生产中出现的问题
问题 1:CoreDNS生产案:pod出现dns解析大量失败的问题
CoreDNS 5分钟内NXDOMAIN响应百分比大于50% k8s.coredns.response[baidu,172.22.82.25:9153,NXDOMAIN]
是coredns的172.22.82.25的这个pod出现dns解析大量失败的问题。(解析成功的日志是NOERROR,解析失败是:NXDMAIN)
分析
首先是查看这个coredns pod的日志:
1 [root@iZbp16er8wkobo2a165ekzZ ~]# kubectl get pods -n kube-system -o wide | grep coredns |grep 172.22.82.25 2 coredns-57dc86754b-9schh 1/1 Running 0 17d 172.22.82.25 cn-hangzhou.xxx.xxx.xxx.xxx[root@iZbp16er8wkobo2a165ekzZ ~]# kubectl logs -n kube-system coredns-57dc86754b-9schh | tail -10 3 2020-03-05T13:06:29.745Z [INFO] 172.22.0.66:54106 - 24311 "A IN metrics.cn-hangzhou.aliyuncs.com. udp 50 false 512" NOERROR qr,rd,ra 190 0.00003395s 4 2020-03-05T13:06:29.745Z [INFO] 172.22.0.66:56730 - 20278 "AAAA IN metrics.cn-hangzhou.aliyuncs.com. udp 50 false 512" NOERROR qr,rd,ra 232 0.000072002s 5 2020-03-05T13:06:29.748Z [INFO] 172.22.0.66:41047 - 53211 "AAAA IN metrics.cn-hangzhou.aliyuncs.com.kube-system.svc.cluster.local. udp 80 false 512" NXDOMAIN qr,rd,ra 173 0.00004196s 6 2020-03-05T13:06:29.748Z [INFO] 172.22.0.66:40581 - 40714 "A IN metrics.cn-hangzhou.aliyuncs.com.kube-system.svc.cluster.local. udp 80 false 512" NXDOMAIN qr,rd,ra 173 0.000037223s 7 2020-03-05T13:06:29.75Z [INFO] 172.22.0.66:41910 - 55424 "AAAA IN metrics.cn-hangzhou.aliyuncs.com.svc.cluster.local. udp 68 false 512" NXDOMAIN qr,rd,ra 161 0.000032467s 8 2020-03-05T13:06:29.75Z [INFO] 172.22.0.66:35103 - 22415 "A IN metrics.cn-hangzhou.aliyuncs.com.svc.cluster.local. udp 68 false 512" NXDOMAIN qr,rd,ra 161 0.000071336s 9 2020-03-05T13:06:29.752Z [INFO] 172.22.0.66:38912 - 45565 "AAAA IN metrics.cn-hangzhou.aliyuncs.com.cluster.local. udp 64 false 512" NXDOMAIN qr,rd,ra 157 0.000034122s 10 2020-03-05T13:06:29.752Z [INFO] 172.22.0.66:35033 - 24488 "A IN metrics.cn-hangzhou.aliyuncs.com.cluster.local. udp 64 false 512" NXDOMAIN qr,rd,ra 157 0.000040106s 11 2020-03-05T13:06:29.755Z [INFO] 172.22.0.66:50165 - 55872 "A IN metrics.cn-hangzhou.aliyuncs.com. udp 50 false 512" NOERROR qr,rd,ra 190 0.00004164s 12 2020-03-05T13:06:29.756Z [INFO] 172.22.0.66:37725 - 64492 "AAAA IN metrics.cn-hangzhou.aliyuncs.com. udp 50 false 512" NOERROR qr,rd,ra 232 0.000029312s
查看日志发现基本上都是172.22.0.66这个pod发起的baidu.com域名的解析,但是同一个pod解析同一个地址,有NXDOMAIN,又有NOERROR,于是尝试手动解析一下。分别去到coredns pod上做解析和172.22.0.66这个pod上手动解析,由于coredns pod镜像基本命令都不支持,无法通过命令登录:
[root@iZbp16er8wkobo2a165ekzZ ~]# kubectl exec -ti -n kube-system coredns-57dc86754b-9schh /bin/bash OCI runtime exec failed: exec failed: container_linux.go:344: starting container process caused "exec: \"/bin/bash\": stat /bin/bash: no such file or directory": unknown command terminated with exit code 126
所以使用nsenter工具通过网络命名空间的方式进入:
1 # docker inspect 9cddee6aa78d |grep Pid 2 "Pid": 13464, 3 "PidMode": "", 4 "PidsLimit": 0, 5 # nsenter -t 13464 --net bash 6 # ifconfig //这样看到的就是pod的IP了
手工解析发现每次都是解析正常的。原因是解析k8s集群外部的域名还会一次search集群内部的域。导致有3条解析失败的日志,最后没有匹配到集群内部的域而向外解析。可以通过统计集群外部域名和集群内部域名的解析日志验证:
1 [root@iZbp16er8wkobo2a165ekzZ ~]# kubectl logs -n kube-system coredns-57dc86754b-9schh | grep cvte-ms-mc4.redis.rds.aliyuncs.com | awk '{print $8}' | sort -rn |uniq -c 2 130 cvte-ms-mc4.redis.rds.aliyuncs.com. 3 [root@iZbp16er8wkobo2a165ekzZ ~]# kubectl logs -n kube-system coredns-57dc86754b-9schh | grep "172.22.0.66" |grep metrics.cn-hangzhou.aliyuncs.com | awk '{print $8}' | sort -rn |uniq -c 4 11572 metrics.cn-hangzhou.aliyuncs.com.svc.cluster.local. 5 11572 metrics.cn-hangzhou.aliyuncs.com.kube-system.svc.cluster.local. 6 11572 metrics.cn-hangzhou.aliyuncs.com.cluster.local. 7 11574 metrics.cn-hangzhou.aliyuncs.com.
