注:Condolination array 的 slot 部分理解有问题
Abstract
4个缺陷限制了 logging-related 的数据库系统的可扩展性:
- 大量小 I/O 请求可能过载 disk
- 事务在等待 log flush 期间持有锁
- 外延的而上下文切换,带来的线程执行 log I/O 给操作系统调度器带来的压力
- 事务顺序访问内从中的 log 数据结构带来的竞争
本文介绍了这些问题,并用一种全面的、可扩展的 log 方式来解决这些问题,展示出了可观的性能。
Introduction
以前的 DBMS 的硬件环境是:单核、高 I/O 延迟,现在这一情况已经改变。新的 DBMS 尽可能利用并发性来交织大量事务的执行。虽然理论上硬件提升后,并发性也就更高,但是 DBMS 内部的很多瓶颈限制了这一提升。这些瓶颈如 Abstract 里所列举的,目前的研究都只是分段或部分地解决这些问题,没有提出一个充分适应当前多核环境下的,可扩展的 log manager。
Write-ahead Logging and Log Bottlenecks
几乎所有数据库系统都使用中心化的 write-ahead logging (WAL) 技术。WAL 技术的目的和好处这里就不另外说明了,文中给出了四种存在的 delay,如下所示。
- I/O-related delays
这个好理解,就是每次日志要写到非易失性存储上,一般是磁盘,I/O 有延迟。 - Log-induced lock contetention
写操作需要持有日志的写锁,在 flush 期间一直持有写锁,会导致其它线程无法并发。 - Excessive context switching
CPU 可能将正在执行事务的线程给切换出去了,因为时间片到了。 - Log buffer contention
中心化的设计导致只有一个中央日志,大量线程同时尝试往日志里写的时候,因为日志是先写到缓冲区的,这样就算没有逻辑锁,也会产生“竞争”。
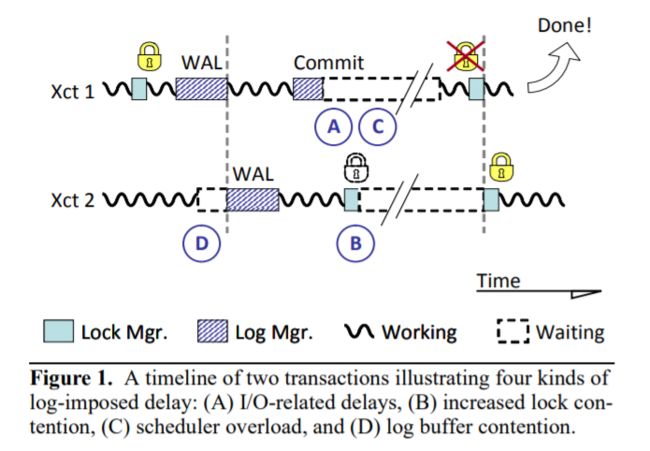
async logging 异步日志可以有效解决上述问题的前三个,并且很多数据库系统,如 Oracle 和 PostgreSQL 都提供,但是可能会产生数据丢失的问题。这里不展开阐述。目前为止,还没有方法全部解决上述四个问题。
A Holistic Approach to Scalable Logging
- Early Lock Release (ELR)
ELR 用来解决写锁竞争。ELR 在研究工作中多次被提到,但是目前没有实现到任何数据库引擎中。(注:这个 ELR 可能存在设计问题) - Flush Pipelining
用来解决上写问切换的问题。 - Log Buffer Redesign
重新设计了 log buffer, 来实现线程数量、日志大小与日志竞争之间无关。但可能导致内存带宽成为新的瓶颈。
Related Work
ARIES (Algorithms for Recovery and Isolation Exploiting Semantics) 技术在 DBMS 中广泛被应用,来实现并发控制、事务回滚和错误恢复。ARIES 技术下的 log 被实现为一个所有事务共享的全局数据结构,从而造成了性能瓶颈。
固态硬盘能极大地减少 I/O 带来的开销,但是因为同步 flush 操作还是会造成线程阻塞,从而触发线程调度,还是不能消除所有开销。
Log 组提交策略将多个 flush 操作合并为单个 I/O 操作,从而减少了上面提到的开销。
TODO 没看懂 Unfortunately, group commit does not eliminate unwanted context switches because transactions merely block pending notification from the log rather than blocking on I/O requests directly.
