1、Introduction
(1)神经网络的几个优化方向:prune redundant connection, use low-precision or quantized weights, use more efficient architectures
(2)神经网络中的redundancy :layer-by-layer的连接模式迫使网络在整个网络中复制来自早期层的特性,DenseNet架构通过直接将每一层和它前面的层相连接来alleviates the need for feature replication 。尽管更加efficient,但当早期的feature在后来的层中不需要时,密集的连接会导致冗余。
(3)与之前的剪枝方法相比,本文的方法在训练过程中自动学习一个稀疏化的网络,并生成一个规则连接模式,该模式可以使用组卷积有效地实现。
2、Related work and background
2.1. Related work
(1)weights pruning and quantization:细粒度(Fine-grained) 的pruning可以取得更高的稀疏性,但是它需要存储很多索引,并且依赖专门的硬件加速;粗粒度(coarse-grained)的剪枝,比如filter-level剪枝,取得的稀疏性比较低,但是最终的网络结构更加规整,便于高效地实现。CondenseNets在训练的最初阶段就进行weight pruning,相比于filter-level级的剪枝方法可以达到更高的稀疏性,因此在sparsity和regularity之间达到一个sweet spot。
(2)Efficient network architectures:MobileNet、ShuffleNet等,主要特点是使用了depth-wise separable卷积,这些网络的一个实际缺点是深度可分卷积在大多数深度平台上还没有得到有效的实现(A practical downside of these networks is depth-wise separable convolutions are not (yet) efficiently implemented in most deeplearning platforms.)。CondenseNet 使用well-supported 分组卷积,可以在实际中取得更高的计算效率。
2.2. DenseNet
每一层产生k个特征,其中k被称为网络的增长率。DenseNets的独特之处在于,the input of each layer is a concatenation of all feature maps generated by all preceding layers within the same dense block 每个层执行一系列连续的转换:先用1*1卷积降通道,再用3*3卷积生成k个通道 ,如下图左所示。
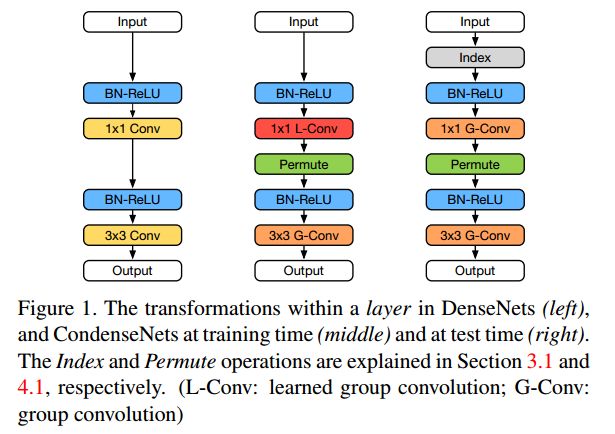
2.3 Group convolution
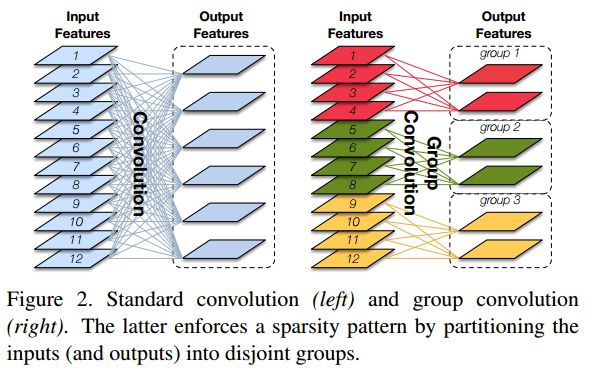
computational cost: R*O->R*O/G R:input channels O:output channels
3、CondenseNets
在1*1卷积层采用分组卷积会导致准确率的大幅下降:1)1*1卷积层的输入有一个intrinsic的order;2)1*1卷积层的输入更加diverse。在进行分组卷积前进行随机重排(random permutation)可以减少准确率的下降,但是还是使得DenseNets的准确率低于计算成本相当的较小的DenseNets。为了解决这个问题,我们开发了一种在训练过程中自动学习输入特征分组的方法(learned group convolution),这种方法允许每个filter group选择自己的一组最相关的输入。
3.1. Learned group convolution
包括condensing(压缩) stages和optimization stage. 在压缩阶段,使用正则化进行固定次数的迭代,剪掉幅值较小的不重要的filters。在优化阶段,对分组后的filters进行再次学 习。

