论文:Bag of Tricks for Efficient Text Classification
1.Introduce
We evaluate the quality of our approach fastText1 on two different tasks, namely tag prediction and sentiment analysis.
两种评价方法:标签预测、情感分析
2.Model architecture
A simple and efficient baseline for sentence classification is to represent sentences as bag of words (BoW) and train a linear classifier, e.g., a logistic regression or an SVM
句子分类:使用词袋模型 BoW表示句子,然后训练线性分类器
However, linear classifiers do not share parameters among features and classes.This possibly limits their generalization in the context of large output space where some classes have very few examples. Common solutions to this problem are to factorize the linear classifier into low rank matrices or to use multilayer neural networks
线性分类器的缺点:不共享参数,在输出空间很大的情况下泛化能力较差
解决办法:将线性分类器分解为低秩矩阵或者使用多层神经网络
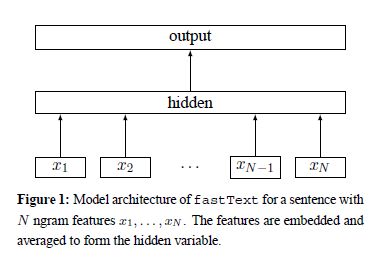
The first weight matrix A is a look-up table over the words.
The word representations are then averaged into a text representation, which is in turn fed to a linear classifier.
The text representation is an hidden variable which can be potentially be reused.
FastText模型和CBOW模型类似,CBOW是上下文单词的词向量平均去预测中心词,fasttext是整个文档的单词的词向量平均去预测标签
使用softmax模型计算分类的概率,使用negiative log-likelihood作为代价函数

This model is trained asynchronously on multiple CPUs using stochastic gradient descent and a linearly decaying learning rate.
2.1 Hierarchical softmax
When the number of classes is large
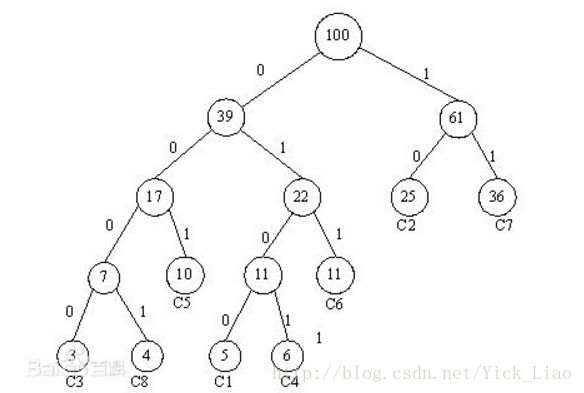
基于哈夫曼编码:每个节点与从根节点到该节点的概率有关
复杂度:O(kh) ---> O(h log2(k)) ,where k is the number of classes and h the dimension of the text representation
优势:when searching for the most likely class
Each node is associated with a probability that is the probability of the path from the root to that node. If the node is at depth l+1 with parents n1, . . . , nl, its probability is
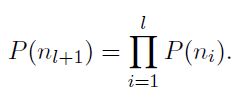
一个节点的概率总是小于其父节点。DFS遍历一棵树,并且总是遍历叶子节点中概率较大的那个。
This approach is further extended to compute the T-top targets at the cost of O(log(T)), using a binary heap.
将输入层中的词和词组构成特征向量,再将特征向量通过线性变换映射到隐藏层,隐藏层通过求解最大似然函数,然后根据每个类别的权重和模型参数构建Huffman树,将Huffman树作为输出。
FastText 也利用了类别(class)不均衡这个事实(一些类别出现次数比其他的更多),通过使用 Huffman 算法建立用于表征类别的树形结构。因此,频繁出现类别的树形结构的深度要比不频繁出现类别的树形结构的深度要小,这也使得进一步的计算效率更高。


2.2 N-gram features
词袋模型(BoW)对于一个文本,忽略其词序和语法,句法,将其仅仅看做是一个词集合,或者说是词的一个组合,文本中每个词的出现都是独立的,不依赖于其他词是否出现。
we use a bag of n-grams as additional features to capture some partial information about the local word order.
加入N-gram特征,以捕捉局部词序;使用Hash-Trick方法降维
3 Experiments
First, we compare it to existing text classifers on the problem of sentiment analysis.
Then, we evaluate its capacity to scale to large output space on a tag prediction dataset.
①情感分析
②输出空间很大标签预测
3.1 Sentiment analysis
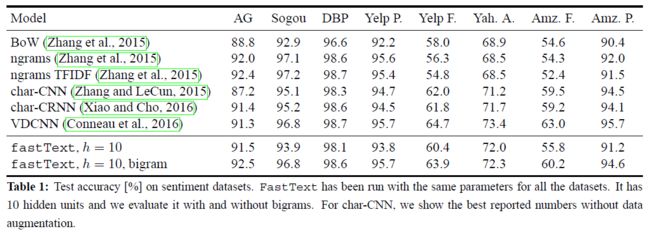
We present the results in Figure 1. We use 10 hidden units and run fastText for 5 epochs with a learning rate selected on a validation set from {0.05, 0.1, 0.25, 0.5}.
