0.PTA得分截图
![]()
1.本周学习总结(0-4分)
1.1 总结栈和队列内容
一.栈
- 栈的定义
栈是一种只能在一端进行插入或删除操作的线性表,俗称:后进先出。表中允许进行插入、删除操作的一端称为栈顶。

- 栈的进栈出栈规则:
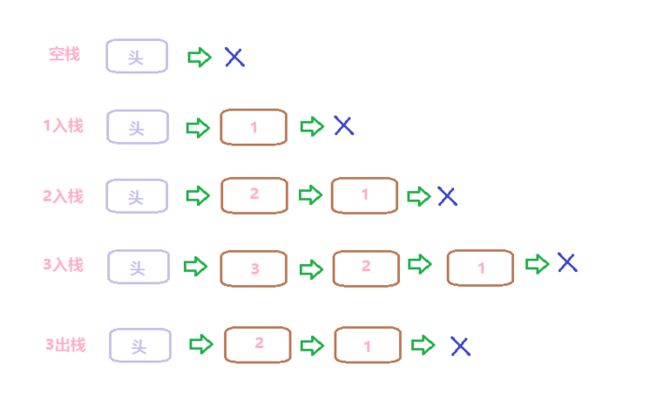
1.栈顶出栈->栈底最后出栈;
2.时进时出->元素未完全进栈时,即可出栈。
- 栈的分类:
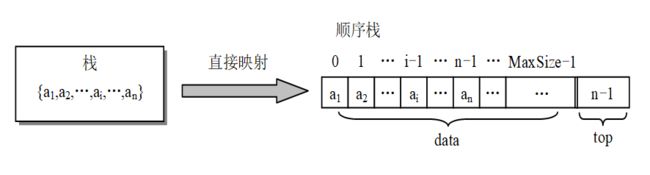
1.顺序栈
利用一组地址连续的存储单元依次存放自栈底到栈顶的数据元素,同时附设指针 top 指示栈顶元素在顺序栈中的位置,附设指针 base 指示栈底的位置。
同样,应该采用可以动态增长存储容量的结构。如果栈已经空了,再继续出栈操作,则发生元素下溢,如果栈满了,再继续入栈操作,则发生元素上溢。
栈底指针 base 初始为空,说明栈不存在,栈顶指针 top 初始指向 base,则说明栈空,元素入栈,则 top++,元素出栈,则 top--,
故,栈顶指针指示的位置其实是栈顶元素的下一位(不是栈顶元素的位置)。
2.链栈
其实就是链表的特殊情形,一个链表,带头结点,栈顶在表头,插入和删除(出栈和入栈)都在表头进行,也就是头插法建表和头删除元素的算法。
显然,链栈插入删除的效率较高,且能共享存储空间。
-
栈的基本运算
-
InitStack(&s):初始化栈。构造一个空栈s。
-
DestroyStack(&s):销毁栈。释放栈s占用的存储空间。
-
StackEmpty(s):判断栈是否为空:若栈s为空,则返回真;否则返回假。
-
Push(&S,e):进栈。将元素e插入到栈s中作为栈顶元素。
-
Pop(&s,&e):出栈。从栈s中退出栈顶元素,并将其值赋给e。
-
GetTop(s,&e):取栈顶元素。返回当前的栈顶元素,并将其值赋给e。
-
-
顺序栈的功能操作代码实现
1.图像表示
2.结构体定义
typedef struct
{ ElemType data[MaxSize];
int top; //栈顶指针
} Stack;
typedef Stack *SqStack;
3.基本运算
<1>初始化栈initStack(&s)
void InitStack(SqStack &s)
{ s=new Stack;
s->top=-1;
}
<2>销毁栈ClearStack(&s)
void DestroyStack(SqStack &s)
{
delete s;
}
<3>判断栈是否为空StackEmpty(s)
bool StackEmpty(SqStack s)
{
return(s->top==-1);
}
<4>进栈Push(&s,e)
bool Push(SqStack &s,ElemType e)
{
if (s->top==MaxSize-1)
return false;
s->top++; //栈顶指针增1
s->data[s->top]=e;
return true;
}
<5>出栈Pop(&s,&e)
bool Pop(SqStack &s,ElemType &e)
{
if (s->top==-1) //栈为空的情况,栈下溢出
return false;
e=s->data[s->top];//取栈顶指针元素
s->top--; //栈顶指针减1
return true;
}
<6>取栈顶元素GetTop(s)
bool GetTop(SqStack *s,ElemType &e)
{
if (s->top==-1) //栈为空的情况
return false;
e=s->data[s->top];
return true;
}
4.顺序栈的四要素
栈空条件:top=-1
栈满条件:top=MaxSize-1
进栈e操作:top++; st->data[top]=e
退栈操作:e=st->data[top]; top--;
- 链栈的功能操作代码实现
1.图像表示
2.结构体定义
typedef int ElemType;
typedef struct linknode
{ ElemType data; //数据域
struct linknode *next; //指针域
} LiNode,*LiStack
3.基本运算
<1>初始化栈initStack(&s)
void InitStack(LiStack &s)
{ s=new LiNode;
