2018-05-14
概述
R语言作为强大的数据分析工具,在研究领域发挥重要的作用.在生态学研究中,越来越多的研究采用R语言做为数据分析的工具,在这里整理常用生态学数据分析代码,供参考.
物种组成柱形图
#载入相应的包
#如果未安装,请按下行代码安装
#install.package(c("ggplot2","reshape2")
library(ggplot2)
library(reshape2)
#设置工作路径
setwd("/home/cesar/Ecology_R/20180514/")
#载入数据,本数据是鱼类物种组成的绝对值数据,在excel中保存为csv格式.
taxa<-read.csv("taxa_relative.csv",row.names = 1,header = T)
#将文件中的NA值改为0
taxa[is.na(taxa)]<-0
#将数据中的种类根据数量的多少进行排序
taxa<-taxa[order(rowSums(taxa),decreasing = T),]
#N值代表选择数量排前10的物种,将剩下的物种合并成其他
N<-10
taxa_list<-rownames(taxa)[1:N]
new_x<-rbind(taxa[rownames(taxa)%in% taxa_list,],
其他=rowSums(taxa[!rownames(taxa) %in% taxa_list,]))
#合并数据
datm<-melt(cbind(new_x,Taxonomy=rownames(new_x)),id.vars = c('Taxonomy'))
#作图
ggplot(datm,aes(x=variable,y=value,fill=Taxonomy))+
xlab("")+
ylab("")+
geom_bar(position = "fill",stat = 'identity',width = 0.8)
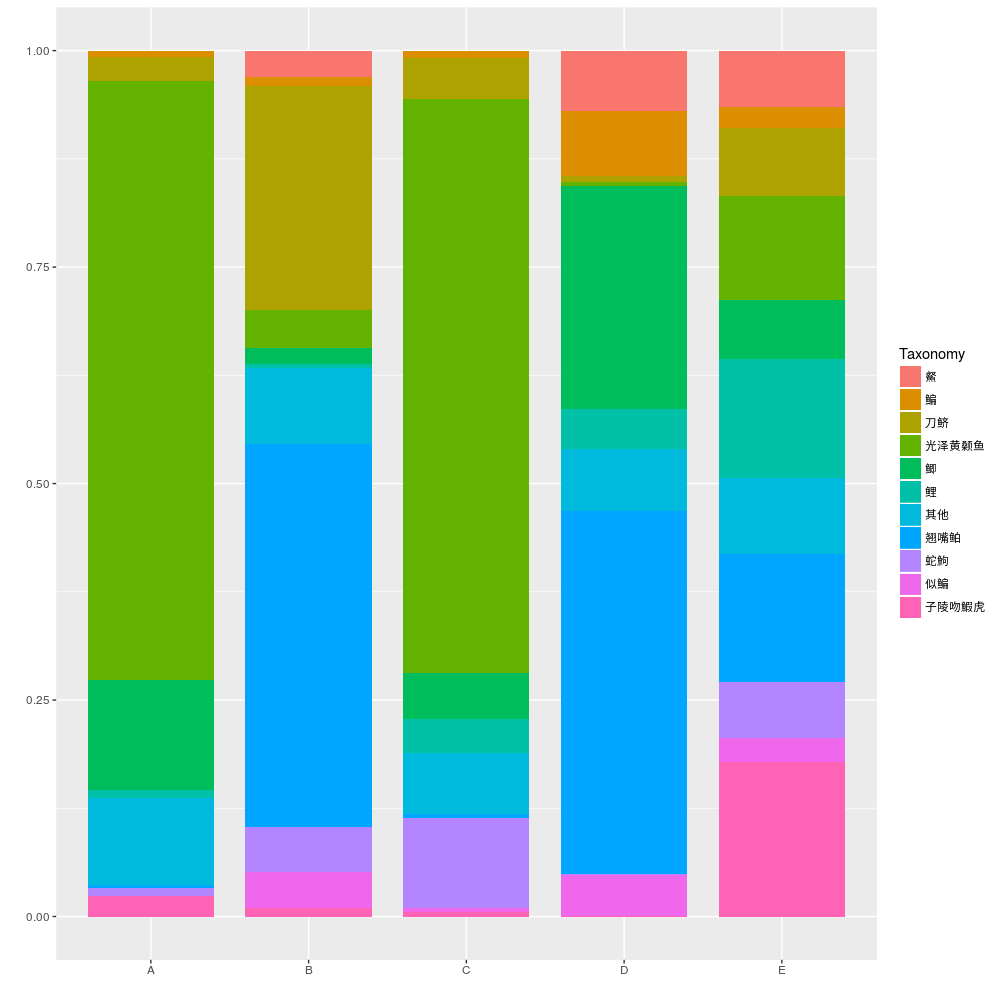
Taxaplot.png
聚类分析
#清理旧数据
rm(list = ls())
#设置工作路径
setwd("/home/cesar/Ecology_R/20180514/")
#载入工作包
library(ggplot2)
library(ggdendro)
library(vegan)
#读取数据
taxa<-read.csv("taxa_relative.csv",header = T,row.names = 1)
taxa[is.na(taxa)]<-0
#采用Bray Curtis方法,如需要更换其他方法,可在method参数中调整
beta_bray<-vegdist(t(taxa),method="bray")
#建树
hc<-hclust(beta_bray)
hcd <- as.dendrogram(hc)
dend_data <- dendro_data(hcd, type = "rectangle")
#绘图
ggplot(dend_data$segments) +
theme_dendro()+
