姓名:刘亚宁 学号:17101223434
转载自:https://www.leiphone.com/news/201712/6F577yaQueXAppZG.html,有删节。
【嵌牛导读】:循环神经网络(RNN)已经在众多自然语言处理中取得了大量的成功以及广泛的应用。但是,网上目前关于RNNs的基础介绍很少,本文便是介绍RNNs的基础知识,原理以及在自然语言处理任务重是如何实现的。文章内容根据雷锋网AI研习社线上分享视频整理而成。
【嵌牛鼻子】:RNN、语音识别、人工智能
【嵌牛提问】:如何用循环神经网络实现语音识别?
【嵌牛正文】:在近期雷锋网AI研习社的线上分享会上,来自平安科技的人工智能实验室的算法研究员罗冬日为大家普及了RNN的基础知识,分享内容包括其基本机构,优点和不足,以及如何利用LSTM网络实现语音识别。
罗冬日分享的RNN主要有:
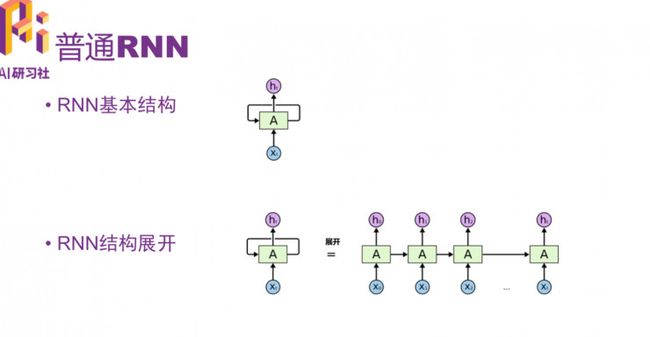
普通RNN结构
普通RNN的不足
LSTM单元
GRU单元
采用LSTM实现语音识别的例子
RNN和CNN的区别
普通卷积神经网络(CNN)处理的是“静态”数据,样本数据之间独立,没有关系。
循环神经网络(RNN)处理的数据是“序列化”数据。 训练的样本前后是有关联的,即一个序列的当前的输出与前面的输出也有关。比如语音识别,一段语音是有时间序列的,说的话前后是有关系的。
总结:在空间或局部上有关联图像数据适合卷积神经网络来处理,在时间序列上有关联的数据适合用循环时间网络处理。但目前也会用卷积神经网络处理语音问题, 或自然言语理解问题,其实也是把卷积神经网络的计算方法用到这上面。
RNN 的基本结构和结构展开示意图:
普通RNN不足之处

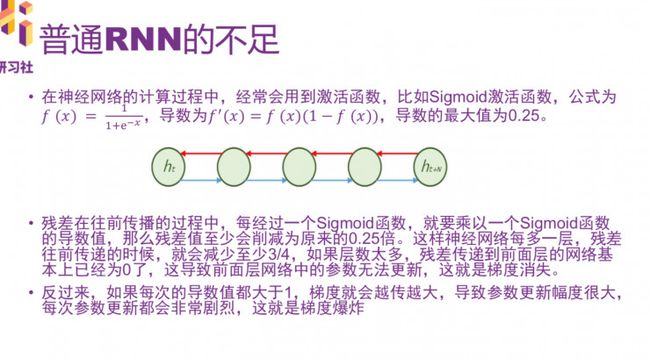
首先是神经网络里面的计算,可以大致分为三类:函数合成,函数相加,加权计算。
