YOLO系列是目标检测领域里十分经典的结构,虽然目前已经出了很多更高质量更复杂的网络,但YOLO的结构依然可以给算法工程师们带来很多的启发。这3篇论文看下来,感觉像是一本调参说明书,教你如何使用各种trick提高手上的目标检测网络的准确率
来源:晓飞的算法工程笔记 公众号
YOLOv1

**论文: You Only Look Once:
Unified, Real-Time Object Detection**
Introduction

YOLO十分简单,一个网络同时对多个物体进行分类和定位,没有proposal的概念,是one-stage实时检测网络的里程碑,标准版在TitanX达到45 fps,快速版达到150fps,但精度不及当时的SOTA网络
Unified Detection

将输入分为$S\times S$的格子,如果GT的中心点在格子中,则格子负责该GT的预测:
- 每个格子预测$B$个bbox,每个bbox预测5个值: $x,y,w,h$和置信度,分别为中心点坐标和bbox的宽高,中心点坐标是格子边的相对值,宽高则是整图的相对值。置信度可以反应格子是否包含物体以及包含物体的概率,定义为${\Pr}(Object)*IOU_{pred}^{truth}$,无物体则为0,有则为IOU
- 每个格子预测$C$个类的条件概率$\Pr(Class_i|Object)$,注意这里按格子进行预测,没有按bbox进行预测

在测试时,将单独的bbox概率乘以类的条件概率得到最终类别的概率,综合了类别和位置的准确率
对于PASCAL VOC,设置$S=7$,$B=2$,共$C=20$类,最终预测$7\times 7\times (2\times 5 + 20)$数据
Network Design

主干网络共24层卷积加2个全连接层,没有类似于inception module的旁路模块,而是在$3\times 3$卷积后接$1\times 1$卷积进行降维。另外,fast YOLO的网络降为9层
Training
骨干网络前20层接average-pooling层和全连接层进行ImageNet预训练,检测网络训练将输入从$224\times 224$增加到$448\times 448$,最后一层使用ReLU,其它层使用leaky ReLU

损失函数如公式3,一个GT只对应一个bbox。由于训练时非目标很多,定位的训练样本较少,所以使用权重$\lambda_{coord}=5$和$\lambda_{noobj}=.5$来加大定位的训练粒度,包含3个部分:
- 第一部分为坐标回归,使用平方差损失,为了使得模型更关注小目标的小误差,而不是大目标的小误差,对宽高使用了平方根损失进行变相加权。这里$\Bbb{1}_{ij}^{obj}$指代当前bbox是否负责GT的预测,需要满足2个条件,首先GT的中心点在该bbox对应的格子中,其次该bbox要是对应的格子的$B$个box中与GT的IoU最大
- 第二部分为bbox置信度的回归,$\Bbb{1}_{ij}^{obj}$跟上述一样,$\Bbb{1}_{ij}^{noobj}$为非$\Bbb{1}_{ij}^{obj}$的bbox,由于负样本数量较多,所以给了个低权重。若有目标,$\hat{C}$实际为IOU,虽然很多实现直接取1
- 第三部分为分类置信度,相对于格子而言,$\Bbb{1}_i^{obj}$指代GT中心是否在格子中
Inference
对于PASCAL VOC,共预测98个bbox,用Non-maximal supression对结果进行处理
Experiments
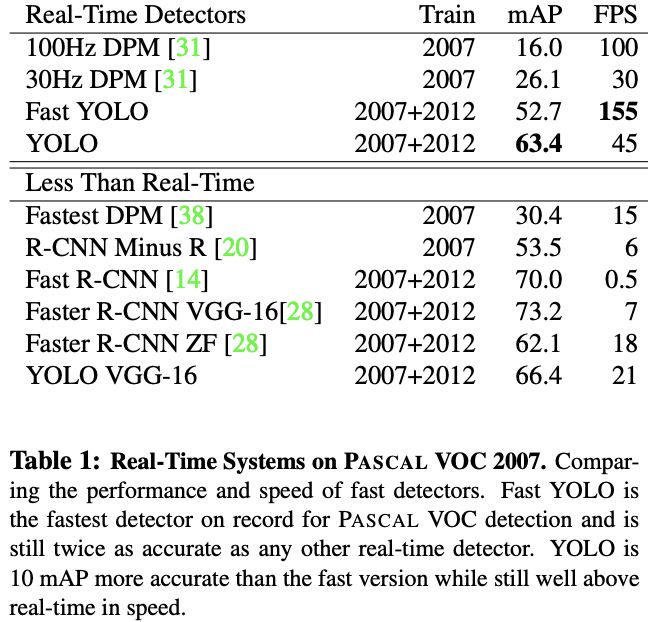
总结
开创性的one-stage detector,在卷积网络后面接两个全连接层进行定位和置信度的预测,并设计了一个新的轻量级主干网络,虽然准确率与SOTA有一定距离,但是模型的速度真的很快
作者提到了YOLO的几点局限性:
- 每个格子仅预测一个类别,两个框,对密集场景预测不好
- 对数据依赖强,不能泛化到不常见的宽高比物体中,下采样过多,导致特征过于粗糙
- 损失函数没有完成对大小物体进行区别对待,应该更关注小物体的误差,因为对IOU影响较大,定位错误是模型错误的主要来源
YOLOv2

