Spring Data JPA
首先,让IPersonDAO接口继承Repository
public interface IPersonDao extends Repository {
void save(Person person);
//按照SpringDataJPA的查询方法命名规范定义查询方法
Person findById(Long id);
}
其次,在applicationContext.xml中做如下配置
最后,执行对findById方法的测试,结果如下
Hibernate: select person0_.id as id1_0_, person0_.age as age2_0_, person0_.name as name3_0_
from Person person0_ where person0_.id=?
Person(id=1, name=Neld, age=10)
我们发现,在并没有编写dao的实现类的情况下,仍然完成了数据的查询操作,那么Spring Data JPA是如何完成的呢?接下来分析分析
- applicationContext.xml中配置jps:repositories,作用是对指定包中的持久化对象(实现了Repositories接口的类)进行扫描,然后为其生成代理对象(实现该接口的类)
- 在代理对象中,框架怎么知道我们要指定什么sql呢?
很简单,因为我们继承的是一个泛型接口,在接口中指定了要操作的实体类型和主键的类型,再加上我们在持久化类上有通过注解对对象和关系进行映射,
最后,再通过解析crud方法名称,获取到我们的需求,如:
findById(Long id):我们所有查询相关的方法都是以findBy开头,然后按规范跟上where子句中的条件即可
这样,框架就知道该方法是要根据什么样的条件查询什么样的数据了
方法的命名规范如下图所示:
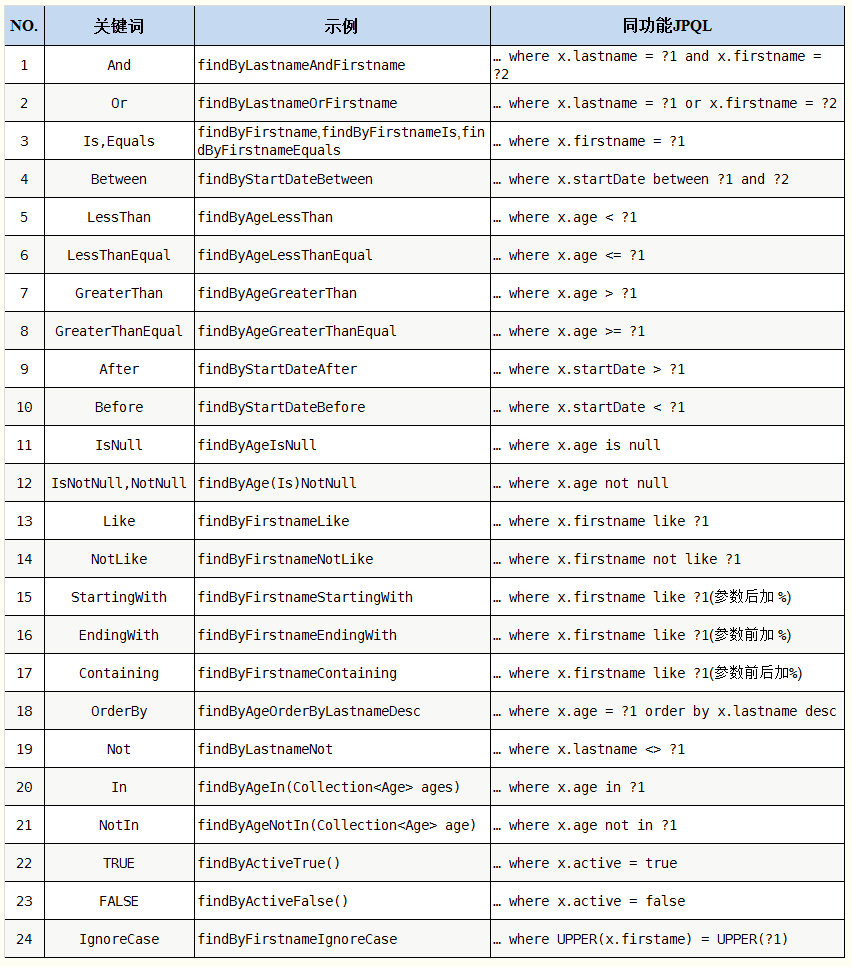
也就是说,使用Spring Data JPA,我们只需要在dao中按照上面的方法命名规范定义方法,框架就能够自动为我们生成对应的SQL语句了,如:
在创建查询时,我们通过在方法名中使用属性名称来表达,比如 findByUserAddressZip ()。框架在解析该方法时,首先剔除 findBy,然后对剩下的属性进行解析,详细规则如下(此处假设该方法针对的域对象为 AccountInfo 类型):
先判断 userAddressZip (根据 POJO 规范,首字母变为小写,下同)是否为 AccountInfo 的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,继续第二步;
从右往左截取第一个大写字母开头的字符串(此处为 Zip),然后检查剩下的字符串是否为 AccountInfo 的一个属性,如果是,则表示根据该属性进行查询;如果没有该属性,则重复第二步,继续从右往左截取;最后假设 user 为 AccountInfo 的一个属性;
接着处理剩下部分( AddressZip ),先判断 user 所对应的类型是否有 addressZip 属性,如果有,则表示该方法最终是根据 “AccountInfo.user.addressZip” 的取值进行查询;否则继续按照步骤 2 的规则从右往左截取,最终表示根据 “AccountInfo.user.address.zip” 的值进行查询。
可能会存在一种特殊情况,比如 AccountInfo 包含一个 user 的属性,也有一个 userAddress 属性,此时会存在混淆。读者可以明确在属性之间加上 “_” 以显式表达意图,比如 “findByUser_AddressZip()” 或者 “findByUserAddress_Zip()”。
