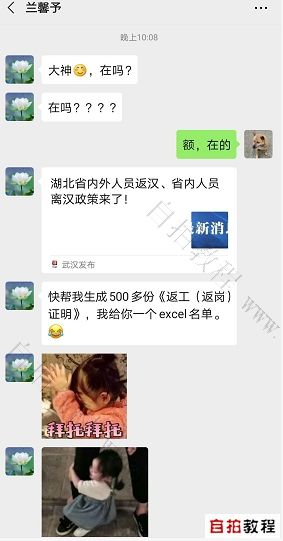
大晚上的,公司行政小姐姐骚扰我。。。
我能怎么? 实在不好拒绝。。。。。。
准备阶段
- 需要1张excel表格,记录了每个员工的必要信息, openpyxl模块可以读取excel
- 需要1个《复工证明_模板》.docx, 可以用python-docx来读写word
- 复工模板是一个模板,里边能动态替换的地方是:ToReplace1, ToReplace2
- 复工模板word里边标题和公司落款可以自定义化,可自行DIY。

Python代码
import os
import openpyxl
from docx import Document
# 这个函数相对比较复杂,尽量不要修改。
def docx_replace(doc, key_word, new_word): #keyword是需要查找的关键字,new_word是替换后的新的文字
paragraphs = list(doc.paragraphs)
for p in paragraphs:
if key_word in p.text:
inline = p.runs # 切成片段,但是这个片段实在是太短了。
started = False
key_index = 0
found_runs = list() # 记录在哪些index上匹配上了关键字
found_all = False
replace_done = False
for i in range(len(inline)):
# 直接在某个片段里找到了,则直接替换。
if key_word in inline[i].text and not started:
found_runs.append((i, inline[i].text.find(key_word), len(key_word)))
text = inline[i].text.replace(key_word, str(new_word))
inline[i].text = text # 替换
replace_done = True
found_all = True
break
# 未找到该片段,则继续找
if key_word[key_index] not in inline[i].text and not started:
continue
# 在第一个片段里匹配到了部分。
if key_word[key_index] in inline[i].text and inline[i].text[-1] in key_word and not started:
start_index = inline[i].text.find(key_word[key_index])
check_length = len(inline[i].text)
for text_index in range(start_index, check_length):
if inline[i].text[text_index] != key_word[key_index]:
break
if key_index == 0:
started = True
chars_found = check_length - start_index
key_index += chars_found
found_runs.append((i, start_index, chars_found))
if key_index != len(key_word):
continue
else:
found_all = True
break
# 在其他的片段里找到了
if key_word[key_index] in inline[i].text and started and not found_all:
chars_found = 0
check_length = len(inline[i].text)
for text_index in range(0, check_length):
if inline[i].text[text_index] == key_word[key_index]:
key_index += 1
chars_found += 1
else:
break
found_runs.append((i, 0, chars_found))
if key_index == len(key_word):
found_all = True
break
if found_all and not replace_done:
for i, item in enumerate(found_runs):
index, start, length = [t for t in item]
if i == 0:
text = inline[index].text.replace(inline[index].text[start:start + length], str(new_word))
inline[index].text = text # 替换
else:
text = inline[index].text.replace(inline[index].text[start:start + length], '')
inline[index].text = text # 替换
# 以下是可以修改的,比如增加Excel的列,或者增加word里边的“ReplaceX”
wb = openpyxl.load_workbook('员工名单信息.xlsx') # 读取excel里边的内容
table = wb.active
rows = table.max_row
for r in range(2, rows + 1): #跟excel的第一行标题行无关,从第二行文字内容开始做替换工作
value1 = table.cell(row=r, column=1).value #获取文字
value2 = table.cell(row=r, column=2).value
document = Document('复工证明_模板.docx') # 打开文件demo.docx
docx_replace(document, "ToReplace1", value1) # 替换1
docx_replace(document, "ToReplace2", value2) # 替换2
document.save('复工证明_%s.docx' % value1) # 保存在当前目录下面
print('复工证明_%s.docx自动生成完毕!' % value1)
os.system("pause")
程序打包成.exe
考虑到行政小姐姐,肯定不会用Python,也不具备Python运行环境,
帮她打包成.exe吧。。。 用pyinstaller 打包如下:
有点变态的大,没办法啊,py2exe打包出了点问题,不然不会用pyinstaller打包...
下载地址:
跳转至自拍教程官网下载
运行方式与效果:
可编辑《员工名单信息.xlsx》里的姓名,身份证号码
可编辑《复工证明_模板.docx》里的标题,正文,还有公司落款,但是要保留ToReplace1, Replace2, 这两处是自动替换的地方。
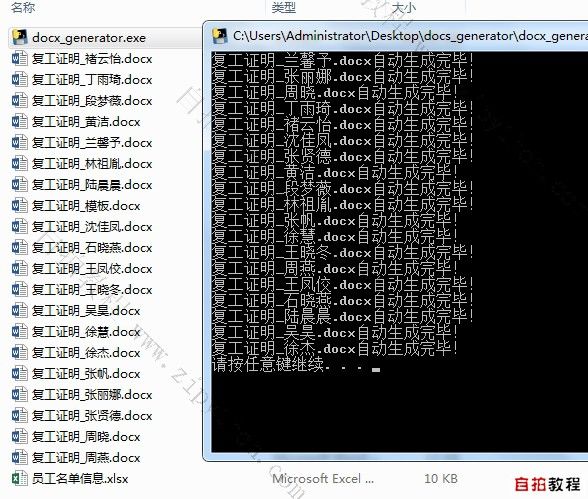
双击运行“docx_generator.exe"即可。
最终生成的返工(返岗)证明效果如下:
更多更好的原创文章,请访问官方网站:www.zipython.com
自拍教程(自动化测试Python教程,武散人编著)
原文链接:https://www.zipython.com/#/detail?id=ac62b9061e5f4d4582839f753da71b82
也可关注“武散人”微信订阅号,随时接受文章推送。