异步提交继承了组提交的思想,但还包括异步。异步就可能造成数据丢失。
一个研究结论:事务可以安全地在 flush 日志到磁盘上之前就释放锁。ELR 基于这个结论做了实现。
内存数据库面临的挑战就是,log I/O 相比之下成为很大的性能瓶颈,因为这是唯一需要访问磁盘的操作,体现在磁盘 I/O 本身的延迟和对 log buffer 的竞争。
Moving Log I/O Latency off the Critical Path
Early Lock Release
事务的锁可以在日志提交到磁盘之前被释放,只要它不会在持久化之前返回给客户端任何结果。但是如果有预提交事务要读这个结果,那么就存在一个依赖关系,DBMS 保证在它所依赖的事务被完成之前,即写到磁盘上之前,不会返回任何结果。顺序日志实现天生保证了这一特点,因为日志只能顺序写。
ELR 系统必须包含两个条件来保证可恢复性:
- 每一个事务的日志必须在它所依赖的事务完成预提交阶段后,才能提交。
这里涉及到一个数据库事务的三阶段提交的概念。详细可以查阅博客。与本文相关的,pre-commit 后,所有操作已经计入日志,而 do-commit 只是根据日志去写入磁盘。所以只要 pre-commit 完成,实际上就可以释放日志的写锁了。
- 当一个 pre-commit 事务被 abort 掉后,依赖该事务的所有事务也要被 abort。这个很好理解,需要注意的是实现上。
一篇博客中 关于 WAL 的工作流程的解释。
1.在SQL Server的缓冲区的日志中写入”Begin Tran”记录
2.在SQL Server的缓冲区的日志页写入要修改的信息
3.在SQL Server的缓冲区将要修改的数据写入数据页
4.在SQL Server的缓冲区的日志中写入”Commit”记录
5.将缓冲区的日志写入日志文件
6.发送确认信息到客户端(SMSS,ODBC等)
7.将缓冲区内的页写入到磁盘
一篇博客中 关于事务提交的工作流程解释。
0.begin transaction;
1.search & lock tuple for update;
2.update tuple & generate log;
3.write commit log;
4.flush logs;
5.unlock tuples;
6.commit & notify user;
容易发现,事务在写出并且持久化日志的时候会带来 IO,而 IO 通常而言比较耗时。如果事务中此前的操作都是内存操作的话(在内存数据库或 LSM 结构的系统中更明显),这些 IO 的相对耗时就会显得更大。IO 虽然可以做成异步的,但是在 IO 结束之前锁都仍然会被持有,从而会阻塞其他的并发事务。如果可以把第 5 步释放锁的操作提前,放到第 4 步刷出日志之前,则可以让并发操作同一记录(试图获得锁)的事务 t2 提前开始执行,从而可以增加系统的吞吐量。显然,第 6 步的 commit 操作不能提前,仍然必须等到日志持久化完成之后才能通知用户提交成功,因此用户事务的响应时间不会缩短。
现有 DBMS 没有采用 ELR 的,作者文中认为是因为异步更高效,但根据前面的博客,MySQL 是做过尝试的,但失败了,同时也有脏读的问题。
Evaluation of ELR
锁竞争越激烈,ELR 带来的性能提升越大;I/O 耗时越长(持有锁的时间越长),ELR 带来的性能提升越大。
Decoupling OS Scheduling from Log Flush Operations
log flush 造成的延迟来自两个方面:
- I/O 造成的等待
- I/O 导致阻塞一个线程和解阻塞一个线程带来的上下文切换
I/O 的时候 CPU 可以做其它的工作,但是调度的时候,CPU 是被占用了几毫秒的时间的。
调度和上下文切换越来越重要的原因:
- 固态硬盘的速度越来越快,调度和上下文切换带来的耗时占比越来越大。
- 指数增长的核数让 OS 调度线程的时候考虑的更多,更复杂。
测试发现,随着 client 线程的增加,系统耗时线性增长,所以单独使用组提交并不能完全解决扩展性的问题,异步提交很快但是可能不安全。
Flush Pipelining
Flush Pipelining 的思想主要是将线程在事务提交后,与等待 flush 操作完成进行分离。分为以下步骤:
- 线程异步提交事务后,不等待 flush 操作完成,但是也不是直接就返回了,而是退出当前事务,将状态写入 log 里,然后继续执行其它事务。
- 一个守护线程按时、按次、按大小等策略自动触发 flush。
- flush 完成后,守护线程通知执行线程 newly-hardened transactions,which eventually reattach to each transaction, finish the commit process and return results to the client.
