实际上,基于比较和交换的排序算法,它们的时间复杂度的下限就是O(nlog2n)。冒泡排序,插入排序等自不必多说,时间复杂度是O(n2),即使强如快速排序,堆排序等也只是达到了O(nlog2n)的复杂度。那么那些传说中可以突破O(nlog2n)下限,达到线性时间复杂度O(n)的排序算法到底是什么样的呢,接下来让我们一探究竟。
桶排序
基本思想
一句话概括就是,将待排序列中的每一个元素通过设定好的映射函数分配到有限数量的桶中,然后再对每个桶中的元素排序。
基本步骤如下:
- 准备有限数量的空桶
- 遍历待排序列,将每个元素通过映射函数分配到对应的桶中
- 对每个不是空的桶进行排序
- 从每个不是空的桶中再依次把元素放回到原来的序列中
桶排序是利用函数的映射完成了元素的划分,省略了比较交换的步骤,然后再对桶中的少量数据进行排序,这里的排序可以根据实际需求选择任意的排序算法,比如使用快速排序。需要注意的是映射函数的选择必须保证每个桶是有序的,即一个桶中的所有元素必须大于或小于另一个桶中的所有元素。这样才能在依次从每个桶中将元素放回到原始序列中时,保证元素的有序性。
复杂度与稳定性与优缺点
-
空间复杂度:O(m + n),m表示桶的数量,n表示需要长度为n的辅助空间
-
时间复杂度:O(n)
桶排序的耗时主要是两个部分:- 将待排序列的所有元素映射到桶中,时间复杂度O(n)
- 对每个桶内元素排序,因为是基于比较的算法,平均时间复杂度只能达到O(Nilog2Ni),Ni表示每个桶内的元素个数
对于N个元素的待排序列,M个桶,平均每个桶N/M个元素,其桶排序平均时间复杂度可以表示如下:
O(n) + O(M * (N/M)log2(N/M)),当M == N时,复杂度为O(n) -
最好情况:O(n),当待排序列的元素是被均匀分配到桶中时,是线性时间O(n)。各个桶内的数据越少,排序所用的时间也越少,但相应的空间消耗就会增大。当每个桶内只有一个元素时,即M == N,是桶排序的最好情况,真正的达到O(n)
-
最坏情况:所有元素都被分配到同一个桶中,桶排序退化为普通排序。
-
稳定性:稳定
-
优点:稳定,突破了基于比较排序的下限
-
缺点:需要额外的辅助空间,需要好的映射函数
算法实现
public void BucketSort(int[] array){
int max = array[0], min = array[0];
for(int i = 1; i < array.Length; i ++){
if(array[i] > max) max = array[i];
if(array[i] < min) min = array[i];
}
List[] buckets = new List[Fun(max, min, array.Length) + 1];
for(int i = 0; i < buckets.Length; i ++){
buckets[i] = new List();
}
for(int i = 0; i < array.Length; i ++){
buckets[Fun(array[i], min, array.Length)].Add(array[i]);
}
int index = 0;
for(int i = 0; i < buckets.Length; i ++){
// 桶内的排序借助了Sort方法,也可以使用其他排序方法
buckets[i].Sort();
foreach(int item in buckets[i]){
array[index ++] = item;
}
}
}
// 映射函数,可以根据实际需求选择不同的映射函数
public int Fun(int value, int minValue, int length){
return (value - minValue) / length;
}
【算法解读】