Spring Data JPA之核心接口分析
在上面,我们把Spring Data JPA实现CRUD的基本原理做了一个简单的分析,在了解了这些之后,我们再来看看Spring Data JPA中为我们提供的一系列接口
Repository
这是Spring Data JPA中最核心的接口,该接口是一个标识接口,没有定义任何方法,继承了该接口的接口,都应该被扫描生成对应的代理对象
CrudRepository
这是Spring Data JPA为开发者提供的一个完成CRUD功能必需的用到的方法的接口,如下:
@NoRepositoryBean//说明这不属于持久层的JavaBean,不需要为其生成代理对象
public interface CrudRepository extends Repository {
S save(S var1);
Iterable save(Iterable var1);
T findOne(ID var1);
boolean exists(ID var1);
Iterable findAll();
Iterable findAll(Iterable var1);
long count();
void delete(ID var1);
void delete(T var1);
void delete(Iterable var1);
void deleteAll();
}
通过方法名称,相信大家能够快速的理解每个方法的作用,都是我们CRUD中的常用方法
如果开发者有这样的需求,直接让你的dao继承该接口即可,那么Spring Data JPA就会为我们实现该这个接口中的所有方法
PagingAndSortingRepository
分页和排序是开发中的普遍需求,Spring Data JPA也考虑到了,所以专门提供一个接口,在该接口中提供分页和排序需要使用到的方法
@NoRepositoryBean
public interface PagingAndSortingRepository extends CrudRepository {
Iterable findAll(Sort var1);
Page findAll(Pageable var1);
}
JpaRepository
该即可是针对JPA提供的接口,继承了PagingAndSortingRepository接口,在父接口的基础上提供了更多的业务方法,如:saveAndFlush(),deleteInBatch(),flush()等
@NoRepositoryBean
public interface JpaRepository extends PagingAndSortingRepository, QueryByExampleExecutor {
List findAll();
List findAll(Sort var1);
List findAll(Iterable var1);
List save(Iterable var1);
void flush();
S saveAndFlush(S var1);
void deleteInBatch(Iterable var1);
void deleteAllInBatch();
T getOne(ID var1);
List findAll(Example var1);
List findAll(Example var1, Sort var2);
}
在实际开发中,我们可以根据自身的需求,自行选择需要继承的接口,但是,无论怎样,我们都必须要继承Repository