论文: YOLO9000: Better, Faster, Stronger
Introduction
基于YOLOv1,YOLOv2加入了一系列当前比较流行的提升方法,一个更快更准的one-stage目标检测算法。此外,作者还结合hierarchical softmax提出YOLO9000,能进行9000类物体检测的通用网络。对于模型的介绍,分为Better/Faster/Stronger,分别介绍提升准确率的trick,网络加速的方法以及超多分类的实现
Better
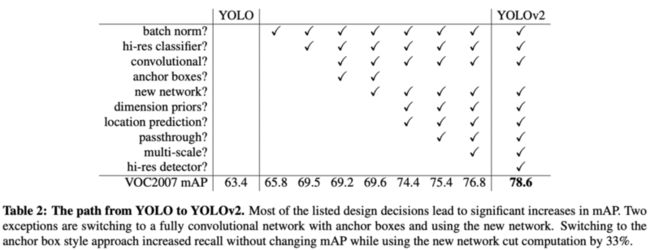
YOLOv1还是个相当navie的想法,因此作者在YOLOv2加入了大量提升准确率的方法,算是个认真思考后的完整网络吧,具体添加的方法如table 2
Batch Normalization
BN层能够很好地加速网络的收敛,加入BN层YOLO能提升2%mAP,同时可以丢弃dropout进行训练
High Resolution Classifier
原YOLO的主干网络使用$224\times 224$的输入进行预训练,然后直接使用$448\times 448$进行检测训练,这要求网络同时适应新像素和目标检测的学习。为了更平滑,论文在检测训练前先对主干网络进行$448\times 448$输入的10个epoch fine tune,这带来4%mAP提升
Convolutional With Anchor Boxes
YOLOv1直接预测bbox,参考Faster R-CNN使用预设的anchor达到了很好的效果,YOLOv2去掉全连接层并开始使用achor
首先去掉最后的池化层,使得结果保持高像素,修改输入分辨率为416来确保特征图是奇数,这样就能保证只有一个中心网格,便于预测大物体,最终的特征图为输入的1/32倍,即$13\times 13$。在加入anchor后,将预测的机制从绑定在格子转化为绑定在anchor上,每个anchor预测$C+5$个结果,objectness置信度预测IOU,class置信度预测分类的条件概率。使用anchor后准确率下降了,具体原因是输出的box多了,召回率提高了,相对的地准确率降低了
Dimension Clusters

目前anchor是手工设定的,这可能不是最优的设定,使用k-means来对训练集的box进行聚类,获得更准确率的预设anchor。聚类使用IOU作为距离计算,具体为$d(box, centroid) = 1-IOU(box, centroid)$,从图2可以看出,5个簇时性价比最高,也是YOLOv2使用的设定
Direct location prediction