(1)滤波器分组(Filter groups)

![]()
(2)压缩(weight pruning)

为了减少weight pruning对准确率的负面影响,L1正则化经常被用来诱导稀疏性。
(3)组套索

(4)压缩因子

(5)压缩流程

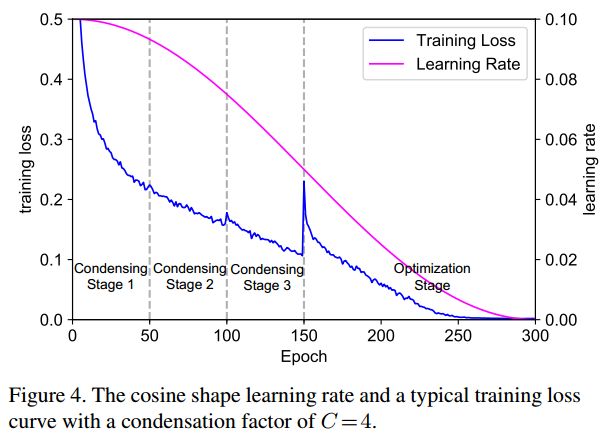
(6)索引层

3.2. 架构设计

4、Experiments
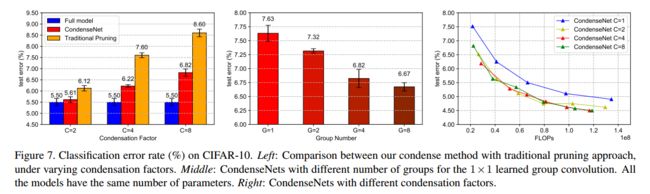
(1)CIFAR10
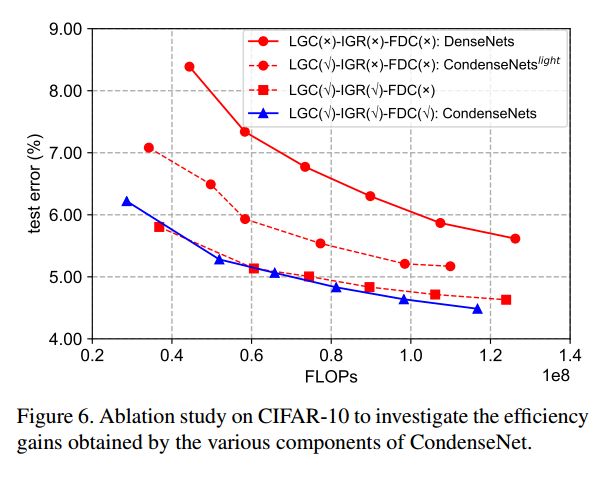
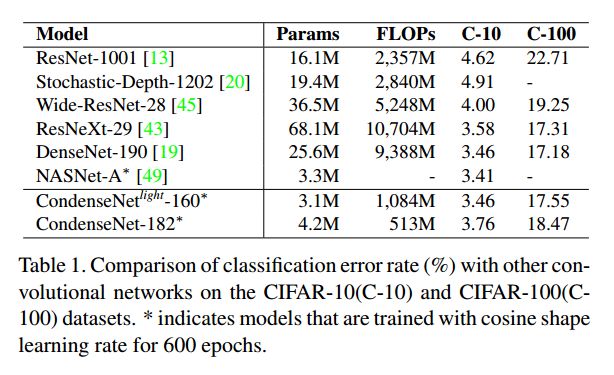
(2)ImageNet


(3)分割研究