scale_x_discrete(expand = c(0,1))+
geom_segment(aes(x = x, y = y, xend = xend, yend = yend))+
geom_text(data = dend_data$labels, aes(x, y, label = label),
size = 5,check_overlap = T,
nudge_y = -0.02)
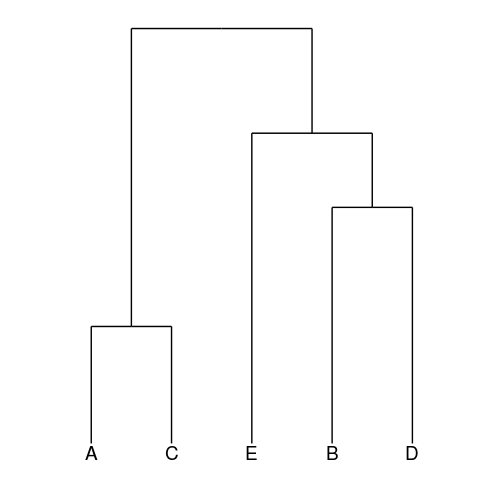
Cluster_tree.png
α多样性分析
rm(list = ls())
setwd("/home/cesar/Ecology_R/20180514/")
library(phyloseq)
library(ggplot2)
#α多样性需要物种的绝对值,同时载入一个关于样品分组的文件
taxa<-read.csv("taxa.csv",header = T,row.names = 1)
meta<-read.csv("map.csv",header = T,row.names = 1)
#将数据制成phyloseq的格式
TAXA<-otu_table(taxa,taxa_are_rows = T)
SAD<-sample_data(meta)
phy<-phyloseq(TAXA,SAD)
#绘图,measures可以选择不同的方法
plot_richness(phy,x="Group",color="Month",measures=c("Observed", "Chao1", "ACE", "Shannon", "Simpson", "InvSimpson", "Fisher"))
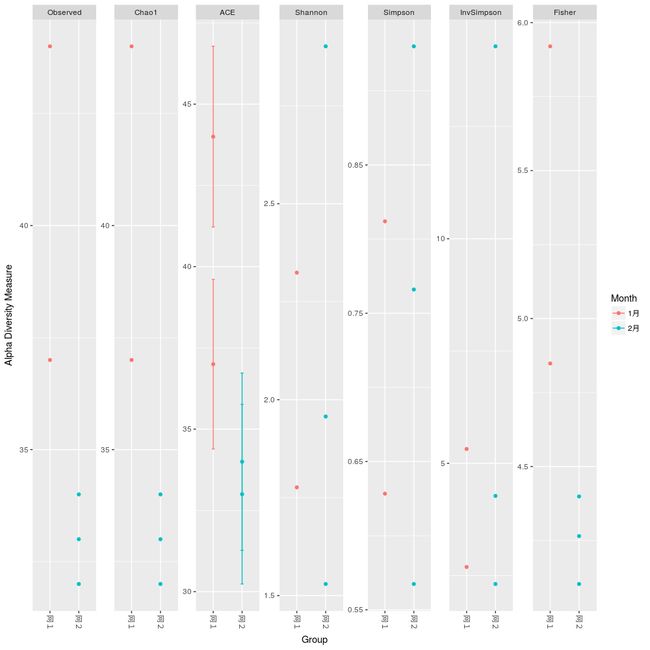
alpha_diversity.png
PCA分析(主成分分析)
library(ggbiplot)
setwd("/home/cesar/Ecology_R/20180514/")
#读取数据
taxa<-read.csv("taxa_relative2.csv",row.names = 1,header = T)
meta<-read.csv("map2.csv",header = T,row.names = 1)
taxa<-t(taxa)
taxa[is.na(taxa)]<-0
#计算PCA值
pca<-prcomp(taxa,scale. = T)
#作图
ggbiplot(pca, obs.scale = 2, var.scale = 1,var.axes = F,
groups = meta$Group, ellipse = TRUE, circle = TRUE) +
scale_color_discrete(name = '') +
theme(legend.direction = 'horizontal', legend.position = 'top')
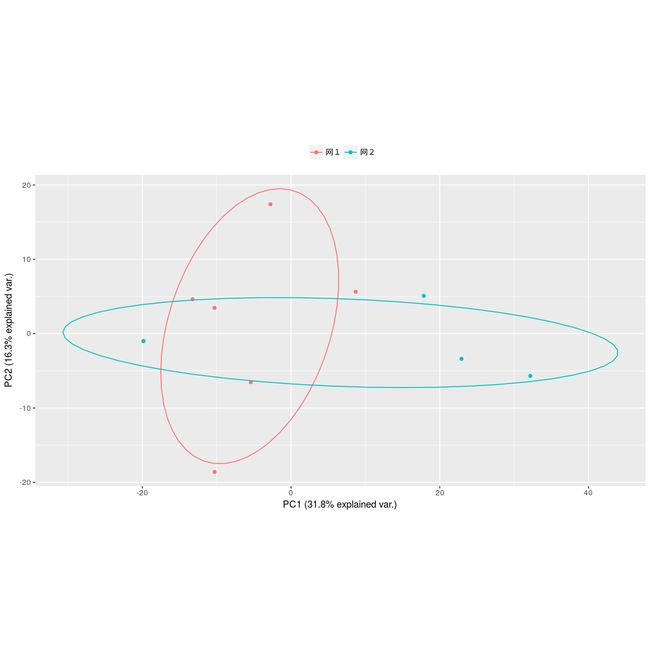
PCA.png