这里具体的事务操作没看懂,猜测是执行线程重新执行上次的事务,完成事务提交后面要做的工作,然后返回值给 caller 函数。hardened 的意思貌似是指日志写到磁盘上,而不是缓冲区中。
产生日志记录后 abort 掉的事务也必须 hardened 才能回滚。
TODO 有点没看懂
Evaluation of Flush Pipelining
略
Scalable Log Buffer Design
大部分数据库引擎使用 ARIES 的一个变体,给每个 log 记录一个唯一的 Log Sequential Number (LSN)。LSN 编码了记录的磁盘位置,同时作为数据页写到磁盘的时间戳,还作为指向内存和磁盘中的 log 记录的指针。LSN 也可以用来做 log buffer 中的地址,这样一来生成一个 LSN 的同时也就预留了 buffer 中的空间。
为了保证数据库的一致性,ARIES 对 LSN 有严格排序要求。技术上并不需要全局排序来保证正确性,正确的偏序又可能太复杂且互相依赖,不值得作为性能优化的备选项。
插入一条记录到 log buffer 中包括如下三个阶段:
- LSN generation and log buffer acquire.
线程必须先申请打算写 log 进去的空间。虽然 LSN 是个线性操作,但是很快且可预测,除非一些异常情况,比如 buffer wraparound 和 buffer 满。 - Log record insertion.
线程把 log 写进之前申请的空间。 - Log buffer release.
事务释放 buffer,从而允许 log manager 把 log 中的记录写到磁盘上。
最简单的方法,log insert 之前获取到 log 的锁,这个锁只有一个,然后做完 2,3操作后,释放 buffer 的同时释放这个锁。但很明显,这样做就把 insert log 线性化了,并发高的时候就成了性能瓶颈;同时,如果 log record 大小不同,那么这部分工作的性能损耗就不可预测。
解决这个问题的思路:使得 insert log 操作和并发数、log record 的大小无关。
Consolidating Buffer Allocation
log record 由一个标准的 header 和任意数据载荷组成。log buffer 分配申请由两个连续的请求组成,内容也是一样的形式。利用这一点,通过类似组提交的思想,把多个 buffer 分配申请进行合并,从而扩大吞吐量。
TODO 看不懂。扩展了 elimination-based backoff 的思想,同时利用 elimination trees 和 backoff。。。
TODO 看不懂。When elimination is successful threads satisfy their requests without returning to the shared resource at all, making the backoff very effective. For example, stacks are amenable to elimination because push and pop requests which encounter each other while backing off can cancel each other directly via the elimination array
and leave.
