0.PTA得分截图
![]()
1.本周学习总结
1.1 总结线性表内容
顺序表
1.顺序表结构体定义
- 结构体成员通常包括数组,即数组长度。(pta题中也曾出现,结构体成员中的数组长度改为最后一个元素的位置。)
typedef struct{
int data[maxsize];
int length;
}SqList;
typedef SqList *List;
2.顺序表的插入操作
思路分析:
- 用i遍历后保存要插入的位置,然后用j来移动数组实现插入
伪代码:

具体代码:经典例解-2019-线性表-6-2 jmu-ds-有序表插入数据
void InsertSq(SqList& L, int x)
{
int i,j;
for (i = 0; i < L->length; i++)//找到插入位置
{
if (x < L->data[i]) break;
}
for (j = L->length; j>i;j--)
{
L->data[j] = L->data[j - 1];
}
L->data[i] = x;
L->length++;
}
3.顺序表的删除操作
思路分析:
- 找到要删除的元素后,对数组进行移动后并改变数组长度即可
伪代码:

-
1.移动完数组后L->length要 及时减一,因为 循环的条件受数组长度的限制
-
2.关于i--:由于每次移动,被删数据的下一数据往前移动。i需减一才能遍历到已删除后移动到该位置的新数据。否则在某些数据删除中则可能出错,会出现删除不完全的情况。
具体代码:经典例解-2019-线性表-6-1 jmu-ds-区间删除数据
void DelNode(SqList& L, int min, int max)//删除区间元素。min,max表示删除的区间
{
int i=0;
int j;
int length = L->length;
while(idata[i] >= min) && (L->data[i] <= max))
{
for (j = i + 1; j <= length - 1; j++)
{
L->data[j - 1] = L->data[j];
}
length--;//每次移动完要改变数组长度
i--;//数组移动过同时需要从头开始查找//无需从头,i--即可
}
else i++;
}
L->length = length;
}
链表
4.链表结构体定义
typedef int ElemType;
typedef struct LNode //定义单链表结点类型
{
ElemType data;
struct LNode *next; //指向后继结点
} LNode,*LinkList;
- 此处data通常是int类型
2.链表尾插法
思路分析:
-
插入链表时需要尾指针来指位置tail。
-
尾插法建链L时,尾指针tail的初始状态通常为tail=L

具体代码:通常应用于尾插法建链 经典例解-2019-线性表-6-6 jmu-ds-尾插法建链表
void CreateListR(LinkList& L, int n)
{
int i;
LinkList p, tail;
L = tail = new LNode;//先申请内存
L->next = NULL;
for (i = 1; i <= n; i++)
{
p = new LNode;
scanf("%d", &p->data);
tail->next = p;
tail = p;
}
tail->next = NULL;
}
-
针对该代码注意!!!:建链结束后记得要 tail->next=NULL
-
若在节点插入时,每个节点的生成都带有该命令p->next=NULL,则当最后一个节点插入链表时就无需再加tail->next=NULL
5.链表头插法
思路分析
- 由于我们通常使用带头结点的链表,头插法与尾插不同,无需另外的辅助指针 。插入位置的前驱为头结点L,插入位置的后继为L->next

