- Beautiful Soup
- 说明文档
- 英文说明文档
- 中文说明文档
- HTML 简介
- 造个简单的网页
- 标记码
- 标记码的格式要求
- 标记码分类
- 围堵标记
- 标记码解析
- 引入 Beautiful Soup 库
- 解析器
- 基本元素
- Tag
- Name
- Attributes
- NavigableString
- HTML 信息遍历
- 下行遍历
- contents
- children
- descendants
- 上行遍历
- 平行遍历
- next_siblings
- previous_siblings
- 下行遍历
- 信息提取
- find 方法
- name
- attrs
- recursive
- string
- 拓展方法
- find 方法
- 实例:中国大学排名定向爬虫
- 实例解析
- 引入库
- 获取网页源码
- BeautifulSoup 提取信息
- 打印数据
- 主函数
- 运行结果
Beautiful Soup
"Beautiful Soup parses anything you give it, and does the tree traversal stuff for you. "Beautiful Soup 是一个优秀的 HTML 页面解析的第三方库,正如官网所说"Since 2004, it's been saving programmers hours or days of work on quick-turnaround screen scraping projects."Beautiful Soup 能够对你爬取来的数据进行解析、遍历、维护,使得“汤”能够成为一锅“好汤”,是 python 网络爬虫的必学第三方库之一。
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。