使用achor后,YOLOv2的初期训练十分不稳定,主要来源于中心点$(x,y)$产生的误差,region proposal方法使用相对anchor宽高的比例来进行中心点的位移,由于没有约束,中心点可以在图的任何地方,导致初期训练不稳定
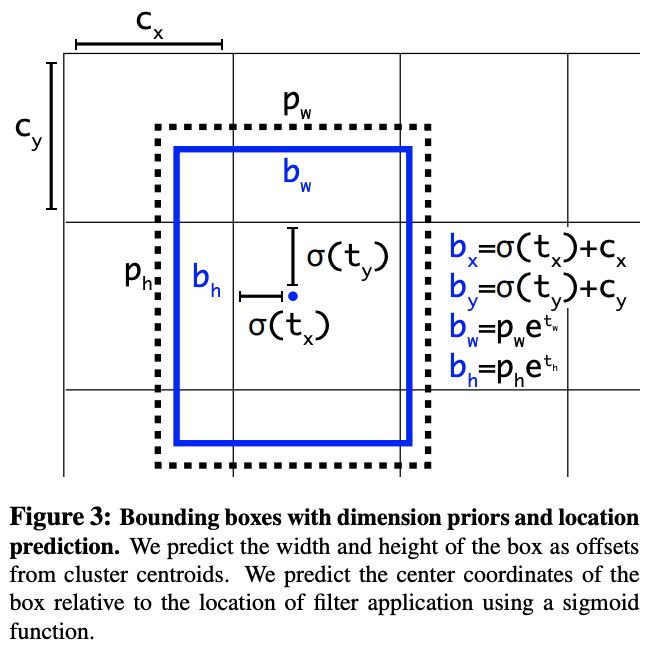
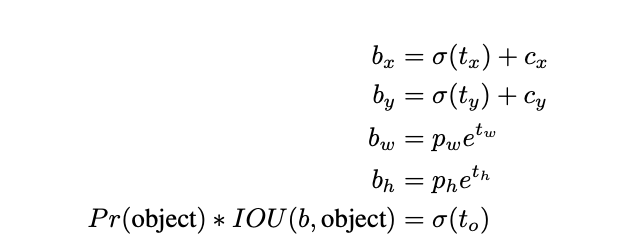
因此,YOLOv2继续沿用YOLO的策略,预测相对于格子的宽高的中心位置,使用逻辑回归来约束值在$[0,1]$区间,而宽高则改为相对于anchor宽高的比例。因此,每个格子预测5个bbox,每个bbox包含5个内容,中心点要加上格子左上角坐标。在约束了中心位置后,提升了5%mAP
Fine-Grained Features
最后的$13\times 13$特征图足够用来预测大目标,但需要更细粒度的特征来定位小目标,Faster R-CNN和SSD使用不同层的特征图进行预测,而YOLOv2则提出passthrough layer,将earlier layer的$26\times 26$特征进行隔点采样,将原来$26\times 26\times 512$的特征图采样为$13\times 13\times 2048$(即将特征图分成多个$4\times 4$的小网格,然后所有网格的1、2、3、4位置的值分别组合成新的特征图),然后跟最后的特征图concatenate到一起进行预测,这带来1%mAP提升
Multi-Scale Training
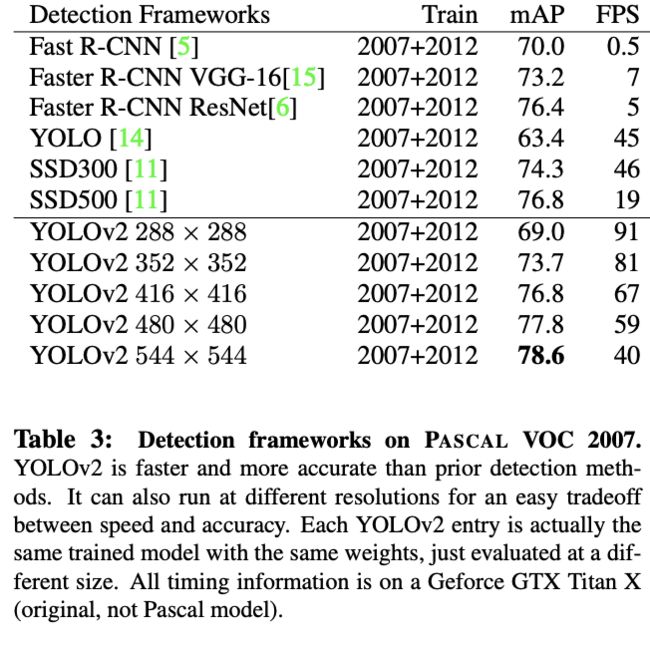
由于YOLOv2为全卷积网络,可以任意修改输入的大小,在训练时,每10个batch任意切换一次输入分辨率,候选分辨率为32的倍数,如$\{320, 352,...,608\}$。在实际使用时,可以用不同的分辨率来满足不同的准确率和速度的要求,结果如表3
Main Result