算法首先确定映射函数Fun,函数的返回值就是元素对应桶的下标。然后找到待排序列中的最大值与最小值,并利用最大最小值确定桶排序需要的桶数量。遍历待排序列的所有元素并通过映射函数Fun将它们分配到对应下标的桶中。再依次对每个桶内的所有元素进行排序,这里的使用的是C#提供的Sort方法(也可以选择不同的排序方法)。当一个桶内的元素排序完毕后再将其放回到原始序列中。
【举个栗子】
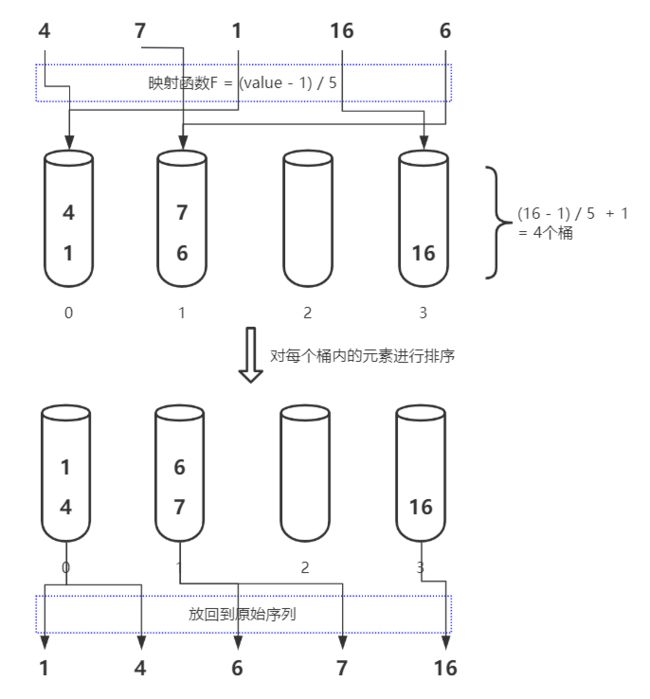
对于待排序列4, 7, 1, 16, 6可以使用下图表示其桶排序的过程:
计数排序
基本思想
计数排序可以认为是桶排序的一种特殊实现,如果理解了桶排序的话,计数排序就相对很简单了。
计数排序要求待排序列的所有元素都是范围都在[0, max]之间的正整数(当然经过变形也可以是负数,比如通过加上某个值,使所有元素都变为正数)
基本步骤如下:
- 得到待排序列中的最大值,构建(最大值 + 1)的计数数组C,可以认为是(最大值 + 1)个桶,只是桶中存放的不再是元素,而是每个元素出现的次数
- 遍历待排序列,在计数数组中统计每个元素出现的次数。出现一个元素i,则以该元素值为索引的位置上计数加1,即C[i] ++
- 遍历计数数组,若C[i] > 0,则表示存在有值为i的元素,依次将存在的元素i赋值到原始序列中
复杂度与稳定性与优缺点
- 空间复杂度:O(k)
这里说明一下,对于计数排序的空间复杂度,很多网上的文章都标注的是O(n + k),其实这与计数排序具体的实现算法有关,有的算法是将计数排序得到的最终序列添加到了一个辅助序列中,而没有修改原始序列,所以空间复杂度是O(n + k),而本文的实现算法没有使用辅助序列,直接修改的原始序列,所以空间复杂度是O(k)。而有些文章不管提供的实现算法如何就直接标注O(n + k)的空间复杂度,显然很容易误导读者。 - 时间复杂度:O(n + k),常数k表示待排序列中最大元素的值
- 最好情况:O(n + k)
- 最坏情况:O(n + k)
- 稳定性:稳定
- 优点:稳定,适用于最大值不是很大的整数序列,在k值较小时突破了基于比较的排序的算法下限
- 缺点:存在前提条件,k值较大时,需要大量额外空间
算法实现
public void CountSort(int[] array){
int max = array[0];
for(int i = 0; i < array.Length; i ++){
if(array[i] > max) max = array[i];
}
int[] count = new int[max + 1];
for(int i = 0; i < array.Length; i ++){
count[array[i]] ++;
}
int index = 0;
for(int i = 0; i < count.Length; i ++){
while(count[i] -- > 0){
array[index ++] = i;
}
}
}
【算法解读】
可以看到算法首先获得待排序列元素中的最大值,然后构建(最大值+1)长度的计数数组。遍历待排序列的每个元素,并在计数数组中利用元素值为下标记录元素的出现次数。然后遍历计数数组,若对应下标的位置上值大于0(等于几就表示有几个元素),则表示存在有元素且其值为下标的大小。将该元素添加到原始序列中。由于下标是从小到大的,所以对应得到的序列也是从小到大排列的。
【举个栗子】
对于待排序列1, 2, 3, 4, 5可以使用下图表示其计数排序的过程:

基数排序
基本思想
基数排序也是不进行比较,而是通过“分配”和“收集”两个过程来实现排序的。
首先设立r个队列,对列编号分别为0~r-1,r为待排序列中元素的基数(例如10进制数,则r=10),然后按照下面的规则对元素进行分配收集:
- 先按最低有效位的值,把n个元素分配到上述的r个队列中,然后从小到大将个队列中的元素依次收集起来
- 再按次低有效位的值把刚收集起来的元素分配到r个队列中,然后再进行收集
- 重复地进行上述分配和收集,直到最高有效位。(也就是说,如果位数为d,则需要重复进行d次,d由所有元素中最大的一个元素的位数计量,比如如果最大数是963,则d = 3)
为什么这样就可以完成排序呢?
以从小到大排序为例,首先当按照最低有效位完成分配和收集后,此时得到的序列,是根据元素最低有效位的值从小到大排列的。
当按照次低有效位进行第二次分配和收集后,得到的序列,是先根据元素的次低有效位的值从小到大排列,然后再根据最低有效位的值从小到大排列。
以此类推,当按照最高有效位进行最后一次分配和收集后,得到的序列,是先根据元素的最高有效位的值从小到大排列,再根据次高有效位排列,。。。,再根据次低有效位,再根据最低有效位。自然就完成了每个元素的从小到大排列。
复杂度与稳定性与优缺点
- 空间复杂度:O(n + r),r表示元素的基数,比如十进制元素,则 r = 10
- 时间复杂度:O(d(n + r))
- 最好情况:O(d(n + r))
- 最坏情况:O(d(n + r))
- 稳定性:稳定
- 优点:稳定,时间复杂度可以突破基于比较的排序法的下限
- 缺点:需要额外的辅助空间
算法实现
public void RadixSort(int[] array){
int max = GetMaxValue(array);
int[] buckets = new int[10];
int[] buffer = new int[array.Length];
for(int i = 1; max / i > 0; i = i * 10){
// 统计每个桶中的元素个数
for(int j = 0; j < array.Length; j ++){
buckets[array[j] / i % 10] ++;
}
// 使每个桶记录的数表示在buffer数组中的位置
for(int j = 1; j < buckets.Length; j ++){
buckets[j] += buckets[j - 1];
}
// 收集,将桶中的数据收集到buffer数组中
for(int j = array.Length - 1; j >= 0; j --){
buffer[-- buckets[array[j] / i % 10]] = array[j];
}
for(int j = 0; j < array.Length; j ++){
array[j] = buffer[j];
}
// 清空桶
for(int j = 0; j < buckets.Length; j ++){
buckets[j] = 0;
}
}
}
// 获得待排序列中的最大元素
public int GetMaxValue(int[] array){
int max = array[0];
for(int i = 1; i < array.Length; i ++){
if(array[i] > max){
max = array[i];
}
}
return max;
}
【算法解读】
算法针对的是十进制数,所以r=10
首先获取到待排序列中的最大元素,然后根据最大元素的位数d进行d趟分配与收集
每一趟的分配与收集过程如下:
根据给定的位数,计算待排序列的每个元素在该位上的值,如果某个元素没有该位,则用0表示。然后使用长度为10的桶数组记录它们出现的次数(这里并没有直接使用桶记录对应的元素)。再遍历一遍桶数组buckets[j] += buckets[j - 1];,使每个桶记录的数值,表示的就是在指定位数上值等于桶索引的元素在辅助数组buffer中的位置。
然后进行收集工作,根据桶数组中记录的位置信息,依次将对应的元素收集到buffer数组中。最后清空桶,为下一次分配收集做准备。
【举个栗子】
对于待排序列9, 40, 123, 56, 7,17可以使用下图表示其基数排序的过程:

更多
上面算法的源码都放在了GitHub上,感兴趣的同学可以点击这里查看
更多算法的总结与代码实现(不仅仅是排序算法),可以查看GitHub仓库Algorithm