C 预处理器在程序执行之前查看程序(故称之为预处理器).
前述:汇编过程
编译器编译源代码的一般流程是:接受源文件,转换为可执行文件。将该过程拆分为以下过程:
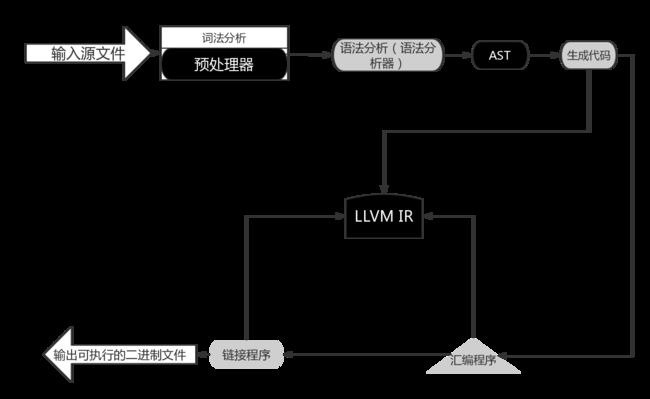
这些阶段包括词法分析、语法分析、生成代码和优化、汇编和链接,最终生成可执行的二进制文件。
- 词法分析阶段,源代码被拆分为多个记号,每个记号都是一个独立的语言元素,如关键字、操作符、标识符和符号名。
- 语法分析阶段,检查正确语法的记号,并检查它们所构成的表达式的合法性。该阶段的目的是通过记号创建抽象语法树 AST。
- 生成代码和优化阶段,AST 用于生成输出语言代码,输出语言可能是机器语言或中间语言;优化后,代码功能不变,但性能更好,体积更小。
- 汇编阶段,接收上一处理阶段生成的代码,并将它们转换为可执行的机器代码
- 链接阶段,汇编程序输出的一段或多段代码被合并为一个独立的可执行程序。
前述:预处理器
预处理器是在语法分析阶段前的词法分析阶段发挥作用的。
根据程序中的预处理器指令,预处理器把字符缩写替换成其表示的内容。预处理器可以包含程序所需的其他文件,可以选择让编译器查看哪些代码。基本上它的工作原理是把一些文本转换成另外一些文本。
预处理之前,编译器需要对程序做一些翻译处理:
- 首先,编译器把源代码中出现的字符映射到源字符集;该过程处理多字节字符和三字符序列;
- 其次,编译器定位每个反斜杠
\后面跟着换行符的实例,并删除它们。也就是说将两个物理行转换为一个逻辑行。由于预处理表达式的长度必须是一个逻辑行,所以这一步为预处理器做好了准备工作,一个逻辑行可以是多个物理行; - 接着,编译器把文本划分为预处理标记序列、空白序列和注释序列;
- 最后,程序已准备好进入预处理阶段。
printf("这是一句\
话 \n");
//上述两个物理行转为一个逻辑行
printf("这是一句话 \n");//一个逻辑行
在预处理阶段,预处理指令以 #号 作为一行的开始,到后面的第一个换行符为止;也就是说指令的长度仅限于一行,前面提到过,在预处理之前编译器会把多个物理行处理为一个逻辑行。
ANSI 允许 #号前面有空格或制表符,还允许在 # 和指令的其余部分之间有空格。指令可以出现在源文件的任何地方,其定义从指令出现的地方到文件末尾有效。
1、明示常量#define
#define DISPATCH_OBJ_ASYNC_BIT 0x1
我们常使用 #define 指令来定义明示常量(符号常量)。每个#define逻辑行都由 3 部分组成:
- 第1部分:
#define指令本身; - 第2部分:宏,宏的名称中不允许有空格,只能使用字母、数字和
_字符,且首字母不能是数字; - 第3部分:替换体,一般而言,预处理器发现程序中的宏后,会用宏等价的替换文本进行替换,如果替换的字符串还包含宏,则继续替换这些宏(双引号中的宏不被替换);从宏变成最终替换文本的过程称为宏展开。
1.1、简单使用 #define
宏可以表示任何字符串,甚至是整个 C 表达式:
#define TWO 2
#define OW "Consistency is the last refuge of the unimagina\
tive. - Oscar Wilde" /* 反斜杠将该定义延续到下一行 */
#define FOUR TWO*TWO
#define PX printf("X is %d.\n", x)
#define FMT "X is %d.\n"
int main(void)
{
int x = TWO;
PX;//宏表示整个 C 表达式
/* x = FOUR; 的实际过程:
x = TWO*TWO;
x = 2*2;
* 宏展开到此为止
*/
x = FOUR;
printf(FMT, x);//宏表示任何字符串
printf("%s\n", OW);
printf("TWO: OW\n");
return 0;
}
/*********** 程序输出 ***********
X is 2.