On this task,adding bigram information improves the performanceby 1-4%. Overall our accuracy is slightly better than char-CNN and char-CRNN and, a bit worse than VDCNN.
Note that we can increase the accuracy slightly by using more n-grams, for example with trigrams.
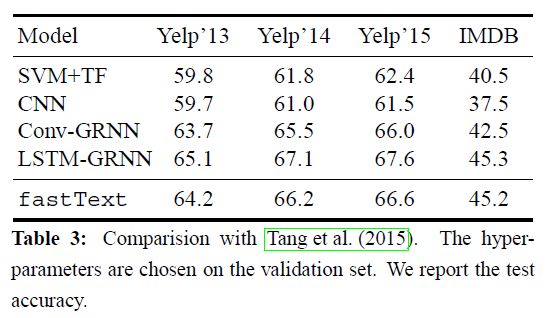
We tune the hyperparameters on the validation set and observe that using n-grams up to 5 leads to the best performance.
3.2 Tag prediction
To test scalability of our approach, further evaluation is carried on the YFCC100M dataset which consists of almost 100M images with captions,titles and tags. We focus on predicting the tags according to the title and caption (we do not use the images).
We remove the words and tags occurring less than 100 times and split the data into a train, validation and test set.
We consider a frequency-based baseline whichpredicts the most frequent tag. we consider the linear version.
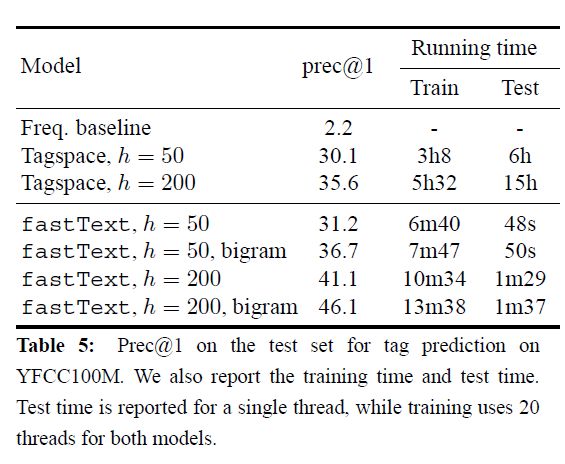
We run fastText for 5 epochs and compare it to Tagspace for two sizes of the hidden layer, i.e., 50 and 200. Both models achieve a similar performance with a small hidden layer, but adding bigrams gives us a significant boost in accuracy.
At test time, Tagspace needs to compute the scores for all the classes which makes it relatively slow,while our fast inference gives a significant speed-up when the number of classes is large (more than 300K here).
Overall, we are more than an order of magnitude faster to obtain model with a better quality.
4 Discussion and conclusion
Unlike unsupervisedly trained word vectors from word2vec, our word features can be averaged together to form good sentence representations.
In several tasks, fastText obtains performance on par with recently proposed methods inspired by deep learning, while being much faster.
Although deep neural networks have in theory much higher representational power than shallow models, it is not clear if simple text classification problems such as sentiment analysis are the right ones to evaluate them.
输入是一句话,x1到xN是这句话的单词或是ngram。每一个都对应一个向量,对这些向量取平均就得到了文本向量。然后用文本向量去预测标签。当类别不多的时候,就是最最简单的softmax。当标签数量巨大的时候,就是要用到hierarchical softmax了。由于这个文章除了词向量还引入了ngram向量,ngram的数量非常大,会导致参数很多。所以这里使用了哈希桶,会可能把几个ngram映射到同一个向量。这样会大大的节省内存
word2vec和fasttext的对比:
word2vec对局部上下文中的单词的词向量取平均,预测中心词;fasttext对整个句子(或是文档)的单词的词向量取平均,预测标签。
word2vec中不使用正常的softmax,因为要预测的单词实在是太多了。word2vec中可以使用hierarchical softmax或是negative sampling。fasttext中当标签数量不多的时候使用正常的softmax,在标签数量很多的时候用hierarchical softmax。fasttext中不会使用negative sampling是因为negative sampling得到的不是严格的概率。
补充知识:
Negative log-likelihood function
词袋模型与Hash-Trick
代码:
After embed each word in the sentence, this word representations are then averaged into a text representation, which is in turn fed to a linear classifier.
It use softmax function to compute the probability distribution over the predefined classes.
Then cross entropy is used to compute loss.
Bag of word representation does not consider word order.
In order to take account of word order, n-gram features is used to capture some partial information about the local word order
When the number of classes is large, computing the linear classifier is computational expensive. So it use hierarchical softmax to speed training process.
use bi-gram and/or tri-gram
use NCE loss to speed us softmax computation(not use hierarchy softmax as original paper)
训练模型
1.load data(X:list of lint,y:int).
2.create session.
3.feed data.
4.training
(5.validation)
(6.prediction)