s->next=NULL;
}
<2>销毁栈ClearStack(&s)
void DestroyStack(LiStack &s)
{ LiStack p;
while (s!=NULL)
{ p=s;
s=s->next;
free(p);
}
}
<3>判断栈是否为空StackEmpty(s)
bool StackEmpty(LiStack s)
{
return(s->next==NULL);
}
<4>进栈Push(&s,e)
void Push(LiStack &s,ElemType e)
{ LiStack p;
p=new LiNode;
p->data=e; //新建元素e对应的节点*p
p->next=s->next; //插入*p节点作为开始节点
s->next=p;
}
<5>出栈Pop(&s,&e)
bool Pop(LiStack &s,ElemType &e)
{ LiStack p;
if (s->next==NULL) //栈空的情况
return false;
p=s->next; //p指向开始节点
e=p->data;
s->next=p->next; //删除*p节点
free(p); //释放*p节点
return true;
}
<6>取栈顶元素GetTop(s,e)
bool GetTop(LiStack s,ElemType &e)
{ if (s->next==NULL) //栈空的情况
return false;
e=s->next->data;
return true;
}
4.链栈的四要素
栈空条件:s->next=NULL
栈满条件:不考虑
进栈e操作:结点插入到头结点后,链表头插法
退栈操作:取出头结点之后结点的元素并删除之
- 对于栈的C++模板类:stack
#include
1.stack s:初始化栈,参数表示元素类型
2.s.push(t):入栈元素t
3.s.top():返回栈顶元素
4.s.pop():出栈操作只是删除栈顶元素,并不返回该元素
。
5.s1.empty(),当栈空时,返回true。
6.s1.size():访问栈中的元素个数
-
栈的应用
-
网络浏览器多会将用户最近访问过的网址组织为一个栈。
- 用户访问一个新页面,其地址会被存放至栈顶;而“后退”按钮,即可沿相反的次序访问此前刚访问过的页面。
-
递归算法
-
表达式求值--中缀表达式转后缀表达式
-
中缀表达式:运算符号位于两个运算数之间。
-
后缀表达式:运算符号位于两个运算数之后。
-
-
二.队列
- 队列的定义
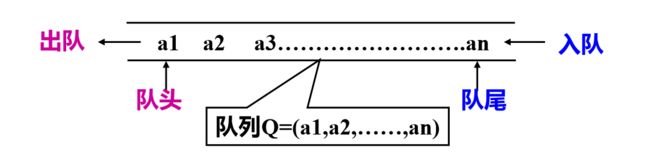
只允许在表的一端进行插入,而在表的另一端进行删除的线性表。
- 队列的出队入队规则
1.限定在表的一端插入、另一端删除。 插入的那头就是队尾,删除的那头就是队头。也就是说只能在线性表的表头删除元素,在表尾插入元素。
2.先进先出。我们不能在表(队列)的中间操作元素,只能是在尾部进,在头部出去。
- 队列的分类
1.顺序队列
用一组连续的存储单元依次存放队列中的元素。
2.链队列
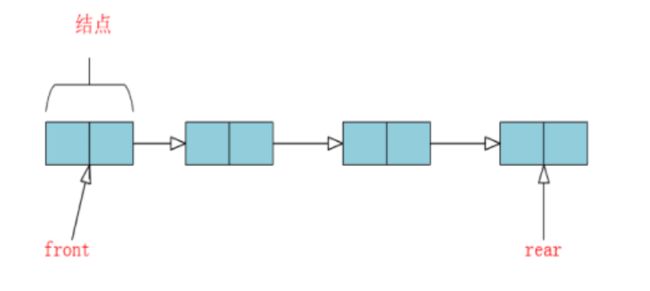
用链表表示的队列,限制仅在表头删除和表尾插入的单链表。
一个链队列由一个头指针和一个尾指针唯一确定。(因为仅有头指针不便于在表尾做插入操作)。
为了操作的方便,也给链队列添加一个头结点,因此,空队列的判定条件是:头指针和尾指针都指向头结点。
3.环形队列(循环队列)
把顺序队列首尾相连,把存储队列元素的表从逻辑上看成一个环,成为循环队列。
-
队列的基本运算
-
InitQueue(&Q):构造一个空队列Q。
-
DestroyQueue(&Q):销毁队列Q。
-
QueueEmpty(Q):判断队列Q是否为空。
-
QueueLength(Q):返回Q的元素个数,即队列的长度。
-
GetHead(Q, &e):用e返回Q的队头元素。
-
ClearQueue(&Q):将Q清为空队列。
-
EnQueue(&Q, e):插入元素e为Q的新的队尾元素。
-
DeQueue(&Q, &e):删除Q的队头元素,并用e返回其值。
-
-
顺序队列的功能操作代码实现
1.结构体定义
#define MAXQSIZE 100 //最大队列长度
typedef struct
{
QElemType *base; //初始化动态分配存储空间
