项目整体设计为前后端完全分离的模式,
前端采用react以及amazeui构建用户交互界面,
后端采用python flask提供restful接口与前端UI交互起源于 Facebook 的内部项目,用来架设 Instagram 的网站,并于 2013 年 5 月开源。它拥有较高的性能,代码逻辑非常简单,越来越多的人已开始关注和使用它。下面详细介绍前端UI实现中涉及的一些技术
ECMAScript 6
ECMAScript 6(以下简称 ES6)是 JavaScript 语言的下一代标准,已经在 2015 年 6 月正式发布了。Mozilla 公司将在这个标准的基础上,推出 JavaScript 2.0。
ES6 的目标,是使得 JavaScript 语言可以用来编写大型的复杂的应用程序,成为企业级开发语言。
简单说,ECMAScript 是 JavaScript 语言的国际标准,JavaScript 是 ECMAScript 的实现。
截止至今各大浏览器的最新版本,随着时间的推移,对ES6支持度已经越来越高了,ES6 的大部分特性都实现了。
babel
babel是一个能让我们今天就来用下一代 JavaScript 语法写代码的广泛使用的自动转码器
Babel是一个转换编译器,它能将ES6转换成可以在浏览器中运行的代码。Babel由来自澳大利亚的开发者Sebastian McKenzie创建。他的目标是使Babel可以处理ES6的所有新语法,并为它内置了React JSX扩展及Flow类型注解支持。
Babel是所有ES6转换编译器中与ES6规范兼容度最高的,甚至超过了谷歌创建已久的Traceur编译器。Babel允许开发者使用ES6的所有新特性,而且不会影响与老版本浏览器的兼容性。此外,它还支持许多不同的构建&测试系统,使开发者很容易将它集成到自己的工具链中。
Babel从根本上讲是一个平台,这是它与compile-to-JS语言CoffeeScript和TypeScript最大的不同。Babel的插件系统允许开发者自定义代码转换器并插入到编译过程。这些转换器会接收一棵抽象语法树,并在代码转换成可执行的JavaScript之前对其进行操作。
Babel还能提升JavaScript的执行速度。由于JavaScript文件加载和执行速度慢会严重影响用户体验,所以JIT没有时间在运行时执行所有技术上可行的优化。相比之下,Babel是在编译时运行,没有这么严格的时间限制。借助强大的作用域跟踪和类型推断功能及插件系统,开发者可以构建转换器来执行此类优化
nodejs
Node.js采用C++语言编写而成,是一个Javascript的运行环境。Node.js采用了Google Chrome浏览器的V8引擎,性能很好,同时还提供了很多系统级的API,如文件操作、网络编程等。浏览器端的Javascript代码在运行时会受到各种安全性的限制,对客户系统的操作有限。相比之下,Node.js则是一个全面的后台运行时,为Javascript提供了其他语言能够实现的许多功能。
Node.js的设计思想中以事件驱动为核心,它提供的绝大多数API都是基于事件的、异步的风格。以Net模块为例,其中的net.Socket对象就有以下事件:connect、data、end、timeout、drain、error、close等,使用Node.js的开发人员需要根据自己的业务逻辑注册相应的回调函数。这些回调函数都是异步执行的,这意味着虽然在代码结构中,这些函数看似是依次注册的,但是它们并不依赖于自身出现的顺序,而是等待相应的事件触发。事件驱动、异步编程的设计重要的优势在于,充分利用了系统资源,执行代码无须阻塞等待某种操作完成,有限的资源可以用于其他的任务。

NPM
NPM是随同NodeJS一起安装的包管理工具,能解决NodeJS代码部署上的很多问题,常见的使用场景有以下几种:
允许用户从NPM服务器下载别人编写的第三方包到本地使用。
允许用户从NPM服务器下载并安装别人编写的命令行程序到本地使用。
允许用户将自己编写的包或命令行程序上传到NPM服务器供别人使用。
版本号
使用NPM下载和发布代码时都会接触到版本号。NPM使用语义版本号来管理代码,这里简单介绍一下。
语义版本号分为X.Y.Z三位,分别代表主版本号、次版本号和补丁版本号。当代码变更时,版本号按以下原则更新。
如果只是修复bug,需要更新Z位。
如果是新增了功能,但是向下兼容,需要更新Y位。
如果有大变动,向下不兼容,需要更新X位。
版本号有了这个保证后,在申明第三方包依赖时,除了可依赖于一个固定版本号外,还可依赖于某个范围的版本号。例如"argv": "0.0.x"表示依赖于0.0.x系列的最新版argv。
React
React 是一个用于构建用户界面的 JAVASCRIPT 库。