在计算过程中,经常会用到激活函数,比如Sigmoid激活函数。残差在往前传播的过程中,每经过一个Sigmoid函数,就要乘以一个Sigmoid函数的导数值,残差值至少会因此消减为原来的0.25倍。神经网络每多一层,残差往前传递的时候,就会减少至少3/4。如果层数太多,残差传递到前面已经为0,导致前层网络中国呢的参数无法更新,这就是梯度消失。
LSTM单元和普通RNN单元的区别
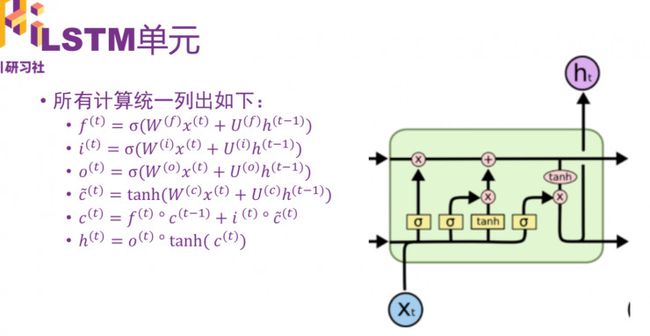
主要大的区别是,采用一个叫“细胞状态(state)”的通道贯穿了整个时间序列。
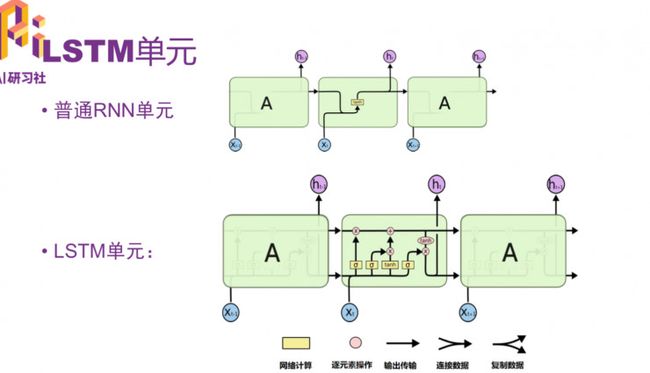
通过精心设计的称作“门”的结构来去除或增加信息到细胞状态的能力。
"忘记门”
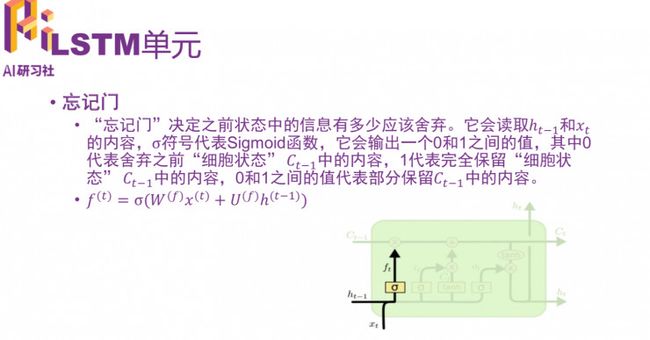
“输入门”的打开关闭也是由当前输入和上一个时间点的输出决定的。
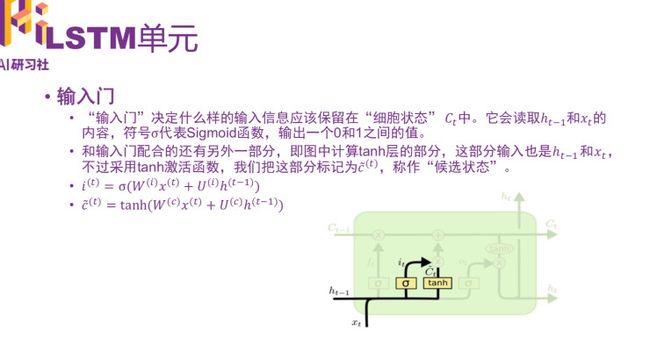
“输出门”,控制输出多少,最终仅仅会输出确定输出的那部分。
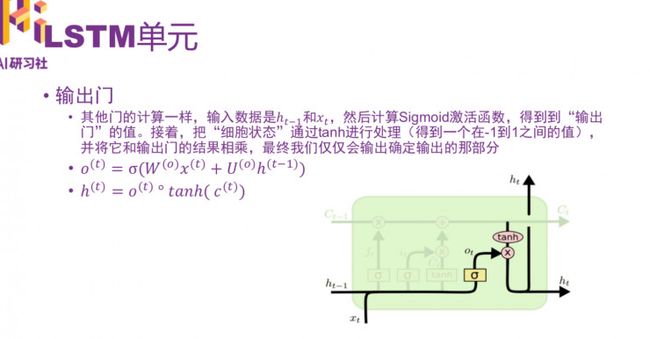
所有的公式汇总:
增加peephole的LSTM单元

让几个“门”的输入数据除了正常的输入数据和上一个时刻的输出以外,再接受“细胞状态”的输入。
GRU单元

它是各种变种之一,将“忘记门”和“输入们”合成了一个单一的“更新门”,同时还混合了细胞状态和隐藏状态。
接下来用RNN做一个实验,给大家介绍一个简单的语音识别例子:
关于LSTM+CTC背景知识
2015年,百度公开发布的采用神经网络的LSTM+CTC模型大幅度降低了语音识别的错误率。采用这种技术在安静环境下的标准普通话的识别率接近97%。
CTC是Connectionist Temporal Classification 的缩写,详细的论文介绍见论文“Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks”
