一、设计方案
1.网络爬虫名称:知乎今日热榜
2.内容:爬取今日热榜事件、排名和热度,爬取的数据呈一定规律排序
3.先确定爬取网站,用requests请求网站打印出html页面,之后用BeautifulSoup提取数据,将数据保存为csv文件中;之后进行pandas进行数据分析和数据可视化;难点在于怎么将数据进行加工保存下来,由于网站更新导致部分数据不一致。
二、页面结构特征分析
1.通过观察寻找可知td class="al"为所需要的的事件标签,td为热度标签
2.页面解析:

三
1.数据爬取与采集
import requests from bs4 import BeautifulSoup import pandas as pd from matplotlib import pyplot as plt from sklearn.linear_model import LinearRegression import seaborn as sns from scipy.optimize import leastsq url='https://tophub.today/n/mproPpoq6O' headers={'user-Agent':url} #自定义headers请求页面 r=requests.get(url,headers=headers) r.raise_for_status() #异常捕捉 r.encoding=r.apparent_encoding #print(r.text) 打印出html页面 soup=BeautifulSoup(r.content,'html.parser') #获取数据 title=soup.find_all("td",{"class":"al"}) val=soup.find_all("td") list_title=[] list_val=[] index = 1 for val in val[:80]: if index==1 or index==2 or index==3: str = val.get_text() if index==3: str = str.replace("万热度","") list_val.append(str) if index == 4: list_title.append(list_val) list_val=[] index = 0 index+=1 #保存数据到csv文件 df=pd.DataFrame(list_title,columns=['排名','标题','热度(万)']) #print(df) filename="知乎今日热榜" df.to_csv('C:\\wenjian\\aaa.csv',encoding="utf-8")

2.数据分析
df=pd.read_csv('C:\\wenjian\\aaa.csv') #读取数据 #print(df.head()) #删除标题,数据分析不需要 df.drop('标题',axis=1,inplace=True) print(df)

#查看是否存在重复值 print(df.duplicated())

#查看空值和缺失值 a=df['排名'].isnull().value_counts() b=df['热度(万)'].isnull().value_counts() print(a,b)

#判断是否存在异常值 print(df.describe())

#数据分析模型 predict_model = LinearRegression() predict_model.fit(X,df['热度(万)']) print("回归系数为:",predict_model.coef_)
![]()
#回归图
c=sns.regplot(x='排名',y='热度(万)',data=df) print(c)

4.数据可视化
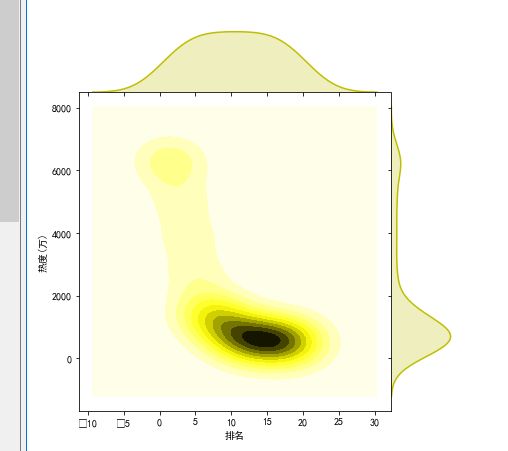
#散点图 plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 a=sns.jointplot(x="排名",y="热度(万)",data=df,kind='kde',space=0,color="y") print(a)
plt.figure() x=df.loc[:,'排名'] y=df.loc[:,'热度(万)'] #绘制折线图 plt.plot(x, y,color='green') plt.xlabel('排名') plt.ylabel('热度(万)') plt.title("排名与热度折线图") plt.show()

#绘制水平柱形图 plt.xlabel('排名') plt.ylabel('热度(万)') plt.barh(x,y) plt.title("排名与热度水平柱形图") plt.show()

5.
#分析排名与热度相关性 b=df['排名'].corr(df['热度(万)']) print(b)
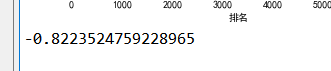
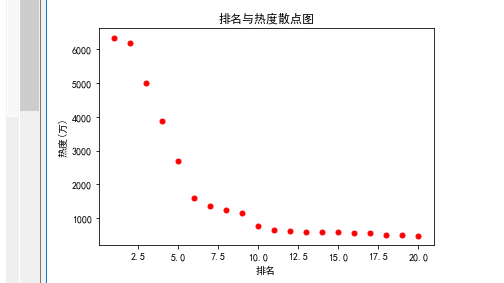
#(2).排名与热度散点图
plt.scatter(x,y,color='red',s=25,marker="o")
plt.xlabel('排名')
plt.ylabel('热度(万)')
plt.title("排名与热度散点图")
plt.show()
#(3).回归方程 X=df.loc[:,'排名'] Y=df.loc[:,'热度(万)']def func(params,x): a,b,c=params return a*x*x+b*x+c def error_func(params,x,y): return func(params,x)-y P0=[1,6341] def main(): plt.figure(figsize=(8,6)) P0=[1,6197,2] Para=leastsq(error_func,P0,args=(X,Y)) a,b,c=Para[0] print("a=",a, "b=",b, "c=",c) plt.scatter(X,Y,color="green",label="样本数据",linewidth=2) x=np.linspace(1,20,40) y=a*x*x+b*x+c plt.plot(x,y,color="red",label="拟合曲线",linewidth=2) plt.xlabel('排名') plt.ylabel('热度(万)') plt.title("排名与热度回归方程") plt.grid() plt.legend() plt.show() main()