React 特点
1.声明式设计 −React采用声明范式,可以轻松描述应用。
2.高效 −React通过对DOM的模拟,最大限度地减少与DOM的交互。
3.灵活 −React可以与已知的库或框架很好地配合。
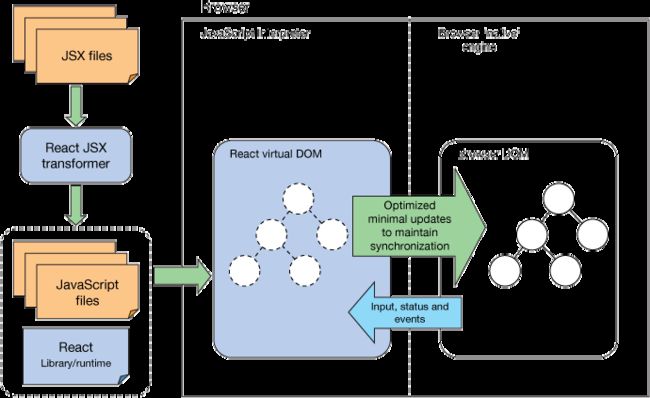
4.JSX − JSX 是 JavaScript 语法的扩展。React 开发不一定使用 JSX ,但我们建议使用它。
5.组件 − 通过 React 构建组件,使得代码更加容易得到复用,能够很好的应用在大项目的开发中。
6.单向响应的数据流 − React 实现了单向响应的数据流,从而减少了重复代码,这也是它为什么比传统数据绑定更简单。
react-router
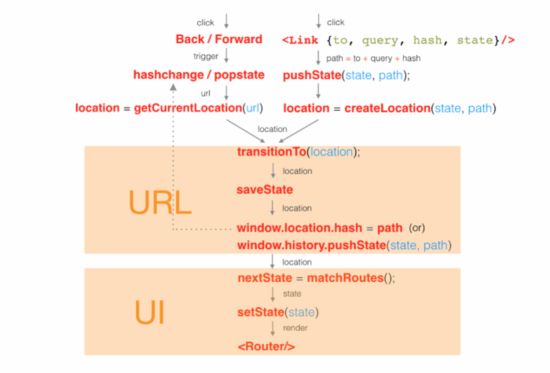
在 web 应用开发中,路由系统是不可或缺的一部分。在浏览器当前的 URL 发生变化时,路由系统会做出一些响应,用来保证用户界面与 URL 的同步。随着单页应用时代的到来,为之服务的前端路由系统也相继出现了。有一些独立的第三方路由系统,比如 director ,代码库也比较轻量。react-router 就是这样一个构建单页应用的路由系统
react-router 有如下的特征
Router 与 Route 一样都是 react 组件 ,它的 history 对象是整个路由系统的核心,它暴漏了很多属性和方法在路由系统中使用;
Route 的 path 属性表示路由组件所对应的路径,可以是绝对或相对路径,相对路径可继承;
Redirect 是一个重定向组件,有 from 和 to 两个属性;
Route 的 onEnter 钩子将用于在渲染对象的组件前做拦截操作,比如验证权限;
在 Route 中,可以使用 component 指定单个组件,或者通过 components 指定多个组件集合;
param 通过 /:param 的方式传递,这种写法与 express 以及 ruby on rails 保持一致,符合 RestFul 规范;
路由的基本原理
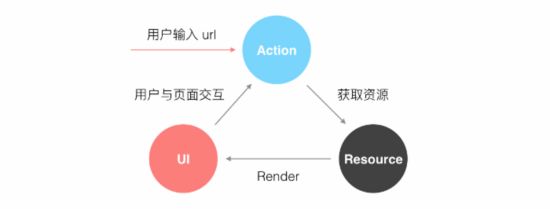
无论是传统的后端 MVC 主导的应用,还是在当下最流行的单页面应用中,路由的职责都很重要,但原理并不复杂,即保证视图和 URL 的同步,而视图可以看成是资源的一种表现。当用户在页面中进行操作时,应用会在若干个交互状态中切换,路由则可以记录下某些重要的状态,比如在一个博客系统中用户是否登录、在访问哪一篇文章、位于文章归档列表的第几页。而这些变化同样会被记录在浏览器的历史中,用户可以通过浏览器的前进、后退按钮切换状态,同样可以将 URL 分享给好友。简而言之,用户可以通过手动输入或者与页面进行交互来改变 URL,然后通过同步或者异步的方式向服务端发送请求获取资源(当然,资源也可能存在于本地),成功后重新绘制 UI,原理如下图所示:
amazeui-react
amazeui是中国首个开源的html5跨屏前端框架Amaze UI React基于 React.js 开发的 Web 组件库它基于 React 封装组件,不再疲于组织杂乱的 HTML 标签;组件可以按需组合、功能扩展方便。
gulp
gulp是前端开发过程中一种基于流的代码构建工具,是自动化项目的构建利器;她不仅能对网站资源进行优化,而且在开发过程中很多重复的任务能够使用正确的工具自动完成;使用她,不仅可以很愉快的编写代码,而且大大提高我们的工作效率。
gulp是基于Nodejs的自动任务运行器, 她能自动化地完成 javascript、coffee、sass、less、html/image、css 等文件的测试、检查、合并、压缩、格式化、浏览器自动刷新、部署文件生成,并监听文件在改动后重复指定的这些步骤。在实现上,她借鉴了Unix操作系统的管道(pipe)思想,前一级的输出,直接变成后一级的输入,使得在操作上非常简单。
流,简单来说就是建立在面向对象基础上的一种抽象的处理数据的工具。在流中,定义了一些处理数据的基本操作,如读取数据,写入数据等,程序员是对流进行所有操作的,而不用关心流的另一头数据的真正流向。流不但可以处理文件,还可以处理动态内存、网络数据等多种数据形式。
而gulp正是通过流和代码优于配置的策略来尽量简化任务编写的工作。这看起来有点“像jQuery”的方法,把动作串起来创建构建任务。早在Unix的初期,流就已经存在了。流在Node.js生态系统中也扮演了重要的角色,类似于*nix将几乎所有设备抽象为文件一样,Node将几乎所有IO操作都抽象成了stream的操作。因此用gulp编写任务也可看作是用Node.js编写任务。当使用流时,gulp去除了中间文件,只将最后的输出写入磁盘,整个过程因此变得更快。