X is 4.
Consistency is the last refuge of the unimaginative. - Oscar Wilde
TWO: OW
*/
一般而言,预处理器发现程序中的宏后,会用宏等价的替换文本进行替换,如果替换的字符串还包含宏,则继续替换这些宏(双引号中的宏不被替换)
1.2、记号
从技术角度来看,可以把宏的替换体看做是记号型字符串,而不是字符型字符串。对于 C 预处理器,记号是宏定义的替换体中单独的“词”,用空白将这些词分开:
#define FOUR 2*2 //该宏定义有一个记号:2*2 序列
#define FOUR1 2 * 2//该宏定义有一个记号:2、*、2
替换体中有多个空格时,字符型字符串和记号型字符串的处理方式不同:
- 如果预处理器将替换体解释为字符型字符串,将用
2 * 2替换FOUR1;额外的空格也是替换体的一部分; - 如果预处理器将替换体解释为记号型字符串,将用3个记号
2 * 2替换FOUR1;额外的空格视为替换体中各记号的分隔符;
1.3、重定义常量
#define宏的作用域从它在文件中的声明处开始,直到用#undef指令取消宏为止,或者延伸到文件末尾。
#undef指令用于取消已定义的宏,即使原来没有定义该宏,使用#undef指令取消宏仍然有效:
#define LENGTH 100
#undef LENGTH//移除定义的LENGTH
如果要重定义常量,而又不确定之前是否定义过,为安全期间,使用#undef指令取消改名字的定义
1.4、类函数宏:在#define中使用参数
/* SUM 宏表示符
* (X,Y) 宏参数列表
* X+Y 替换列表
*/
#define SUM(X,Y) X+Y
{
SUM(2, 5);
}
在#define中使用参数可以创建外形和作用与函数类似的类函数宏。上述类函数宏SUM(X,Y)看上去和函数类似,但是它的行为和函数调用完全不同:
/* SUM 宏表示符
* (X,Y) 宏参数列表
* X+Y 替换列表
*/
#define SUM(X,Y) X+Y
int sum(int x ,int y)
{
return x + y;
}
int main(void)
{
int sum1 = SUM(2, 5);
int sum2 = SUM(2, 5) * SUM(2, 5);
printf("sum1 : %d\n", sum1);//sum1 : 7
printf("sum2 : %d\n", sum2);//sum2 : 17
int sum11 = sum(2, 5);
int sum12 = sum(2, 5) * SUM(2, 5);
int sum13 = sum(2, 5) * sum(2, 5);
printf("sum11 : %d\n", sum11);//sum11 : 7
printf("sum12 : %d\n", sum12);//sum12 : 19
printf("sum13 : %d\n", sum13);//sum13 : 49
return 0;
}
在上述程序中,类函数宏SUM(X,Y)与函数sum()的计算结果并不相同;因为预处理器不做计算,不求值,只替换字符序列。
SUM(2, 5) * SUM(2, 5)宏展开为2+5 * 2+5,结果为 17。
上述程序演示了函数调用与宏调用的重要区别:
- 函数调用在程序运行时将参数的值传递给函数;
- 宏调用在编译之前把参数记号传递给程序。
这两个不同的过程发生在不同时期。
一般而言,不要在宏中使用递增或递减运算符。
1.5、在字符串中使用宏参数:#运算符
C 语言允许在字符串中包含宏参数:在类函数宏的替换体中,# 作为一个预处理运算符,可以把记号转换成字符串。
/* #X 是转换为字符串 "X" 的形参名,这个过程为字符串化
*/
#define SQUARE(X) printf(""#X" 的平方是 : %d\n", X*X)
int main(void)
{
SQUARE(9);//9 的平方是 : 81
return 0;
}
1.6、预处理器黏合剂:##运算符
与#运算符类似,##运算符可用于宏的替换部分。
##运算符把两个记号组合成一个记号:
//宏展开为 22
#define SUM 2 ## 2
int main(void)
{
printf("%d\n",SUM);//22
return 0;
}