7.代码汇总
import requests from bs4 import BeautifulSoup import pandas as pd import numpy as np from matplotlib import pyplot as plt from sklearn.linear_model import LinearRegression import seaborn as sns from scipy.optimize import leastsq #1.数据爬取与采集 url='https://tophub.today/n/mproPpoq6O' headers={'user-Agent':url} #自定义headers请求页面 r=requests.get(url,headers=headers) r.raise_for_status() #异常捕捉 r.encoding=r.apparent_encoding #print(r.text) 打印出html页面 soup=BeautifulSoup(r.content,'html.parser') #获取数据 title=soup.find_all("td",{"class":"al"}) val=soup.find_all("td") list_title=[] list_val=[] index = 1 for val in val[:80]: if index==1 or index==2 or index==3: str = val.get_text() if index==3: str = str.replace("万热度","") list_val.append(str) if index == 4: list_title.append(list_val) list_val=[] index = 0 index+=1 #保存数据到csv文件 df=pd.DataFrame(list_title,columns=['排名','标题','热度(万)']) #print(df) filename="知乎今日热榜" df.to_csv('C:\\wenjian\\aaa.csv',encoding="utf-8") #2.数据分析 df=pd.read_csv('C:\\wenjian\\aaa.csv') #读取数据 #print(df.head()) #删除标题,数据分析不需要 df.drop('标题',axis=1,inplace=True) print(df) #查看是否存在重复值 print(df.duplicated()) #查看空值和缺失值 a=df['排名'].isnull().value_counts() b=df['热度(万)'].isnull().value_counts() print(a,b) #判断是否存在异常值 print(df.describe()) #数据分析模型 predict_model = LinearRegression() predict_model.fit(X,df['热度(万)']) print("回归系数为:",predict_model.coef_) #回归图 c=sns.regplot(x='排名',y='热度(万)',data=df) print(c) #4.数据可视化 #散点图 plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 a=sns.jointplot(x="排名",y="热度(万)",data=df,kind='kde',space=0,color="y") print(a) plt.figure() x=df.loc[:,'排名'] y=df.loc[:,'热度(万)'] #绘制折线图 plt.plot(x, y,color='green') plt.xlabel('排名') plt.ylabel('热度(万)') plt.title("排名与热度折线图") plt.show() #绘制水平柱形图 plt.xlabel('排名') plt.ylabel('热度(万)') plt.barh(x,y) plt.title("排名与热度水平柱形图") plt.show() #5(1).分析排名与热度相关性 b=df['排名'].corr(df['热度(万)']) print(b) #(2).排名与热度散点图 plt.scatter(x,y,color='red',s=25,marker="o") plt.xlabel('排名') plt.ylabel('热度(万)') plt.title("排名与热度散点图") plt.show() #(3).回归方程 X=df.loc[:,'排名'] Y=df.loc[:,'热度(万)'] plt.rcParams['font.sans-serif']=['SimHei'] def func(params,x): a,b,c=params return a*x*x+b*x+c def error_func(params,x,y): return func(params,x)-y P0=[1,82.2] def main(): plt.figure(figsize=(8,6)) P0=[1,61.2,2] Para=leastsq(error_func,P0,args=(X,Y)) a,b,c=Para[0] print("a=",a, "b=",b, "c=",c) plt.scatter(X,Y,color="green",label="样本数据",linewidth=2) x=np.linspace(1,20,40) y=a*x*x+b*x+c plt.plot(x,y,color="red",label="拟合曲线",linewidth=2) plt.xlabel('排名') plt.ylabel('热度(万)') plt.title("排名与热度回归方程") plt.grid() plt.legend() plt.show() main()
四.结论
1.通过数据分析与可视化可得出,排名越靠前的事件热度越高且不断呈下降趋势,由此可以更直观看到数据的变化和趋势,以便我们观察数据
2.在数据爬取中不断地学习了一些函数的使用以及绘图的方法,使用图表、图形对数据的理解和分析中更加简单清晰,简单回复了以前的一些知识点,设计过程中遇到的困难通过百度和视频学习基本可解决。