遇到 log insert 竞争的线程,回退到一个叫 consolidation array 的地方,合并它们的写操作,再尝试对 log buffer 进行写操作。这里叫 consolidation 而不是 elimination 是因为,线程在合并请求后,还要进行协调:最后一个执行 insert 的线程得释放自己组的 log buffer。
这样一来,log buffer 支持的最大并发数就变成了数组的容量,而不是系统内的线程数。
这里的 allocation 首先揭示了一个思想,后面也用到了 insert 上:一个线程尝试去锁 buffer 的时候,如果没有锁,这个线程就拿到锁,执行自己的操作,再释放锁;如果这个时候锁被占用着的,那么这个线程就回退到一个 consolidation array,在里面继续尝试拿锁。不同的是,这个时候如果再来一个请求,这个请求也进入 consolidation array,然后两个整合、协调一下,计算一共要分配多大的空间,谁去申请这个空间,可能是根据自己写的 record 大小来决定谁释放这个空间(不过我感觉这种简单的机制不靠谱,因为万一来个调度,record 小的可能后做完,所以并不靠谱)。做完之后,继续尝试获取锁。这个时候再来个请求的话,如上。
但是作者并没有讲一个 consolidation array 内是怎么并发执行对 buffer 的写操作的,看图的话应该是并发执行的,但是 buffer 的执行应该是线性的。感觉图画的有问题。个人理解是将多个写操作合并成一个写操作了。
总之,只有第一个线程需要请求分配 buffer ,只有最后一个线程需要等待释放 buffer。但是也存在一个问题,如果两组线程先后尝试写 log,第一组的第一个线程锁了 buffer 后,写很大一个 record,这时候第二组还是得等。并发性只是被保证在了同一组内。
Decoupling Buffer Fill
因为 buffer fill 操作不是必须顺序的 (records 不会重叠),并且有不同的耗时,可以考虑把这些操作从关键路径上移出来。只要线程以 LSN 顺序释放它们写入的区域,线程可以安全地以任意顺序写这些区域。
作者修改了原来的算法,线程一旦分配到 buffer 之后就释放锁。这样做了之后,就要解决 buffer 释放的问题。Buffer 释放的操作必须以 LSN 顺序来避免在 record 之间产生 gap;Recovery 必须在遇到第一个 gap 的时候就停下来,在一个 crash 中,gap 之后的操作都会丢失掉。虽然无锁,但是每一个线程都必须等它前面的 region 被释放之后才能释放自己的 region。
这里的思想有点类似于乐观锁。所有线程都先乐观地写,只有在需要同步的时候才同步,这里“同步”即是前面的 region 必须先写完。为什么要保证这个顺序要求,可能是为了 crash failover 的考虑:如果用一个类似 CountDownLatch 的实现,一旦 crash,因为不知道哪些写完了,所以这个 CountDownLatch 上对应的操作都得被作废了。如果保证以 LSN 顺序来写,哪里 crash 掉是知道的。
这样一来,就解决了第二组遇上一个写大 record 的另一组线程,必须一直等别人写完才能自己开始写的情况。并发性得到了提高。
但是因为释放操作有依赖关系,整体上还是会被写大 log 的拖累,可能会导致大量线程等着前序线程释放。(这谁顶得住啊.jpg)
Putting it all Together: Hybrid Log Buffer
前面提到的包括两个工作:
- 一个基于整合队列的方法来减少进入临界区的线程数
- 一种分离策略使得线程能在临界区外写 log buffer
组合起来,就能使得整体性能相对来说,不对并发数和 log record 大小敏感。
下面解释一下这个图:
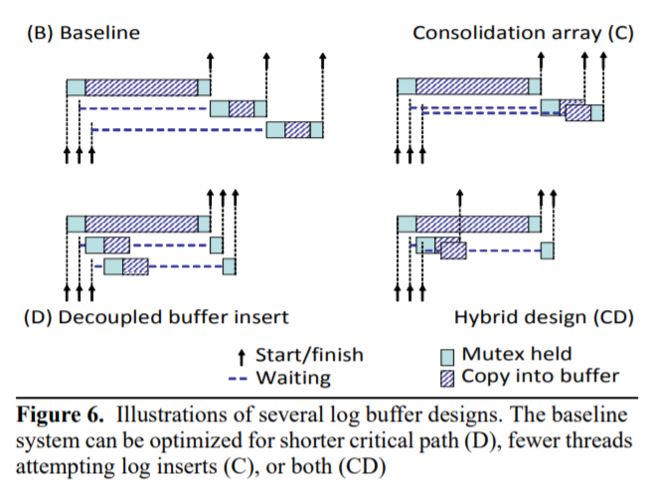 几种优化措施的原理和对耗时的影响
几种优化措施的原理和对耗时的影响