说明文档
英文说明文档
Beautiful Soup
Beautiful Soup Documentation
中文说明文档
Beautiful Soup 4.4.0 文档
Beautiful Soup 4.4.0 文档
HTML 简介
HTML语言是超文本标记语言(HyperText Markup Language)的缩写,是Web上的专用表述语言。HTML 运行在浏览器上,由浏览器来解析,它包括一系列标签.通过这些标签可以将网络上的文档格式统一,使分散的Internet资源连接为一个逻辑整体。HTML可以规定网页中信息陈列的格式,指定需要显示的图片,嵌入其他浏览器支持的描述型语言,以及指定超文本链接对象。
HTML语言的源文件是纯文本文件,所以,可以使用任何文本编辑器进行编辑,例如我们常用的记事本。需要注意的是,HTML不是程序设计语言,而是一种标识语言,需要学习的内容是各种标记的用法。
造个简单的网页
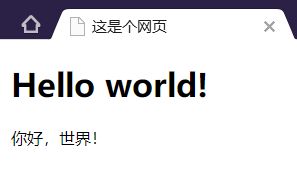
HTML语言并不是程序设计语言,我只是想利用HTML语言造一个显示“Hello world!”的网页。
这是个网页
Hello world!
你好,世界!
保存文件,后缀名修改为“.html”,打开网页。
标记码
HTML语言使用的描述性标记符被称为标记码,用来指明文档的不同内容。通过标记码,能够把HTML文档划分成不同的逻辑部分或结构,如段落、标题等。可以类比于Markdown语法,标记码描述了文档的结构,向浏览器提供该文档的格式化信息,以传送文档的外观特性。
标记码的格式要求
- 任何标记码皆由“<”及“>”所围住;
- 标记名与“<”和“>”号之间不能留有空白字符;
- 如果标记需要加上参数,参数只可加于起始标记中;
- 在起始标记之标记名前加上符号“/”表示为其终结标记;
- 标记字母不区分大小写。
标记码分类
标记码按形态分为围堵标记与空标记。
围堵标记
也称为双标记或双标签,以起始标记及终结标记将文字围住,令其达到预期显示效果。语法为:
<标签名称>内容
标记码解析
| 符号 | 功能 |
|---|---|
| < !DOCTYPE html > | 声明为 HTML5 文档 |
| < html >…< /html > | 是 HTML 页面的根元素,定义HTML文档的起始 |
| < head >…< head > | 文件头,代码区间包含文档的元数据 |
| < title >…< /title > | 代码区间定义文档的标题 |
| < body >…< body > | 包含了可见的页面内容,定义文档主体信息 |
| < h1 >…< h1 > | 代码区间定义一个大标题 |
| < p >…< p > | 代码区间定义一个段落 |
- HTML5是HTML最新的修订版本,2014年10月由万维网联盟(W3C)完成标准制定。HTML5的设计目的是为了在移动设备上支持多媒体。
引入 Beautiful Soup 库
python123是北京理工大学的一个 python 的一个学习平台,我使用该平台提供的 demo 网页来进行测试。打开交互式解释器:
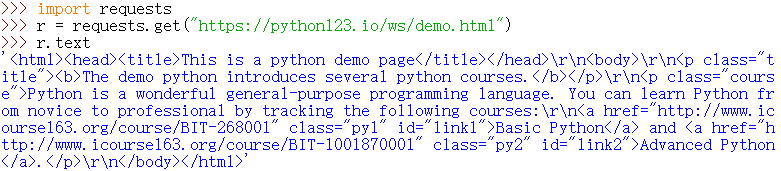
现在我们已经使用 requests 库获得了该网站的原码了,由于没有层次的体现,我们很难去阅读,因此我们引入 Beautiful Soup 库来处理。
from bs4 import BeautifulSoup
demo = r.text
soup = BeautifulSoup(demo,'html.parser')
把处理好的原码输出出来看看,使用 prettify() 方法可以输出整理之后的 HTML 编码:
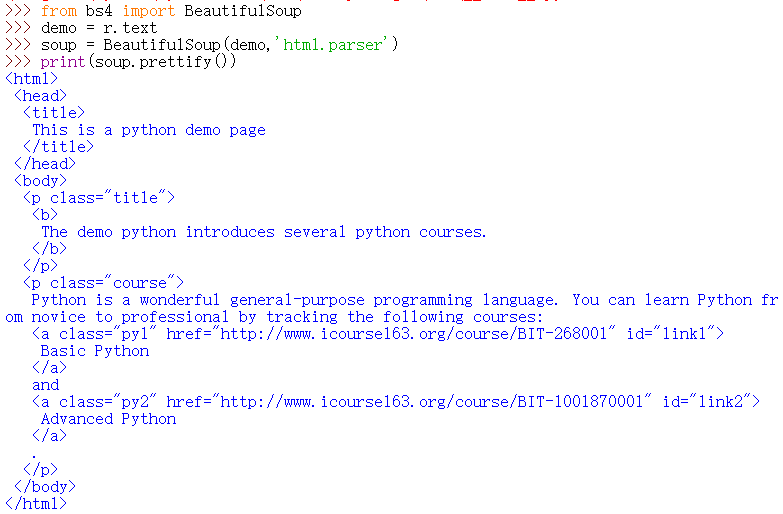
解析器
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,主要解释器如下:
| 解析器 | 样例 | 优点 | 缺点 |
|---|---|---|---|
| bs4的HTML 解析器 | BeautifulSoup(markup, "html.parser") | Python的内置标准库 执行速度适中 文档容错能力强 |
部分版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, "lxml") | 速度快 文档容错能力强 |
需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, ["lxml-xml"]) BeautifulSoup(markup, "xml") |
速度快 唯一支持XML的解析器 |
需要安装C语言库 |
| html5lib 解析器 | BeautifulSoup(markup, "html5lib") | 最好的容错性 以浏览器的方式解析文档 生成HTML5格式的文档 |
速度慢 不依赖外部扩展 |
- 说明文档推荐使用lxml作为解析器,因为效率更高.。在Python2.7.3之前的版本和Python3中3.2.2之前的版本,必须安装lxml或html5lib, 因为那些Python版本的标准库中内置的HTML解析方法不够稳定。
基本元素
BeautifulSoup 类有 5 个基本元素:
| 基本元素 | 说明 |
|---|---|
| Tag | 标签,最基本的信息组织单元,分别用<>和标明开头和结尾 |
| Name | 标签的名字,< p >…< /p >的名字是'p',格式: .name |
| Attributes | 标签的属性,字典形式组织,格式: .attrs |
| NavigableString | 标签内非属性字符串,<>…中字符串,格式: .string |
| Comment | 标签内字符串的注释部分,一种特殊的Comment类型 |
我们每种元素都试着查看一下。
Tag

- 任何 HTML 语法中的标签可以使用 soup. 进行获取,当 HTML 文档中存在多个相同 对应内容时,soup. 仅返回第一个标签。
Name
Tag 对象与 XML 或 HTML 原生文档中的 tag 相同。

Attributes
每个 tag 都有自己的名字,通过 .name 来获取,如果改变了 tag 的 name,那将影响所有通过当前 Beautiful Soup 对象生成的HTML文档。