##运算符的用法:
#define XNAME(n) x ## n
#define PRINT_XN(n) printf("x" #n " = %d\n", x ## n);
int main(void)
{
int XNAME(1) = 14; // 宏展开为 int x1 = 14;
int XNAME(2) = 20; // 宏展开为 int x2 = 20;
int x3 = 30;
PRINT_XN(1);// 宏展开为 printf("x1 = %d\n", x1);
//输出为:x1 = 14
PRINT_XN(2);// 宏展开为 printf("x2 = %d\n", x2);
//输出为:x2 = 20
PRINT_XN(3);// 宏展开为 printf("x3 = %d\n", x3);
//输出为:x3 = 30
return 0;
}
在该示例中,PRINT_XN()宏用#运算符组合字符串,##运算符把记号组合为一个新的标识符。
1.7、变参宏
printf()等函数接受数量可变的参数;C99/C11 允许用户对宏自定义带可变参。
通过把宏参数列表中最后的参数写成省略号...来实现这一功能,预定义宏__VA_ARGS__可用在替换的部分中,表明省略号代表什么:
//使用#运算符实现字符串的串联功能;
//使用 ... 和 __VA_ARGS__ 实现可变参数
#define PX(X,...) printf("输出"#X" : "__VA_ARGS__)
int main(void)
{
PX(1, "数量可变参数 \n");//输出1 : 数量可变参数
PX(2,"a = %d , a^2 = %d \n",5,5*5);//输出2 : a = 5 , a^2 = 25
return 0;
}
注意:省略号只能代替最后的参数。
1.8、宏与函数的选择
针对某些任务,既可以使用函数来完成,也可以使用宏完成,我们需要在内存空间与运行效率上权衡:
- 在空间权衡上:使用宏,生成内联代码(即在程序中生成语句),如果调用100次宏,就在程序中插入100行代码;
而调用100次函数,程序只有一份函数的副本,所以节省了内存空间。 - 在运行效率上:程序调用函数,必须跳转至函数内部,随后再返回主调函数,这显然比内联代码花费时间。
如果打算使用宏来加快程序的运行速度,需要先确定宏与函数在运行效率上是否存在较大差异:只使用一次的宏无法明显减少程序运行时间;在嵌套中使用宏有助于提高效率。
一些任务如下所示:
#define SQUARE(X) ((X)*(X))
#define SUM(X,Y) (X+Y)
#define MAX(X,Y) ((X) > (Y) ? (X) : (Y))
int square(int x)
{
return x * x;
}
int sum(int x ,int y)
{
return x + y;
}
int max(int x ,int y)
{
return x > y ? x : y;
}
在上述例子中,使用宏比函数复杂,容易出错。如#define SQUARE(X) (X*X),此时使用SQUARE(2+3)得到的结果就会与预期不符。
但是,宏也有优点:宏不必考虑数据类型,如SQUARE()既可计算int 型又可计算float 型,但是square()只能计算int 。因为宏处理的是字符串,而不是实际的值。
1.9、慎重使用宏
注意:不要过度使用宏
宏尤其是函数宏具有强大的功能,但是使用它们的危险性非常大。
因为预处理器的操作是在对源文件进行语法解析前执行的,所以要正确定义能够适用于所有情况的宏非常困难。
另外,向函数型宏传递带 副作用(参数值被更改)通常会引发问题,这可能导致一个或多个参数被计算多次,因而在无意中修改它们的值,这种问题很难发现。
1.9.1、常量类型问题
#define HEIGHT 100
上述预处理指令会把源代码中的 HEIGHT字符串替换为 100,这样定义的常量没有类型信息,无法清晰的了解该常量的含义。
我们可以使用下述方法来实现:
static float const kMainHeight = 100;
该方式定义的常量包含类型信息,清楚的描述了常量的含义,让读者阅读代码时更易理解其意图。
实际上,如果一个常量既声明为static,又声明为const,那么编译器根本不会创建符号,而是会像预处理指令 #define一样,把所有遇到的变量都替换为常值。