- (B) 是基准对照,箭头入口表明操作被提交的时间,可见短时间内来了三个操作,第一个操作拿到锁后,往 buffer 里写,然后释放;然后第二、第三个操作顺序执行。
- (C) 是采用了整合队列后的示例。这里第一个操作是第一组线程,因为这里只有它一个线程,申请分配 log space 是它,申请完了后写 record 也是它,释放锁的还是它。
第二组操作等到第一组操作释放锁后,第二组操作所有的线程被组合成一个整合队列,由其中第一个线程去申请锁,申请 log space,然后队列里的线程以不知道的某种并发方式都开始往 buffer 里写 record,然后最后一个写完的释放锁。 - (D) 是采用了分离 buffer insert 之后的示例。来一个请求,除了在申请分配 buffer 空间的时候经历短暂的串行执行,就执行一个请求。各自写各自的区域,写完了,检查一下前面的区域写完没有,没写完了就等,写完了就释放自己写的 region,这样下一个写完的线程才能释放自己的 region。
- (CD) 组合两种策略。与 D 类似,但是现在后面的两个线程被划分到同一个 consolidating array 里,所以这两个线程可以并发执行写 log 操作。
Performance Evaluation
略
Appendix
Details of the Log Buffer Algorithms
baseline
一个最简单、最直接的 log insert实现由以下几个步骤组成:
- 获取到一个全局锁
- 进入临界区
2.1 一个线程申请分配 log buffer 空间
2.2 写 record 到 buffer 里
2.3 释放 buffer,增加一个专用指针的指,让这次写入操作对负责 flush 的守护线程可见。 - 释放锁
这个算法有两个问题:
- 竞争程度与工作线程数量线性相关
- 临界区的(时间)长度与持有锁的工作现场的工作量线性相关
Consolidation array
Consolidation-based backoff 目的是为了减少竞争,同时更重要的是,让性能与访问 log 的线程数无关。
主要的数据结构是一个固定大小的数组,用来让线程合并请求。线程首先以非阻塞的方式请求锁,而不是无条件地等。什么意思呢?如果成功了,那就直接执行 log insert,与上面提到的算法一样。如果失败了,那么线程就回退到 consolidation array ,位置 index 用一个 offset 变量来表示。
第一个进入 consolidation array 的线程是这个 array 的拥有者,下面称为 leader。所有在 array 里等待获取锁的线程是一个组,leader 继续尝试获取锁并一直阻塞。一旦进入临界区,leader 读取 group 的 size,通过一条原子写操作标记这个 array 已经关闭了。
leader 然后请求分配 buffer 空间,在开始写 buffer 之前通知其它组员。同时,组内的线程通过组大小来推测自己在 meta-request (TODO 没看懂)中的相对位置。leader 汇报 LSN 和 buffer 的位置,其余线程就可以计算自己的 LSN 和 buffer 的位置。每一个线程写完自己的 record,就对 group 的 size 减1,返回。最后一个返回的,即检测到 size = 0 的,释放掉 buffer 上的锁(即全局锁)。
关闭后的 array 仍然不可被后续的线程访问,因为要等 array 里的线程完成写 record 操作。为了避免新到的线程一直等着,在 array 关闭的时候,每个 slot 上的线程释放掉 array 里的数据结构,相当于清空 array,让后续的线程可以进入。
Decoupled buffer fill
分离 buffer 写操作可以减少临界区的(时间)长度,竞争的程度就不会随着 log record 的大小的增长而加剧。具体实现如下:
- 一个线程获取到 log 的锁,生成 LSN,分配 buffer 空间。
- 释放锁