int front, rear ; /*队首、队尾*/
}SqQueue;
SqQueue Q;
2.基本运算
<1>初始化队列InitQueue(&q)
void InitQueue(SqQueue *&q){
q=(SqQueue *)malloc(sizeof(SqQueue));
q->front=q->rear=-1;
}
<2>销毁队列DestroyQueue(&q)
void DestroyQueue(SqQueue *&q){
free(q);
}
<3>判断队列是否为空QueueEmpty(q)
void QueueEmpty(SqQueue *q){
return (q->front==q->rear);
}
<4>enQueue(&q,e)
bool enQueue(SqQueue *&q,ElemType e){
if(q->rear==MaxSize) return false; //队满上溢
q->rear++;
q->data[q->rear]=e;
return true;
}
<5>出队列deQueue(&q,&e)
bool deQueue(SqQueue *&q,ElemType &e){
if(q->front==q->rear) return false;
q->front++;
e=q->data[q->front];
return true;
}
3.顺序队列的四要素
空队列条件:Q.front==Q.rear
队列满:Q.rear-Q.front=m
入队: Q.base[rear++]=x;
出队:x=Q.base[front++];
- 链队列的功能操作代码实现
1.图像表示
2.结构体定义
typedef int QElemType;
typedef struct QNode {// 结点类型
QElemType data;
struct QNode *next;
} QNode, *QueuePtr;
typedef struct { // 链队列类
QueuePtr front; // 队头指针
QueuePtr rear; // 队尾指针
} LinkQueue;
3.基本运算
<1>创建结点
QueuePtr createNode(int data){
struct Node* newNode=(struct Node*)malloc(sizeof(struct Node));
newNode->next=NULL;
newNode->data=data;
return newNode;
};
<2>队列的初始化
QueuePtr createQueue(){
QueuePtr queue=new QNode;//分配内存空间
queue->front=queue->rear=NULL;//头指针和尾指针在一起为空
queue->queueSize=0;//队列大小为0
return queue;
}
<3>入队操作
void push(QueuePtr queue,int data){
QueuePtr newNode=createNode(data);
if(queue->queueSize==0)
queue->front=newNode;
else
queue->rear->next=newNode;
queue->rear=newNode;
queue->queueSize++;
}
<4>获取对头元素
int queryFront(QueuePtr queue) {
if(queue->queueSize==0){
printf("队列为空无法获取对头元素");
printf("\n");
return -1;
}
return queue->front->data;
}
<5>判断队列是否为空
int empty(QueuePtr queue){
if(queue->queueSize==0)
return 0;
else
return 1;
}
<6>出队操作
void pop (QueuePtr queue){
if(queue->queueSize==0){
printf("队列为空不能出队");
exit(0);
}else{
QueuePtr newFrontNode=queue->front->next;
free(queue->front);
queue->front=newFrontNode;
queue->queueSize--;
}
}
- 循环队列
1.图像表示