在编译时,编译器将kMainHeight存储到全局静态区的数据段。
1.9.2、宏常量被篡改的危险
我们在一个有文件定义的宏常量HEIGHT可能会在别的文件遭人篡改,而我们并不能发现这个问题。
但是,使用kMainHeight由于const限制,当我们在别处修改此值时,编译会报错,因此编译器确保该常量不变。
#define HEIGHT 100
float const kMainHeight = 300.0;
2、文件包含#include
当预处理器发现#include指令时,会查看后面的文件名并把文件的内容包含到当前文件中,即替换源文件中的#include指令。这相当于把被包含文件的全部内容输入到源文件#include指令所在的位置。
#include指令促进了代码重用,因为源文件可以直接使用外部类的#define常量、结构声明、函数原型等,而无需复制它们。
#include指令有两种形式,这两种形式的唯一区别在于编译器寻找文件的方式:
-
#include <>:编译器在标准系统目录中查找该文件; -
#include "": 编译器首先在当前目录中查找该文件,如果没有找到,再去标准系统目录中查找该文件;
2.1、#import 指令
#import 指令与#include指令一样,包含头文件,指令有两种形式。
#import 指令与#include的区别在于:#import确保头文件仅在源文件中被包含一次,防止递归包含。
- 如源文件
main.m中包含头文件A.h、B.h;而这两个文件又都包含头文件C.h,这就出现了源文件main.m中重复包含头文件C.h的情况。 - 然而源文件
main.m通过#import指令包含头文件A.h、B.h,那么头文件C.h仅会被源文件main.m包含一次。
3、条件编译
使用条件编译指令,可以根据条件是否成立,确定包含或者不包含部分或全部源代码。
3.1、#ifdef、#else 和 #endif指令
#ifdef Debug
#define LENGTH 100
#else
#define LENGTH 200
#endif
#ifdef指令说明,如果预处理器已定义了后面的标识符Debug,则执行#ifdef与#else之间的代码;如果没有定义后面的标识符,则执行#else 与 #endif之间的代码
3.2、#ifndef指令
#ifndef指令与#else 、 #endif一起使用。、#ifndef指令判断后面的标识符是否未定义:如果后面的标识符未定义,则执行#ifndef与#else之间的代码;如果已经定义后面的标识符,则执行#else 与 #endif之间的代码。
3.2.1、用法一:防止相同的宏被重复定义
#ifndef常用于定义之前未定义的常量:
#ifndef HEIGHT
#define HEIGHT 100
#endif
当多个头文件包含相同宏时,#ifndef指令可以防止相同的宏被重复定义,在首次定义一个宏的头文件中使用#ifndef指令激活宏,随后在其它头文件的定义都被忽略。
3.2.2、用法二:防止多次包含头一个文件
我们创建一个Queue.h文件,可以看到如下代码
#ifndef Queue_h
#define Queue_h
#endif
当预处理器首次发现该文件被包含时,Queue_h是未定义的,所以定义Queue_h,并接着处理该文件的其它部分;当预处理器第2次发现该文件被包含时,Queue_h已定义,所以预处理器直接跳过此处。
C 标准头文件使用#ifndef技巧避免重复包含。
3.3、#if 和 #elif 指令
#if 指令 后面跟整型常量表达式,如果表达式非零,则为真。
#if HEIGHT == 100
#endif
#if 指令的另一种方式是测试名称是否已定义:
#if defined (Debug)
//#ifdef Debug
#endif
在此处,defined 是一个预处理运算符,如果它的参数被#defined定义过则返回 1 ,否则返回 0。
使用这种判断方法,与#ifdef相比,它的优点是可以与 #elif一起使用
#if defined (MAC)
#elif defined (VAX)
#elif defined (IBMPC)
#endif
4、预定义宏
| 宏 | 含义 |
|---|---|
__DATE__ |
预处理器的日期 |
__FIFE__ |
表示当前源码文件名的字符串字面量 |