查看172.22.0.66和coredns pod的/etc/resolv.conf文件分别如下:
//172.22.0.66的/etc/resolv.conf文件 [root@iZbp16er8wkobo2a165ekzZ ~]# kubectl exec -ti alicloud-monitor-controller-8bc847d8d-2t5c9 -n kube-system sh /go $ cat /etc/resolv.conf nameserver 172.23.0.10 search kube-system.svc.cluster.local svc.cluster.local cluster.local options ndots:5 /go $ //其他node节点pod的/etc/resolv.conf文件 app # cat /etc/resolv.conf nameserver 172.23.0.10 search project-1602-pro-pro-new.svc.cluster.local svc.cluster.local cluster.local options ndots:2 app #
发现文件中options选项的ndots参数配置不一样。ndots这个参数是做什么用的呢?
其中search kube-system.svc.cluster.local svc.cluster.local cluster.local和options ndots:5这两行配置表明,所有查询中,如果.的个数少于5个,则会根据search中配置的列表依次在对应域中先进行搜索,如果没有返回,则最后再直接查询域名本身。所以就会出现解析外部域名的时候会依次查询kube-system.svc.cluster.local,svc.cluster.local和cluster.local这三个域,多了3条NXDOMAIN的解析错误的记录。
解决
1)通过修改172.22.0.6的/etc/resolv.conf文件的ndots参数为2,来实现。(注意这需要确认业务是否不需要解析集群内部的域名)
问题 2:Pod偶尔存活检查失败
现象
Pod偶尔存活检查失败,导致Pod重启,业务偶尔连接异常。
排错
之前从未遇到这种情况,在自己测试环境,线上测试环境和预发布环境尝试复现也没有成功。
推断
环境流量较大,感觉跟连接数或并发量有关。
排查过程
之后在想起来线上初始化环境修改了3条内核参数,对比了一下预发布和测试环境的差异,最后发现是blacklog大小导致的,节点的 net.ipv4.tcp_max_syn_backlog 默认是 1024,如果短时间内并发新建 TCP 连接太多,SYN 队列就可能溢出,导致部分新连接无法建立。
解决
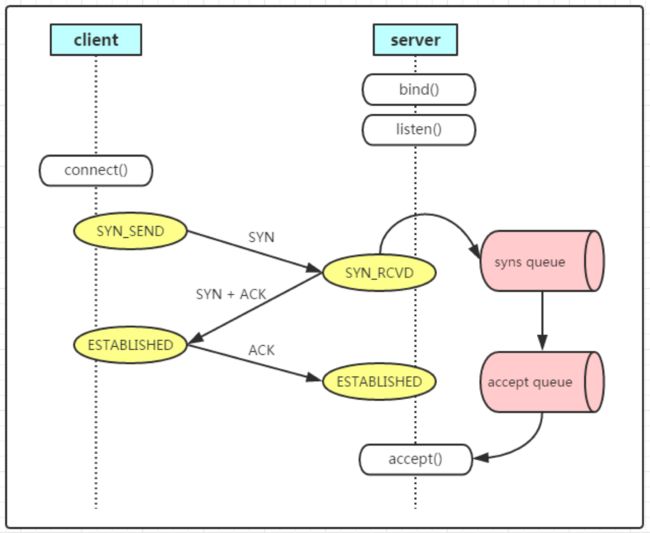
TCP 连接建立会经过三次握手,server 收到 SYN 后会将连接加入 SYN 队列,当收到最后一个 ACK 后连接建立,这时会将连接从 SYN 队列中移动到 ACCEPT 队列。在 SYN 队列中的连接都是没有建立完全的连接,处于半连接状态。如果 SYN 队列比较小,而短时间内并发新建的连接比较多,同时处于半连接状态的连接就多,SYN 队列就可能溢出,tcp_max_syn_backlog 可以控制 SYN 队列大小,用户节点的 backlog 大小默认是 1024,改成 8096 后就可以解决问题。