2.循环队列的产生
当使用顺序队列时,会遇到明明队中还有位置却不能入队的情况
这是因为采用rear==MaxSize-1作为队满条件的缺陷。
当队满条件为真时,队中可能还有若干空位置。这种溢出并不是真的溢出,称为假溢出。
为了解决这种情况下造成的假溢出
把数组的前端和后端连接起来,形成一个环形的顺序表,即把存储队列元素的表从逻辑上看成一个环,称为环形队列或循环队列。
3.循环队列的入/出队列运算(利用“模运算”)
-
入队:Q.rear=(Q.rear+1)%m
-
出队:Q.front=(Q.front+1)%m
4.循环队列的四要素
队空条件:front=rear
队满条件:(rear+1)%MaxSize=front
进队e操作:rear=(rear+1)%MaxSize;将e放在rear处;
出队操作:front=(front+1)%MaxSize;取出front处元素e;
- 对于队列的C++模板类:queue
1.push():将x入队,时间复杂度为O(1)
2.front()back():分别可以获得队首元素和队尾元素,时间复杂度为O(1)
3.pop():令队首元素出队,时间复杂度为O(1)
4.empty():检查queue是否为空,返回true则空,返回false则非空,时间复杂度为O(1)
5.size():返回queue内元素的个数,时间复杂度为O(1)
-
队列的应用
-
重复密钥
-
凯撒加密
- 通过将字母按顺序推后3位起到加密作用
-
图的宽度优先搜索法
-
操作系统的作业调度,用于缓冲区,网络中的路由缓冲包区。
-
1.2.谈谈你对栈和队列的认识及学习体会。
栈(Stack)是限定仅在表尾进行插入和删除操作的线性表。
队列(Queue)是允许在一端进行插入,一端进行删除操作的线性表。
它们都可以用线性表的顺序存储结构来实现,但都存在着顺序存储的一些弊端。
对于栈来说,如果是两个相同数据类型的栈,则可以用数组的两端作栈底的方法来让两个栈共享数据,这就可以最大化利用数组的空间。
对于队列来说,为了避免插入删除需要移动数据,于是就引入了循环队列,使得队头和队尾可以在数组中循环变化。
解决了移动数据的时间损耗,使得本来插入和删除是O(n)的时间复杂度变成O(1)。
在学习了栈和队列的相关内容之后,在场景的应用方面又得到了一定的拓展,面对之前无法解决的情况也得到了新的方法。
在接下来对存储结构操作的不断学习中,应付不同问题的手法也将越来越熟练。
2.PTA实验作业(0-2分)
2.1.题目1:7-5 表达式转换 (25分)
2.1.1代码截图