Faster
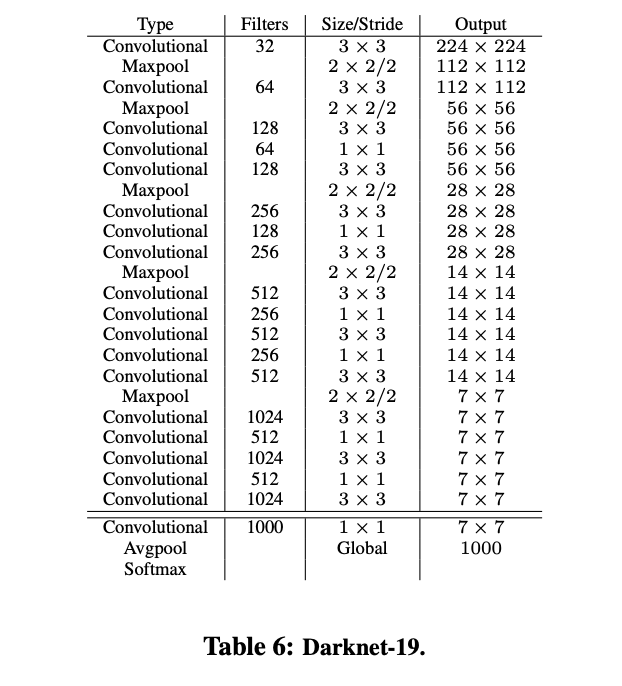
为了加速,YOLOv2使用了新的主干网络Darknet-19,包含19层卷积和5个池化层,使用$1\times 1$卷积来对$3\times 3$卷积结果进行压缩,使用BN层来稳定训练,加速收敛以及正则化模型,使用全局池化来进行预测
Stronger
YOLOv2提出联合分类数据和检测数据进行训练,得出超多分类的模型
Hierarchical classification
ImangeNet和COCO的标签粒度是不一样的,为此,要对数据进行多标签标注,类似于种属科目纲门界的分法,构建WordTree


比如诺福克梗等猎犬都属于猎犬节点的下级分类,而诺福克梗的分类概率则为根节点到当前节点的路径上的所有节点概率的乘积
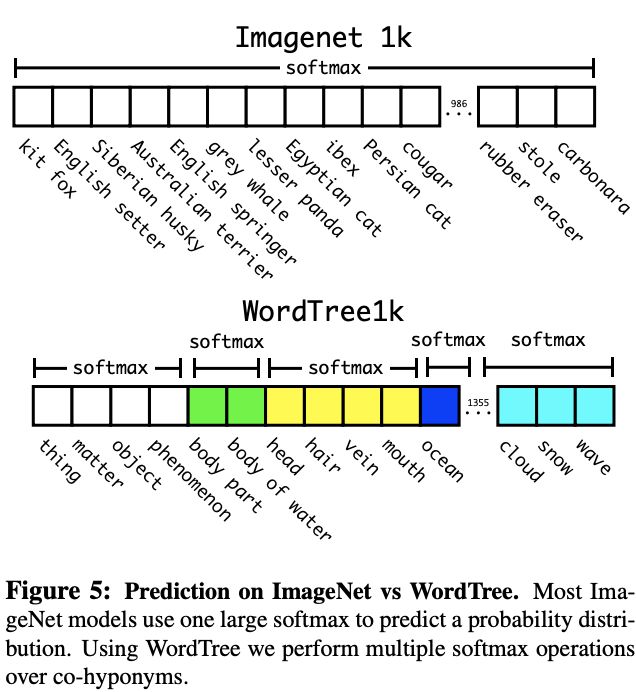
ImageNet1k经过重新标注后,WordTree共1369个节点,每个同级分类使用一个softmax,基于WordTree重新训练Darknet-19,达到71.9% top-1准确率,仅仅降低了一点。从结果来看,大多数错误都是细粒度层级的错误,比如错误的结果也认为当前物体是狗,但是分错了狗的品种,所以这种层级分类应该是有利于引导特征的提取
Dataset combination with WordTree

将COCO和ImageNet进行合并,得到图6的WordTree,共9418类
Joint classification and detection
由于ImageNet数据过多,对COCO数据集进行4倍过采样。当输入图片是检测数据时,进行全损失函数的反向传播,其中分类的反向传播仅限于GT的标签层级及以上。而当输入图片是分类数据时,则取置信度最高($\ge .3$)的bbox进行损失函数的分类部分的反向传播
Training

YOLOv2跟YOLOv1类似,先将GT根据中心点赋予对应的格子IOU最大的bbox(这里网上有的实现用为IOU最大的anchor,作者的实现为bbox,待考证),损失计算包含3部分:
- 对应格子中最大的bbox的IOU小于thresh的bbox,只回归objectness,导向0
- 对于有GT的bbox,回归所有loss
- 对于所有的box,在前12800次迭代回归其与预设框的坐标,这是由于本身的坐标回归就很少,在前期让预测先拟合anchor来稳定训练
总结
YOLOv2在YOLO的基础上融合了一些比较work的方法,进行了大量的改进:
- 加入Batch Normalization
- 为主干网络训练进行高分辨率的fine tune
- 加入anchor box机制
- 使用k-mean来辅助anchor的设定
- 沿用YOLO的方法对anchor中心点进行修正
- 使用passthrough layer,融合低维度特征
- 使用multi-scale trainning提高准确率
- 提出darknet-19来加速
- 使用hierarchical classification进行超多目标的分类
YOLOv3