__LINE__ |
表示当前源码文件中行号的整型常量 |
__ STDC__ |
设置为 1 时,表示实现遵循 C 标准 |
__STDC_HOSTED__ |
本机环境设置为 1,否则为 0 |
__STDC_VERSION__ |
支持 C99 标准,设置为 199901L;支持 C11 标准,设置为 201112L |
__TIME__ |
翻译代码的时间,格式为 hh:mm:ss |
void func(void);
int main(void)
{
printf("当前源码文件路径 %s.\n", __FILE__);
printf("当前日期 %s.\n", __DATE__);
printf("代码执行到此处的时间 %s.\n", __TIME__);
printf("支持的C99/C11标准 %ld.\n", __STDC_VERSION__);
printf("当前代码所在行 %d.\n", __LINE__);
printf("该函数名 %s\n", __func__);
func();
return 0;
}
void func()
{
printf("该函数名 %s\n", __func__);
printf("当前代码所在行 %d.\n", __LINE__);
}
运行此程序,获得输出:
当前源码文件路径 /Users/longlong/Desktop/Array/Array/main.c.
当前日期 Nov 28 2018.
代码执行到此处的时间 21:01:56.
支持的C99/C11标准 201112.
当前代码所在行 19.
该函数名 main
该函数名 func
当前代码所在行 29.
5、#line 指令
#line指令重置__LINE__和__FIFE__ 宏报告的行号和文件名:用法如下所示:
#line 30
printf("当前代码所在行 %d.\n", __LINE__);//当前代码所在行 30.
#line 100 "newFileName"
printf("当前源码文件路径 %s.\n", __FILE__);//当前源码文件路径 newFileName.
printf("当前代码所在行 %d.\n", __LINE__);//当前代码所在行 102.
6、#error指令
#error指令可以让预处理器发出一条错误消息,该消息包含指令中的文本;如果编译失败,编译过程中断
使用下述用法判断编译器是否支持 C99标准
#if __STDC_VERSION__ != 199901
#error Not C11
#endif
7、#warning指令
使用#warning指令可以生成编译时警告消息,但允许编译器继续编译
8、泛型选择
泛型编程指那些没有特定类型,但是一旦被指定一种类型,就可以转换成指定类型的代码。
C11增加了泛型表达式:_Generic(x,int:0,float:1,double:2,default:3) 。
_Generic是C11增加的关键字,后面的圆括号中包含多个用逗号分隔的项。第一个项是一个表达式,后面每一项都由一个类型、一个冒号、和一个值组成;第一项的类型匹配哪个后面哪一项的标签,_Generic表达式就返回标签后面的值;如果没有匹配类型,_Generic表达式的值就是default后面的值。
printf("%d\n", _Generic(2.0f,int:0,float:1,double:2,default:3));
//输出为 1 ,表示 2.0f 是 float 类型
常把泛型表达式用作#define宏定义的一部分:
#define MYTYPE(X) _Generic((X),\
int: "int",\
float : "float",\
double: "double",\
default: "other"\
)
int main(void)
{
int d = 5;
printf("%s\n", MYTYPE(d)); // d 是int型
printf("%s\n", MYTYPE(2.0*d)); // 2.0*d 是double型
printf("%s\n", MYTYPE(3L)); // 3L 是long型
printf("%s\n", MYTYPE(&d)); // &d 是int *型
return 0;
}
/** 输出结果:
int
double
other
other
*/