训练数据格式
训练数据格式为一行一个句子,每个词用空格分割,如果一个词带有前缀“__label__”,那么它就作为一个类标签,在文本分类时使用,这个前缀可以通过-label参数自定义。训练文件支持 UTF-8 格式。
FastText模块
void FastText::train(const Args args) 初始化参数,启动多线程训练
①根据输入文件初始化词典。
②初始化输入层。对于普通 word2vec,输入层就是一个词向量的查找表,所以它的大小为 nwords 行,dim 列(dim 为词向量的长度),但是 fastText 用了 word n-gram 作为输入,所以输入矩阵的大小为 (nwords + ngram 种类) * dim。代码中,所有 word n-gram 都被 hash 到固定数目的 bucket 中,所以输入矩阵的大小为 (nwords + bucket 个数) * dim.
词向量的个数是单词的数量加上桶的个数。多个ngram或是字符ngram会在一个桶中共享一个向量
(一个HASH的结果所对应的地址可存放两个BUCKET。可解决HASH冲突。 要存数据时,第一次HASH到这里,在第一个BUCKET存放一个数据。 要存数据时,当第二次因某些原因HASH到这里时,在第二个BUCKET存放另一个数据。)
③ 初始化输出层,输出层无论是用负采样,层次 softmax,还是普通 softmax,对于每种可能的输出,都有一个 dim 维的参数向量与之对应。当 args_->model == model_name::sup 时,训练分类器, 所以输出的种类是标签总数 dict_->nlabels();否则训练的是词向量,输出种类就是词的种类 dict_->nwords()。
④库采用 C++ 标准库的 thread 来实现多线程,实际的训练发生在 trainThread 中。
void FastText::trainThread(int32_t threadId) 实现了标准的随机梯度下降,并随着训练的进行逐步降低学习率
①根据线程数,将训练文件按照总字节数均分成多个部分。这么做的一个后果是,每一部分的第一个词有可能从中间被切断, 这样的"小噪音"对于整体的训练结果无影响。
②根据训练需求的不同,这里用的更新策略也不同,它们分别是: 1. 有监督学习(分类)2. word2vec (CBOW) 3. word2vec (SKIPGRAM)
void FastText::supervised(Model& model,real lr,const std::vector& line,const std::vector& labels)
因为一个句子可以打上多个 label,但是 fastText 的架构实际上只有支持一个 label,所以这里随机选择一个 label 来更新模型,这样做会让其它 label 被忽略, 所以 fastText 不太适合做多标签的分类。update会对line中的所有的单词向量取平均,去预测label
voidFastText::cbow(Model& model, real lr,conststd::vector& line)
在一个句子中,每个词可以进行一次 update,一个词的上下文长度是随机产生的,以当前词为中心,将左右 boundary 个词加入 input,实际被加入 input 的不止是词本身,还有词的 word n-gram。
voidFastText::skipgram(Model& model, real lr,conststd::vector& line)
一个词的上下文长度是随机产生的,采用词+word n-gram 来预测这个词的上下文的所有的词,在 skipgram 中,对上下文的每一个词分别更新一次模型
void FastText::predict(std::istream& in,int32_t k,bool print_prob,real threshold) 预测
①读取输入文件的每一行,将一个词的 n-gram 加入词表,用于处理未登录词。(即便一个词不在词表里,我们也可以用它的 word n-gram 来预测一个结果)
②调用 model 模块的预测接口,获取 k 个最可能的分类,输出结果
model 模块
model 模块对外提供的服务可以分为 update 和 predict 两类
update
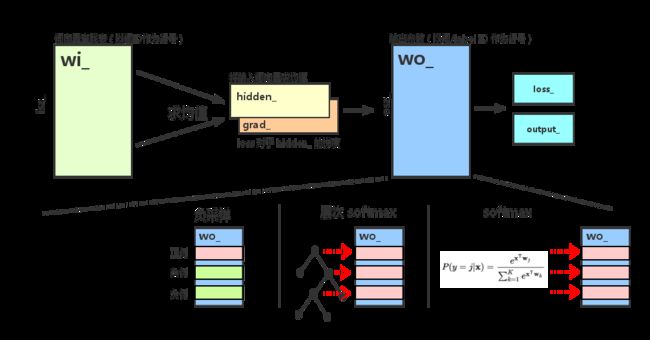
void Model::update(const std::vector& input, int32_t target, real lr) 前向传播算出了 loss_,反向传播计算出 grad_
①计算前向传播:输入层 -> 隐层
②hidden_ 向量保存输入词向量的均值,和CBOW一样(将 wi_ 矩阵的第 *it 列加到 hidden_ 上,求和后除以输入词个数,得到均值向量)
③根据输出层的不同结构,调用不同的函数:1. 负采样, 2. 层次 softmax, 3. 普通 softmax
④如果是在训练分类器,就将 grad_ 除以 input_ 的大小
⑤反向传播,将 hidden_ 上的梯度传播到 wi_ 上的对应行
将层次 softmax 和负采样统一抽象成多个二元 logistic regression 计算:
如果使用负采样,训练时每次选择一个正样本,随机采样几个负样本,每种输出都对应一个参数向量,保存于 wo_ 的各行。对所有样本的参数更新,都是一次独立的 LR 参数更新。
如果使用层次 softmax,对于每个目标词,都可以在构建好的霍夫曼树上确定一条从根节点到叶节点的路径,路径上的每个非叶节点都是一个 LR,参数保存在 wo_ 的各行上,训练时,这条路径上的 LR 各自独立进行参数更新。
real Model::negativeSampling(int32_t target, real lr) 对于正样本和负样本,分别更新 LR
real Model::hierarchicalSoftmax(int32_t target, real lr) 先确定霍夫曼树上的路径, 分别对路径上的中间节点做 LR
real Model::softmax(int32_t target, real lr) 普通 softmax 的参数更新
计算softmax,更新累积梯度,将来更新输入向量去
*分层softmax时,wo_的行数为osz_ - 1,也就是非叶子节点个数。wo_矩阵表示的含义也是非叶子节点的参数
predict
void Model::predict(const std::vector& input, int32_t k, real threshold,std::vector>& heap,Vector& hidden, Vector& output) 用于给输入数据打上 1 ~ K 个类标签,并输出各个类标签对应的概率值
①计算 hidden_
②如果是层次 softmax,使用 dfs 遍历霍夫曼树的所有叶子节点,找到 top-k 的概率;如果是普通 softmax,在结果数组里找到 top-k,对结果进行排序后输出。
构建霍夫曼树算法分析
void Model::buildTree(const std::vector& counts)
算法首先对输入的叶子节点进行一次排序,然后确定两个下标 leaf 和 node,leaf 总是指向当前最小的叶子节点,node 总是指向当前最小的非叶子节点,所以,最小的两个节点可以从 leaf, leaf - 1, node, node + 1 四个位置中取得,每个非叶子节点都进行一次。
dictionary
关于字符串映射过程,以及如何建立一套索引的,详情见下图:涉及的函数主要是find,内部实现需要hash函数建立hash规则,借助2个vector来进行关联。StrToHash(find函数) HashToIndex(word2int数组) IndexToStruct(words_数组)

ngram实际上全在dictionary类中处理了。dictionary类直接返回line,line中包括了单词以及ngram的id。