具体代码:通常也应用于头插法建链 经典例解-2019-线性表-6-5 jmu-ds-头插法建链表
void CreateListF(LinkList& L, int n)
{
int i;
LinkList p;
L = new LNode;
L->next=NULL;
for (i = 1; i <= n; i++)
{
p = new LNode;
scanf("%d", &p->data);
p->next = L->next;
L->next = p;
}
}
- 注意!!!:头插法链L的初始化 L->next=NULL 尤为重要。
因为随着不断插入结点,结束插入结点后,由于找不到链尾,我们无法像尾插法一样结束了以后再将链尾指向空。
而初始L指向空时,即使在头不断插入结点,NULL不断后移,也不会丢失链尾指向NULL的关系
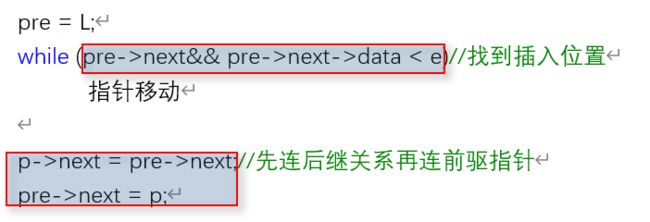
7.链表插入:
思路:
-
为了保留插入位置的前后继关系,我们需要前驱指针pre
-
遍历链表找到插入位置,先连后继在连前驱 插入。
-
同时遍历链表我们可以直接利用pre->next,无需另设指针
伪代码:
-
while判断时,注意先要判断是否存在才能比较数据,否则会引发异常(容易引发异常的情况)
-
在链表间插入的具体操作
具体代码:经典例解-2019-线性表-6-10 jmu-ds-有序链表的插入删除
void ListInsert(LinkList& L, ElemType e)//有序链表插入元素e
{
LinkList pre, p;//pre为前驱指针,p为插入结点
pre = L;
p = (LinkList)malloc(sizeof(LNode));
p->data = e;
while (pre->next && pre->next->data < e)//找到插入位置
{
pre = pre->next;
}
p->next = pre->next;//先连后继关系
pre->next = p;//再连前驱指针所保留的前面的关系
}
8.链表数据删除
思路分析:
- 遍历链表找到删除数据后,需要利用一个辅助指针来保存要删除的结点,再改变后继关系,然后释放结点
伪代码:

-
1.注意:要先改变后继关系后,再释放结点,否则后继关系丢失
-
2.拓展:若所给链表中 要删除的相同数据有多个,则将伪代码中的 break去掉,该伪代码思路同样适用。(此时一旦找到重复数据不会跳出,而是继续遍历,直到链表结束)
具体代码:经典例解-2019-线性表-6-10 jmu-ds-有序链表的插入删除
void ListDelete(LinkList& L, ElemType e)//链表删除元素e
{
LinkList pre, p;//pre为前驱指针,p用来保存要删除的结点
pre = L;
if (L->next == NULL) return;//若为空链表直接返回
while (pre->next)
{
if (pre->next->data == e)//若找到要删除的元素
{
p = pre->next;//保存要删除的结点
pre->next = p->next;//通过改变链的后继关系实现删除
free(p);//释放删除的结点
return;
}
else pre = pre->next;
}
if (pre->next==NULL) printf("%d找不到!\n", e);//遍历完了链表则说明并未找到
}
- 具体代码实现过程中,要根据题目需求设计判断条件。常见如:空表直接返回、未找到情况等要进行判断说明情况
有序表
有序表的插入删除基本已在上面链表的插入删除中介绍,接下来总结有序表的另外一个应用有序表合并
9.有序表的合并
思路分析:
合并两个有序表时,用两个指针同时遍历这两个链表,对比当前指针所在位置数据,若要求递增数列,则将较小数据扫入新链,并移动指针位置,直至结束。
伪代码:
此伪代码是针对于合并链表时,若有重复元素则只取一个的情况

-
1.对于两数据相等的情况,值可取其一赋值,但是为了保证不扫入重复数据,两个指针必须同时移动
-
2.此外考虑到可能 其中一链表已遍历完毕 的情况,根据其有序以及比较的特性,直接另一链的剩下部分接上新链即可
-
3.拓展:根据题目需求若是将两链元素全都合并到新链中(即无需考虑元素是否重复情况)。此时伪代码中仅需if-else语句,如此便可全都扫入新链中

注意:此时是将p2数据小于p1的情况与两数据相等的情况相合并,赋值时一定是按照p2
具体代码:经典例解-2019-线性表-6-9 jmu-ds-有序链表合并
void MergeList(LinkList& L1, LinkList L2)//合并链表
{
LinkList p, p1, p2;
p1= L1->next;//重置链表先保存后继关系
L1->next = NULL;
p2 = L2->next;
p = L1;
while (p1 && p2)
{
if (p1->data < p2->data)
{
p->next = p1;
p = p1;
p1 = p1->next;
}
else if (p1->data > p2->data)
{
p->next = p2;
p = p2;
p2 = p2->next;
}
else
{
p->next = p2;
p = p2;
p2 = p2->next;
p1 = p1->next;
}
}
while (p2)
{
p->next = p2;
p = p2;
p2 = p2->next;
}
while (p1)
{
p->next = p1;
p = p1;
p1 = p1->next;
}
p->next = NULL;
}
- 1.合并成新链时我们可以建新链,或是直接重构原有链,不同的只是空间复杂度。需要注意的是,重构链时,需要先用指针保留原有的链关系
10.循环链表、双链表结构特点
-
双链表结构特点:双链表的每个节点有两个指针域,一个指向后继节点,一个指向前驱节点。
-
双链表优点:从任意节点出发可以快速找到其前驱节点和后继节点;从任意节点出发可以访问其他节点
-
双链表的插入删除操作:多的部分只是要记得将节点的前驱指针互相连上
-
循环链表结构特点:循环链表中没有明显的尾端,循环条件:p->next!=L
-
循环链表优点:与双链表一样,从循环链表的任意一个结点的位置都可以找到其他结点
1.2其他内容总结
关于是否要申请内存的问题
-
关于是否要申请内存的问题,归结于我们的需求问题,即我们是否需要给予指针内容
-
如在建链过程中,在循环插入的过程,我们也需要循环为结点申请内存。虽然我们始终用同一个指针来操作新结点,但每个结点都不同,都存储着不同的数据。
-
关于一些辅助指针:
如我们用p来遍历链表,当我们初始化p=L,此时尽管我们不提前申请内存,访问p->next也不会出错,因为此时访问的就是L->next。如我们使用尾指针tail,tail->next=NULL,tail=L;我们的目的是为了初始化链L和尾指针,但在tail未申请内存情况下,非法访问这就引发异常,在不申请内存的情况下此时两句命令顺序
对调即可 -
新结点的申请内存关系还需根据实际问题实际需求决定:
例如,在合并有序表的问题中:我们合并两条链时,大可不必重新申请结点内存,只要处理好结点的关系,就可以直接将原有链中结点一个个分割连接到新链中。又如,在一元多项式的加法和乘法问题中:在写加法时,我们只需判断指数相同,系数相加即可。此时我们大可以直接利用原有结点,因为指数都不用变动,修改系数即可使用。然而事实上
题目包含了两个需要解决问题,也就是我们需要写两个都需要用到两个原链数据的函数,此时我们则不能轻易改变原链关系。当然若根据在主函数中的操作,调用第一个函数时不改变原链,
第二个函数改不改变也就无所谓了。因此总的来说,是否申请新的结点,还是直接借用原有资源,改变原有链,这都需要我们根据自己的实际需要,要根据我们的解题思路而变。
关于删除线性表中重复元素
无序表
-
解法一:应用两层循环,外循环遍历链表,内层循环从位置的下一个位置开始遍历,若找到重复的则删除。
很明显该解法使用两层循环,时间复杂度起码为O(n^2)。若是在数组中删除,由于数组的删除,需要挪动数组,此种解法就更加耗费时间 -
解法二:(哈希数组)申请一个新的数组,以原线性表的值作为下标,那么这样一个下标就只能对应一个元素,即使哈希一个重复的元素到同一下标,也只能存储一次。
相比解法一,哈希数组空间复杂度较为复杂为O(n),但是时间上却大大缩短的,只需遍历一遍线性表,时间复杂度即为O(n)。
但哈希数组的限制性也较为为明显,由于数组下标的限制,只能为非负数。还有线性表中元素的值不能太大,由于定义新数组的大小由线性表中的最大值确定,所以有时并不好确定。并且只
是个别元素值过大的话,为最大值而扩充数组,数组也容易造成浪费
有序表
- 保存不相同的元素
由于有序,与相邻元素比较即可,对于不相同的元素是就存储保留起来。
这种思想也可以用在删除某个给定的数组元素,保留不等于给定元素的的其它元素,然后就可以在O(n)的时间复杂度内实现删除某个给定的元素了。
总结:
很显然无序表删除重复元素的方法大都有所缺陷或是,时间空间代价较大。
我们可以根据具体题目已给线性表类型,根据题目具体所给测试样例选择。
若是在无序表无论何种方法所花代价较大时,我们也可以考虑先写函数,对无序表进行排序,然后在利用有序表删除重复元素的解法
1.2.谈谈你对线性表的认识及学习体会。
-
一开始是觉得链表这部分内容大都已经学过了,但是从寒假的链表复习的小题集,到开学这段时间的线性表题集做的情况来看,再次学习还是有一定的进步和体会。
-
如一开始做寒假的复习题集的时候,一时间回忆不上来,看了老师提前给的ppt才慢慢复习起了有关链表的建链插入删除等的操作的思路构架。通过这学期做线性表的练习,对链表的操作更加
熟悉,主要是操作时的思路更加清晰,无需次次都去翻课堂笔记还有ppt。 -
1.关于链表操作利用的辅助指针有了更清晰的了解:
有如链表的尾插法,必须要用到尾指针才知道在哪插。我们链表输出时用一个p指针来遍历。而当我们操作链表的插入删除时,也需要遍历链表找到插入删除位置,而前驱指针则是pre既是保留了前后继关系,同时用来遍历链表的指针。 -
2.关于结点释放的意识提高关于链表的删除销毁时,上学期做链表实验时,并没有要将删除的结点释放掉的概念,有时不记得,便觉得链的关系改变了即可。这学期在老师的反复强调下,不用的空间即释放的意识提高了很多。
-
3 .对于申请内存问题有所感触:
上学期对于链表中有关于申请动态内存这方面不算很清楚,只是照猫画虎,依照老师课堂上大概的框架来写。有如链表的插入时,只是单纯记得结点的动态申请要在循环内,每次都要循环生
成。
而这段时间就辅助指针是否需要申请内存并不清晰,而时常在后面的条件判断等中非法访问,时常引发异常。
但正是通过一次次异常出错后调试,才渐渐对申请内存这个问题的了解清晰起来。并且对是否有必要为辅助指针申请内存的问题,也会学着依据自己的代码斟酌或是调试后再调整。
2.PTA实验作业
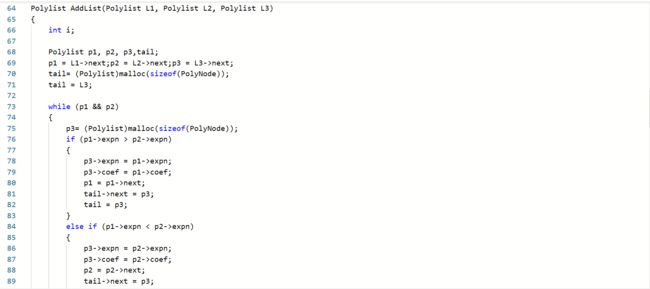
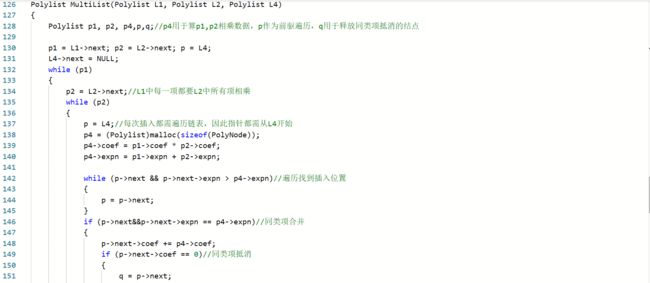
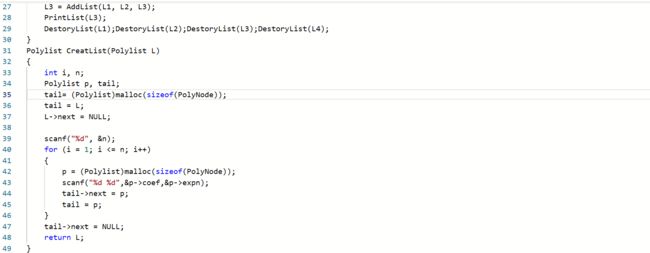
2.1.题目1:2019-线性表-7-2 一元多项式的乘法与加法运算
2.1.1代码截图
加法函数


乘法函数

主函数和其他函数



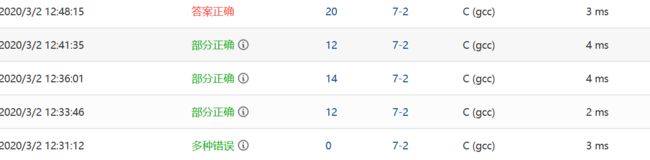
2.1.2本题PTA提交列表说明。
-
一开始写加法函数时,直接利用原链的结点接入到新链中。加法函数是成功了,但是乘法函数的结果就不对。进行调试后就发现,先进行了加法函数以后打乱了原链的关系,因此乘
法函数得到的结果出错,由此对加法函数写法进行改变。 -
部分正确,是由于在乘法时合并同类项,和加法同指数相加时,都忘了考虑系数相加为0,该项抵消的问题。发现问题后添加判断条件即可
-
还有就是输出函数未注意到,空项未按照题目格式“0 0”输出,修改即可。
2.2 题目2:2019-线性表-7-1 两个有序序列的中位数
2.2.1代码截图
主函数

核心功能实现函数
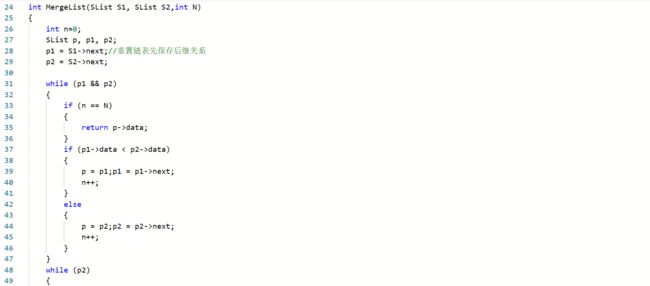

其他函数
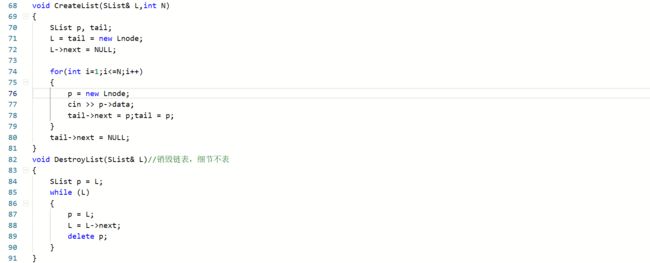
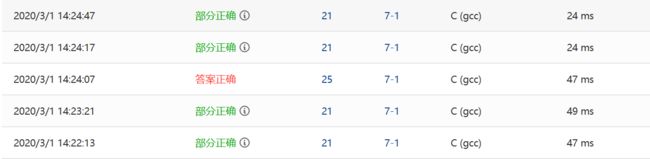
2.2.2本题PTA提交列表说明。
![]()
-
前五次做的时候思路是用数组来存数据,然后将两个数组合并后,由于数组下标好取的特点直接取。前五次中的错误主要与定义的数组的长度有关。
-
最后一次思路是根据上课老师所讲的思路,用的链表结构存储数据,归并过程中,记数已归并个数,第N个即为所求。并且经过老师讲解,发现归并过程中无需新辟链表存储归并后的链表,
直接记数即可,又降低了空间复杂度。 -
由提交列表可以看出,两种方法相比采用数组的耗时更短,而链表所耗空间则更小。
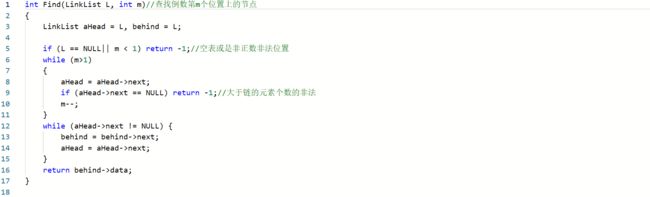
2.3 题目3:2019-线性表-6-8 jmu-ds-链表倒数第m个数
2.3.1代码截图
法1:

法2:
2.2.2本题PTA提交列表说明。
![]()

-
第一次写的时候用的是常规思路,先遍历一遍链表,总计链表元素个数,再根据计算算出倒数第k个数的正向位置,然后再次遍历链表,返回该值
-
后面的几次是利用快慢指针的写法来重新解该题。参考了阅读代码中伪代码的做法,由于阅读代码中的链是不带头结点的链,因此在非法位置的判断上略有不同。因此错误主要是
分布在非法判断上,在大于该链数的非法情况做了多次调试改写。
3.阅读代码
3.1题目及解题代码
题目

解题代码
class Solution {
public:
ListNode* rotateRight(ListNode* head, int k) {
if(!head) return head;
auto h = head, tail = head;
int len = 0;
while(tail->next)
{
tail = tail->next;
len++;
}
len++;
k = k % len;
if(k == 0) return head;
tail->next = h;
int move = len - k - 1;//向前移动idx找tail
tail = h;
while(move--)
tail = tail->next;
h = tail->next;
tail->next= nullptr;
return h;
}
};
3.1.1设计思路
- 先把链表的首尾连起来,变成循环链表,方便查找。然后再根据位置关系找出新链的尾,而尾的下一结即为头,然后再根据首尾关系断开链,返回新链头位置

3.1.2伪代码

-
该解法的主要思路就是将链的首尾相接,通过计算后,找到新链的首尾,再将其断开,返回新链头即可
-
从代码分析来看,该链是不带头结点的链表,所以在遍历完之后需要len++
-
k=k%len 是考虑到了k>len情况,意在算出实际操作过程中最少的移动次数。同时考虑到k==len时,其实就算了旋转了一轮实际并无改变,无需操作,直接返回即可
-
给链的代码都是针对不带头结点的链表进行操作,实际运行过程中要注意区别稍做调整
3.1.3 运行结果
向右旋转位置为1时