- 所有线程各自往自己的 region 里写 log record。每个线程都自旋等待自己的前序 region 写完后再释放自己的 region。释放操作就是将当前写完的 offset 增加,其它线程通过对比 offset 来判断前面的是否写完了。
Consolidation-based Backoff
Slot Join Operation
slot_join 函数包括以下几个步骤:
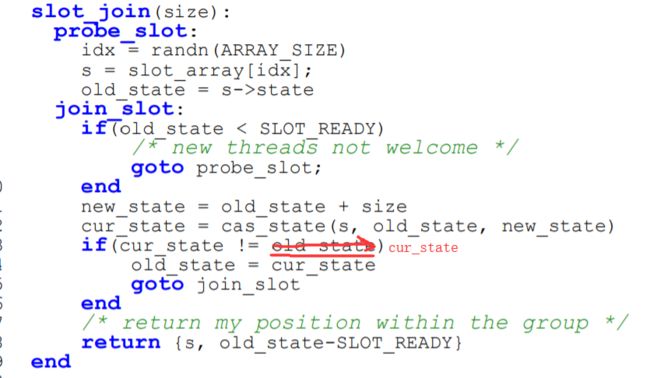
- 线程获取到一个随机的 offset,得到 array 里对应的 slot 的数据结构
- 查看 slot 是否 open,如果否的话,返回步骤 1 里,重新申请一个 slot。
这里引入了不确定性,因为随机到的 slot 开没开完全取决于随机到的 offset。
- open 后通过 CAS 来更新当前 slot 的状态,表明被占用。如果失败的话,需要回退到步骤 2。
- 返回
Slot close operation
在 leader 获取到 buffer 的锁后,关闭 group 来计算需要申请多大的 buffer,同时防止后续线程在已经提交分配申请后又加入到 group 里。
这个操作是通过使用一个原子交换,返回当前状态,并赋一个 PENDING 的新值。这个状态改变,会让后续调用 slot_join 方法的线程都失败,但是大部分的线程不会遇到失败的情况,因为一个 slot 关闭的时候,这个 slot 经过短暂的操作,前面已经提到,就把 slot 给空出来了。线程会试探整个 array,直到找到一个空 slot。因为 array 很大,所以基本上都能一发入魂。TODO 没看懂The pool allocation need not be atomic because the caller already holds the log mutex. 一个 slot 关闭后,函数返回整个组的大小,用来让调用者知道申请多少空间。
Slot notify and wait operations
Slot release and free operations
Delegated Log Buffer Release and Skew
对线程释放 buffer region 的顺序要求,造成了一个潜在的性能问题。许多很小的写操作可以跟很大的写操作并发执行,但是需要等大的写完了才能释放自己的 region。TODO 没看懂 Buffer and log file wraparounds complicate matters further, because they prevent threads from consolidating buffer releases. 而这些 wrapping buffer 的释放必须被识别出来并单独处理,因为它们会在 log flush 的时候产生额外的工作。
TODO 没看懂
CDME 算法比 CD 更健壮,但是没必要。几乎所有 records 都很小且大 record 出现的频率很低,在一般情况下,因为复杂的实现,反而会导致系统吞吐率的降低。但是,对于一些奇奇怪怪的场景,这个算法还是提供稳定的保证的。
Sensitivity to consolidation array size
线程数与 consolidation array 的大小的关系。理想情况下,性能应该只跟硬件有关,而与线程数无关。线程很多的时候,实验表明,3-4 个 slots 最好,文中用的 4 个;线程很少的时候,这个时候无所谓。
原因:TODO 没看懂 The optimal slot number corresponds closely with the number of threads required to saturate the baseline log which the consolidation array protects
A Case Against Distributed Logging
分布式的日志不适合用在数据库中,因为依赖太多,几乎无法有效地跟踪。所以作者认为,为了解决 log buffer 上的竞争,这个思路是 unattractive 和 unfeasible的。