NavigableString
一个 tag 可能有很多个属性. tag 有一个 “class” 的属性,值为 “boldest” . tag 的属性的操作方法与字典相同:

HTML 信息遍历
由于 HTML 通过了标记码划分了所属关系,是一个树结构。通过数据结构中的知识可知,树结构按照一定的规则可以对其进行遍历,我们可以使用内置的方法实现。
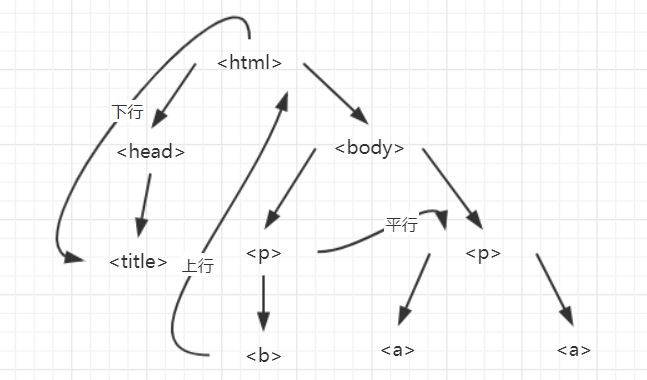
下行遍历
| 属性 | 说明 |
|---|---|
| .contents | 子节点的列表,将 所有儿子节点存入列表 |
| .children | 子节点的迭代类型,与.contents类似,用于循环遍历儿子节点 |
| .descendants | 子孙节点的迭代类型,包含所有子孙节点,用于循环遍历 |
contents
for child in soup.body.contents:
print(child)
例如启动交互式解释器:

children
for child in soup.body.children:
print(child)
例如启动交互式解释器:

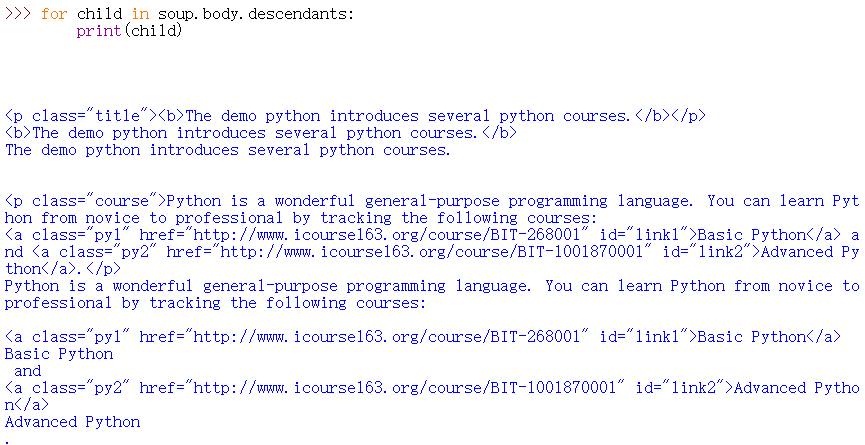
descendants
for child in soup.body.descendants:
print(child)
例如启动交互式解释器:
上行遍历
| 属性 | 说明 |
|---|---|
| .parent | 节点的父亲标签 |
| .parents | 节点先辈标签的迭代类型,用于循环遍历先辈节点 |
例如启动交互式解释器:

可以用如下代码进行操作:
for parent in soup.a.parents:
if parent is None:
print(parent)
else:
print(parent.name)
例如启动交互式解释器:

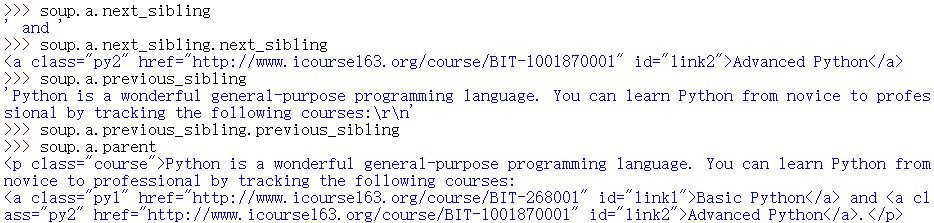
平行遍历
| 属性 | 说明 |
|---|---|
| .next_sibling | 返回按照HTML文本顺序的下一个平行节点标签 |
| .previous_sibling | 返回按照HTML文本顺序的上一个平行节点标签 |
| .next_siblings | 迭代类型,返回按照HTML文本顺序的后续所有平行节点标签 |
| .previous_siblings | 迭代类型,返回按照HTML文本顺序的前续所有平行节点标签 |
平行遍历发生在同一个父节点下的各节点间,例如启动交互式解释器:
next_siblings
for sibling in soup.a.next_sibling:
print(sibling)
例如启动交互式解释器:

previous_siblings
for sibling in soup.a.previous_sibling:
print(sibling)
信息提取
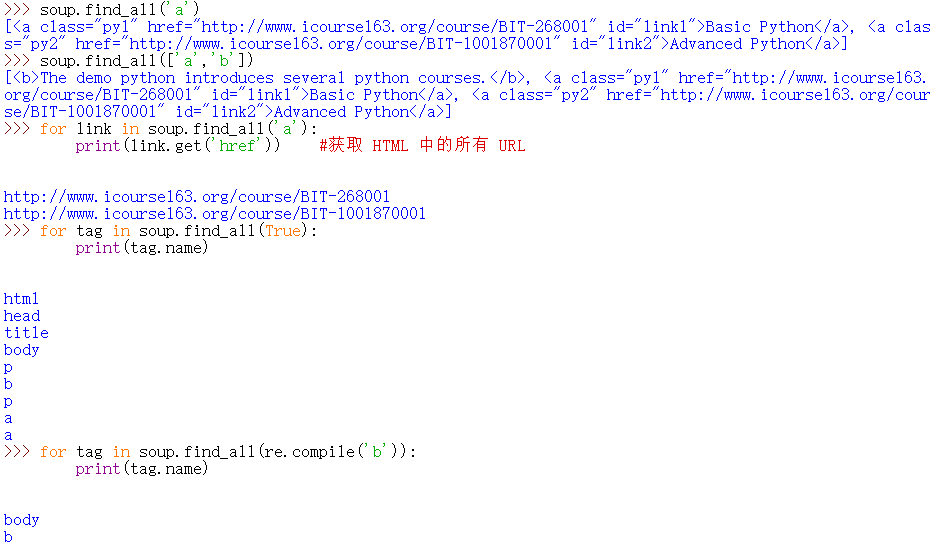
find 方法
方法将返回一个列表类型,存储查找的结果。
<>.find_all(name, attrs, recursive, string, **kwargs)
| 参数 | 说明 |
|---|---|
| name | 对标签名称的检索字符串 |
| attrs | 对标签属性值的检索字符串,可标注属性检索 |
| recursive | 是否对子孙全部检索,默认True |
| string | <>…中字符串区域的检索字符串 |
name
启动交互式解释器:
attrs
启动交互式解释器:

recursive
启动交互式解释器:

string
启动交互式解释器:

拓展方法
| 方法 | 说明 |
|---|---|
| <>.find() | 搜索且只返回一个结果,同.find_all()参数 |
| <>.find_parents() | 在先辈节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_parent() | 在先辈节点中返回一个结果,同.find()参数 |
| <>.find_next_siblings() | 在后续平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_next_sibling() | 在后续平行节点中返回一个结果,同.find()参数 |
| <>.find_previous_siblings() | 在前序平行节点中搜索,返回列表类型,同.find_all()参数 |
| <>.find_previous_sibling() | 在前序平行节点中返回一个结果,同.find()参数 |
实例:中国大学排名定向爬虫
实例解析
从大学排名 URL 链接中提取大学排名信息并输出排名,大学名称,总分的信息,实现的是定向爬虫,即仅对输入 URL 进行爬取,不扩展爬取其他 URL。我们选择最好大学网的软科排名进行爬虫,由于这个网页的信息是静态存放于网页源码中的,因此可以用 Requests 和 Beautiful Soup 库进行爬取。
首先要礼貌地查看下 robots.txt 文件,没有,那就可以放心地爬。
引入库
import requests
from bs4 import BeautifulSoup
import bs4
获取网页源码
def getHTMLText(url):
try:
r = requests.get(url, timeout=30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
BeautifulSoup 提取信息
def fillUnivList(a_list, html):
soup = BeautifulSoup(html, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
a_list.append([tds[0].string, tds[1].string, tds[3].string])
打印数据
def printUnivList(ulist, num):
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("排名","学校名称","总分",chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
主函数
def main():
uinfo = []
url = 'http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html'
html = getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20)
运行结果