论文: YOLOv3: An Incremental Improvement
Introduction
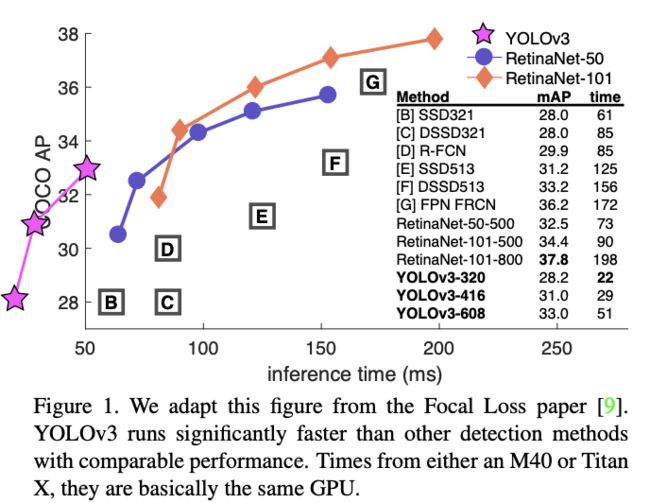
YOLOv3的发表不是一篇完整的论文,是作者把手上的一些小工作进行整理,主要是将一些有效的trick加进去
Bounding Box Prediction

YOLOv3的整体坐标回归跟YOLOv2类似,依然用逻辑回归函数预测anchor的objectness,每个GT只赋予一个IOU最大的anchor产生全部损失(论文写的是bounding box prior不是bounding box,即预设的框,这样可以找到计算的level,大致作用跟原来差不多,但作者实现用的bounding box,待考证),其它的与GT的IOU大于0.5的anchor不产生任何损失,而与GT的IOU小于0.5的anchor则只产生objectness loss
Class Prediction
为了支持多标签,使用独立的逻辑分类进行class prediction,使用二值交叉熵损失函数进行训练
Predictions Across Scales
YOLOv3在3个不同的特征图进行bbox预测,这些特征图用类似FPN的方法,对高层特征进行上采用然后和低层concatenate,每层特征图有特定使用的3个anchor,先用几个卷积层对合并特征图进行处理,然后预测一个3-d tensor,分别包含位置信息,objectness信息和类别信息。例如COCO中,tensor的大小$N\times N\times [3 * (4+1+80)]$的数据,即channel为255
Feature Extractor

YOLOv3提出了新主干网络Darknet-53,将DarkNet-19和残差网络进行融合,在之前的$3\times 3$卷积和$1\times 1$卷积组合基础上加上一个shortcut连接

DarkNet-53准确率跟目前的SOTA分类网络差不多,但是速度快很多
Main Result

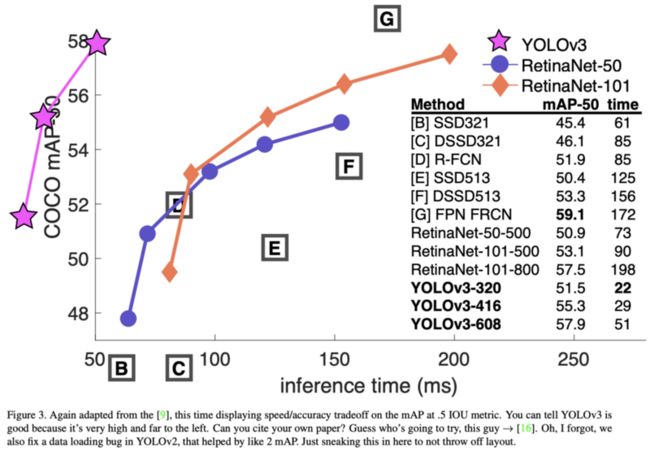
总结
YOLOv3是个非正式的版本,作者的改进比较少,主要是融合一些用于提高准确率的方法:
- 将类别置信度预测改为逻辑独立分类
- 结合FPN的结构进行多level的预测
- 提出Darknet-53,将shortcut连接加入到网络中
Conclusion
YOLO系列是目标检测领域里十分经典的结构,虽然目前已经出了很多更高质量更复杂的网络,但YOLO的结构依然可以给算法工程师们带来很多的启发。这3篇论文看下来,感觉像是一本调参说明书,教你如何提高手上的目标检测网络的准确率,各种trick,十分值得研读
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