CTC的计算实际上是计算损失值的过程,就像其他损失函数一样,它的计算结果也是评估网络的输出值和真实差多少。
声音波形示意图
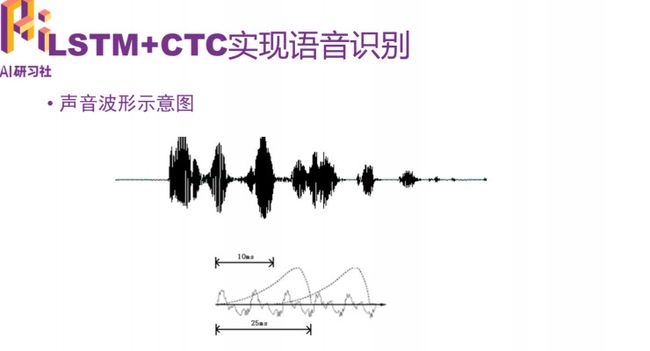
在开始之前,需要对原始声波进行数据处理,输入数据是提取过声学特征的数据,以帧长25ms、帧移10ms的分帧为例,一秒钟的语音数据大概会有100帧左右的数据。
采用MFCC提取特征,默认情况下一帧语音数据会提取13个特征值,那么一秒钟大概会提取100*13个特征值。用矩阵表示是一个100行13列的矩阵。
把语音数据特征提取完之后,其实就和图像数据差不多了。只不过图像数据把整个矩阵作为一个整体输入到神经网络里面处理,序列化数据是一帧一帧的数据放到网络处理。
如果是训练英文的一句话,假设输入给LSTM的是一个100*13的数据,发音因素的种类数是26(26个字母),则经过LSTM处理之后,输入给CTC的数据要求是100*28的形状的矩阵(28=26+2)。其中100是原始序列的长度,即多少帧的数据,28表示这一帧数据在28个分类上的各自概率。在这28个分类中,其中26个是发音因素,剩下的两个分别代表空白和没有标签。
设计的基本网络机构

原始的wav文件经过声学特征提取变成N*13,N代表这段数据有多长,13是每一帧数据有多少特征值。N不是固定的。然后把N*13矩阵输入给LSTM网络,这里涉及到两层双向LSTM网络,隐藏节点是40个,经过LSTM网络之后,如果是单向的,输出会变成40个维度,双向的就会变成80个维度。再经过全连接,对这些特征值分类,再经过softmax计算各个分类的概率。后面再接CDC,再接正确的音素序列。
真实的语音识别环境要复杂很多。实验中要求的是标准普通话和安静无噪声的环境。
如果对代码讲解(详细代码讲解请点击视频)感兴趣的话,可以复制链接中的代码:https://github.com/thewintersun/tensorflowbook/tree/master/Chapter6
运行结果如下:
