Java集合类是非常重要的知识点,其中HashMap、HashTable、ConcurrentHashMap最为重要。本文主要对HashMap进行详细的介绍以及总结一些面试中经常问到的问题。
HashMap的内部存储结构
Java中数据存储方式最底层的两种结构,一种是数组,另一种就是链表。
数组的特点:连续空间,寻址迅速,但是在删除或者添加元素的时候需要有较大幅度的移动,所以查询速度快,增删较慢。
链表的特点:由于空间不连续,寻址困难,增删元素只需修改指针,所以查询慢、增删快。
有没有一种数据结构来综合一下数组和链表,以便发挥他们各自的优势?答案是肯定的!就是:哈希表。哈希表具有较快(常量级)的查询速度,及相对较快的增删速度,所以很适合在海量数据的环境中使用。
HashMap的实现主要用到了哈希表的链地址法。即使用数组+链表的方式实现。
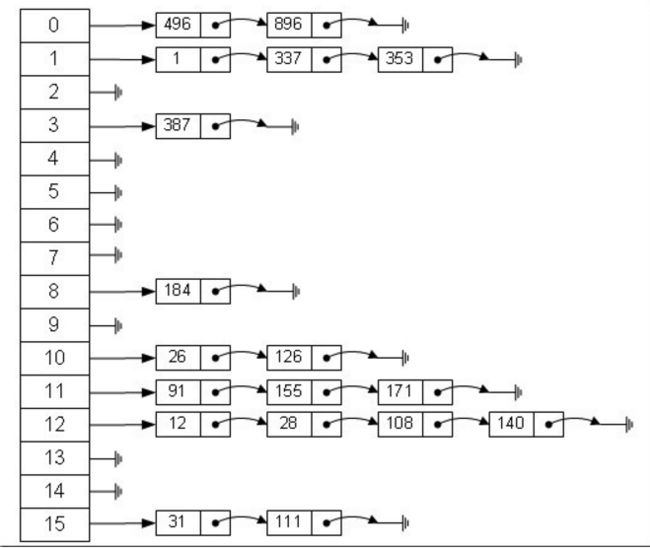
上图是一个长度为16的数组中,每个元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash(key)%len获得,也就是元素的key的哈希值对数组长度取模得到。比如上述哈希表中,12%16=12 , 28%16=12, 108%16=12, 140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。
它的内部其实是用一个Entity数组来实现的,属性有key、value、next。
HashMap重要方法详细分析
- 初始化
一般使用new HashMap()方法初始化,我们先来看一下无参构造方法的源代码
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
常量
static final int DEFAULT_INITIAL_CAPACITY = 16;
初始容量:16
static final int MAXIMUM_CAPACITY = 1 << 30;
最大容量:2的30次方 => 1073741824
static final float DEFAULT_LOAD_FACTOR = 0.75f;
负载因子:75%
上面还出现了一些变量,介绍一下这些重要变量
| 变量 | 术语 | 说明 |
|---|---|---|
| loadFactor | 负载因子 | HashMap大小负载因子,默认为75% |
| threshold | 临界值 | HashMap大小达到临界值,需要重新分配大小 |
| Entry | 实体 | HashMap存储对象的实际实体,由Key,value,hash,next组成 |
| *modCount | 统一修改 | HashMap被修改或者删除的次数总数 |
HashMap中除了无参构造方法,还有带参数的构造方法,我们也来看一下它的源代码
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
// Find a power of 2 >= initialCapacity
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
this.loadFactor = loadFactor;
threshold = (int)(capacity * loadFactor);
table = new Entry[capacity];
init();
}
使用这个带参数的构造方法,我们就能指定初始时的table容量以及负载因子了。
- put(Object key,Object value)方法
作用是存储一个键-值对
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with key, or
* null if there was no mapping for key.
* (A null return can also indicate that the map
* previously associated null with key.)
*/
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
处理步骤如下:
(1)判断key是否为null,若为null,调用putForNullKey(value)处理。这个方法代码如下:
/**
* Offloaded version of put for null keys
*/
private V putForNullKey(V value) {
for (Entry e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(0, null, value, 0);
return null;
}
从代码可以看出,如果key为null的值,默认就存储到table[0]开头的链表了。然后遍历table[0]的链表的每个节点Entry,如果发现其中存在节点Entry的key为null,就替换新的value,然后返回旧的value,如果没发现key等于null的节点Entry,就增加新的节点。
(2)先计算key的hashcode,在使用计算的结果二次hash,使用indexFor(hash, table.length)方法找到Entry数组的索引i的位置。
(3)接着遍历以table[i]为头结点的链表,如果发现已经存在节点的hash、key值与条件相同时,将该节点的value值替换为新的value值,然后返回旧的value值。
(4)如果未找到hash、key值均相同的节点,则调用addEntry方法增加新的节点(头插法)。代码如下:
void addEntry(int hash, K key, V value, int bucketIndex) {
Entry e = table[bucketIndex];
table[bucketIndex] = new Entry(hash, key, value, e);
if (size++ >= threshold)
resize(2 * table.length);
}
- get(Object key)方法
作用是根据键来获取值
public V get(Object key) {
if (key == null)
return getForNullKey();
int hash = hash(key.hashCode());
for (Entry e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))//-------------------1----------------
return e.value;
}
return null;
}
处理步骤如下:
(1)当key为null时,调用getForNullKey(),它的源码如下:
private V getForNullKey() {
for (Entry e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
返回table[0]开头的链表的键为null的节点的值
(2)当键不为null时,依然计算hash值,然后找到具体在哪个table[indexFor(hash, table.length)]节点开头的链表中,遍历此链表查找是否存在搜索条件中的key值,返回其value。若没有符合条件的key值,返回null。
- 其他方法
HashMap其他方法,可以通过查看jdk源代码中的java.util.HashMap.java了解,本文主要介绍最重要的几个方法。
具体查看方法:
解压jdk目录下的src.zip文件
然后就可以查看大多数的源代码了
HashMap常考问题总结
最后补充一些面试时候常问到的一些问题总结。
(1)HashMap和HashTable的区别?
- HashMap是非线程安全的,HashTable是线程安全的
- HashMap的键和值都允许有null值存在,而HashTable则不行
- 因为线程安全的问题,HashMap效率比HashTable的要高
- 哈希值的使用不同,HashMap要根据hashCode二次计算得到hash值,而HashTable直接使用对象的hashCode
- 继承的父类不同,HashMap继承自AbstractMap
(2)HashMap中的键可以是任何对象或数据类型吗?
- 可以为null,但是不能为可变对象。如果为可变对象的话,对象中的属性改变则对象的hashCode也进行了相应的改变,导致下次无法查找到已存在Map中的数据。
- 如果可变对象在HashMap中被当做键,那么就要小心在它的属性改变时,不要改变它的hashCode。只要保证成员变量的改变不会相应改变其hashCode即可。
(3)HashTable如何实现线程安全?
实现原理是在对应的方法上添加了synchronized关键字进行修饰,由于在执行此方法时需要获得对象锁,因此执行起来比较慢。如果想实现线程安全的HashMap的话,推荐使用ConcurrentHashMap。
参考资料
[1] HashMap深度分析
http://www.jianshu.com/p/8b372f3a195d
[2] [Java之美[从菜鸟到高手演变]之HashMap、HashTable] http://blog.csdn.net/zhangerqing/article/details/8193118