2.1.2本题PTA提交列表说明。

Q1:没有考虑到当表达式头或左括号后为+-符号时对应的操作,应加上该情况下对应的操作
Q2:在当经过在表达式头或左括号后为+-号后,没有将flag1、2的值赋为1,从而导致非指定条件下进入错误的判断
2.2 题目2:7-7 银行业务队列简单模拟 (25分)
2.2.1代码截图


2.2.2本题PTA提交列表说明。

Q1:没有判断输出空格的条件,导致末尾留有空格而格式错误
Q2:在输出空格的判断条件中忽略了A、B至少有一者非空就要输出空格的整体性
3.阅读代码(0--4分)
3.1 题目及解题代码
题目

解题代码
class Solution {
public:
bool validateStackSequences(vector& pushed, vector& popped) {
stack st;
int n = popped.size();
int j = 0;
for (int i = 0; i < pushed.size(); ++i){
st.push(pushed[i]);
while(!st.empty() && j < n && st.top() == popped[j]){
st.pop();
++j;
}
}
return st.empty();
}
};
3.1.1 该题的设计思路




时间复杂度:O(N)
空间复杂度:O(N)
3.1.2 该题的伪代码
初始化栈 stack,j = 0;
遍历 pushed 中的元素 x;
当 j < popped.size() 且栈顶元素等于 popped[j]:
弹出栈顶元素;
j += 1;
如果栈为空,返回 True,否则返回 False。
3.1.3 运行结果
符合情况

不符情况

3.1.4分析该题目解题优势及难点。
解题优势:
思路很简单,尝试按照 popped 中的顺序模拟一下出栈操作,如果符合则返回 true,否则返回 false。
这里用到的贪心法则是如果栈顶元素等于 popped 序列中下一个要 pop 的值,则应立刻将该值 pop 出来。
难点:
使用一个栈 st 来模拟该操作。
将 pushed 数组中的每个数依次入栈,在入栈的同时需要判断这个数是不是 popped 数组中下一个要 pop 的值。
如果是就把它 pop 出来。
最后检查栈是否为空。
3.2 题目及解题代码
题目

解题代码
using PII = pair;
class Solution {
public:
bool canMeasureWater(int x, int y, int z) {
stack stk;
stk.emplace(0, 0);
auto hash_function = [](const PII& o) {return hash()(o.first) ^ hash()(o.second);};
unordered_set seen(0, hash_function);
while (!stk.empty()) {
if (seen.count(stk.top())) {
stk.pop();
continue;
}
seen.emplace(stk.top());
auto [remain_x, remain_y] = stk.top();
stk.pop();
if (remain_x == z || remain_y == z || remain_x + remain_y == z) {
return true;
}
stk.emplace(x, remain_y);
stk.emplace(remain_x, y);
stk.emplace(0, remain_y);
stk.emplace(remain_x, 0);
stk.emplace(remain_x - min(remain_x, y - remain_y), remain_y + min(remain_x, y - remain_y));
stk.emplace(remain_x + min(remain_y, x - remain_x), remain_y - min(remain_y, x - remain_x));
}
return false;
}
};
3.2.1 该题的设计思路

时间复杂度:O(xy)
空间复杂度:O(xy)
3.2.2 该题的伪代码
stack stk;
stk.emplace(0, 0);
以 remain_x, remain_y 作为状态,表示 X 壶和 Y 壶中的水量。
HashSet存储所有已经搜索过的 remain_x, remain_y 状态,
保证每个状态至多只被搜索一次。
while (!stk.empty())
把 X 壶灌满。
把 Y 壶灌满。
把 X 壶倒空。
把 Y 壶倒空。
把 X 壶的水灌进 Y 壶,直至灌满或倒空。
把 Y 壶的水灌进 X 壶,直至灌满或倒空。
end while
返回flase
3.2.3 运行结果
符合情况:

不符情况:

3.2.4分析该题目解题优势及难点。
解题优势:
在实际的代码编写中,由于深度优先搜索导致的递归远远超过了 Python 的默认递归层数,
因此下面的代码使用栈来模拟递归,避免了真正使用递归而导致的问题。
难点:
在每一步搜索时,会依次尝试所有的操作,递归地搜索下去。这可能会导致陷入无止境的递归。