向右旋转位置为2时
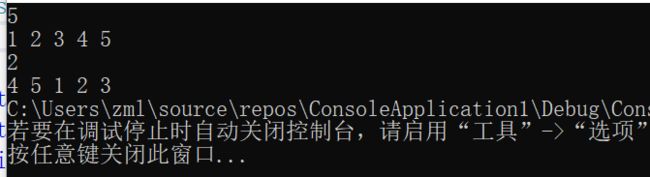
向右旋转位置为8时
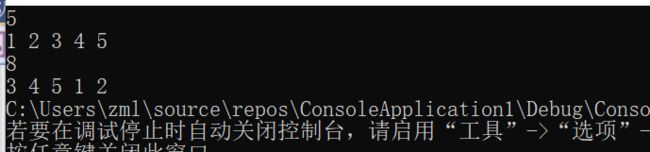
3.1.4分析该题目解题优势及难点
-
难点:由于我们目前所学所用的基本上都是单链表,看到这题时,直接思想可能就是考虑怎样利用循环将每个结点一个个移动来达到旋转链。但光是想想这种思路就觉得,要花好多心思来构
思循环还有移动的写法。 -
解题优势:而解题优势就很明显的体现在了先将链首尾相接,然后再分割新链的思路。这样只需要根据计算关系找到新链首尾,而循环单链又能访问到每个结点,就可以移动到首尾
位置,进行分割即可 -
解题具体代码分析:
该算法没有另外新辟链,因此空间复杂度为O(1),时间上遍历一次列表记数元素个数,然后在移动,时间复杂度为O(n)。
k=k%len;这句代码我觉得很好,考虑了实际需要移动的位置,简便了后面查找首尾指针的移动次数。
但是 关于具体的计算尾指针的位置,及尾指针的移动 的操作,我觉得还是可以改进的:尾指针无需移动到头的位置,向前移动k,即为尾指针的位置。

3.2题目及解题代码
题目: 截取出单链表中的后K个结点
解题代码:
ListNode* NthFromEnd(ListNode* head, int k){
if(head == NULL) return NULL;
ListNode* aHead = head,*behind = head;
while(k>1) {
aHead = aHead->next;
k--;
}
while(aHead->next != NULL){
behind = behind->next;
aHead = aHead->next;
}
return behind;
}
3.2.1设计思路
- 使用两个指针,先让前面的指针走到正向第k个结点,这样前后两个指针的距离差是k-1,之后前后两个指针一起向前走,前面的指针走到最后一个结点时,后面指针所指就是后K个结点
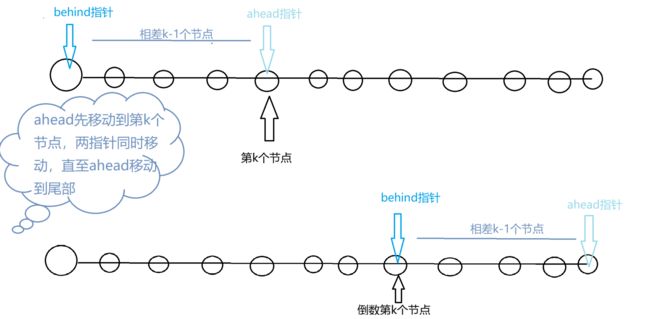
3.2.2伪代码

- 由于两节点间的差为k-1,因此while条件为k>1
3.2.3运行结果
输出后3个节点
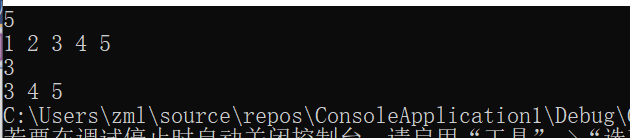
输出后2两个节点
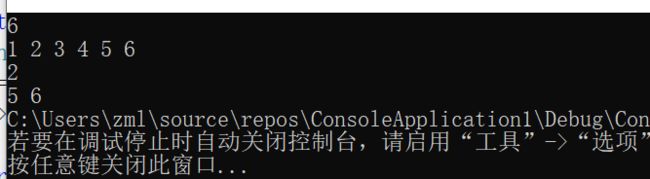
3.2.4分析该题目解题优势及难点
-
优势:是与常规思路相比,常规思路是遍历一遍链表记数总个数后,再次遍历到倒数第k个再将链返。时间复杂度都为O(n),空间复杂度为O(1),但用快慢指针遍历一遍更快一点
-
拓展:该题思路实际上和用快慢指针做求倒数第k个节点是一样的。只不过该题是最后K个节点都要截取下来,根据链表特点,将倒数第k个节点地址返回即可。
不过在编写关于求倒数第K个节点时,注意关于带头结点和不带头结点的链表的具体写法略有不同。