易于使用
通过代码优于配置的策略,gulp 让简单的任务简单,复杂的任务可管理。
构建快速
利用 Node.js 流的威力,你可以快速构建项目并减少频繁的 IO 操作。
易于学习
通过最少的 API,掌握 gulp 毫不费力,构建工作尽在掌握:如同一系列流管道。
首先确保你已经正确安装了nodejs环境。然后以全局方式安装gulp:
npm install -g gulp
全局安装gulp后,还需要在每个要使用gulp的项目中都单独安装一次。把目录切换到你的项目文件夹中,然后在命令行中执行:
npm install gulp
如果想在安装的时候把gulp写进项目package.json文件的依赖中,则可以加上–save-dev:
npm install --save-dev gulp
这样就完成了gulp的安装,接下来就可以在项目中应用gulp了。
插件高质
gulp 严格的插件指南确保插件如你期望的那样简洁高质得工作。

flask+gunicorn
Flask 是一个使用 Python 编写的轻量级 Web 应用框架。其 WSGI 工具箱采用 Werkzeug ,模板引擎则使用 Jinja2。
Flask 也被称为 “microframework” ,因为它使用简单的核心,用 extension 增加其他功能。Flask没有默认使用的数据库、窗体验证工具。然而,Flask保留了扩增的弹性,可以用Flask-extension加入这些功能:ORM、窗体验证工具、文件上传、各种开放式身份验证技术。
Gunicorn (独角兽)是一个高效的Python WSGI Server,通常用它来运行 wsgi application(由我们自己编写遵循WSGI application的编写规范) 或者 wsgi framework(如Django,Paster),地位相当于Java中的Tomcat。
中文分词
词是最小的能够独立活动的有意义的语言成分,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,因此,中文词语分析是中文信息处理的基础与关键。
分词算法可分为三大类:
1.基于词典:基于字典、词库匹配的分词方法;(字符串匹配、机械分词法)
2.基于统计:基于词频度统计的分词方法;
3.基于规则:基于知识理解的分词方法。
第一类方法应用词典匹配、汉语词法或其它汉语语言知识进行分词,如:最大匹配法、最小分词方法等。这类方法简单、分词效率较高,但汉语语言现象复杂丰富,词典的完备性、规则的一致性等问题使其难以适应开放的大规模文本的分词处理。第二类基于统计的分词方法则基于字和词的统计信息,如把相邻字间的信息、词频及相应的共现信息等应用于分词,由于这些信息是通过调查真实语料而取得的,因而基于统计的分词方法具有较好的实用性。
jieba
jieba是一款效果很好,运行稳定的Python 中文分词组件
支持三种分词模式:
精确模式,试图将句子最精确地切开,适合文本分析;
全模式,把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义;
搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
支持繁体分词
支持自定义词典
基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图 (DAG)
采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合
对于未登录词,采用了基于汉字成词能力的 HMM 模型,使用了 Viterbi 算法
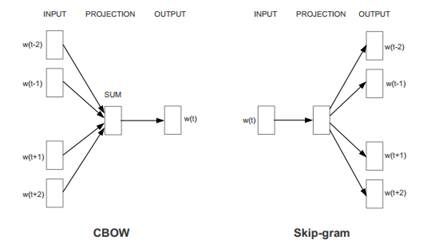
word2vec
word2vec是一个将单词转换成向量形式的工具。可以把对文本内容的处理简化为向量空间中的向量运算,计算出向量空间上的相似度,来表示文本语义上的相似度。
1.词向量是什么
自然语言理解的问题要转化为机器学习的问题,第一步肯定是要找一种方法把这些符号数学化。
NLP 中最直观,也是到目前为止最常用的词表示方法是 One-hot Representation,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。
2词向量的用法最常见的有两种:
- 直接用于神经网络模型的输入层。如 C&W 的 SENNA 系统中,将训练好的词向量作为输入,用前馈网络和卷积网络完成了词性标注、语义角色标注等一系列任务。再如 Socher 将词向量作为输入,用递归神经网络完成了句法分析、情感分析等多项任务。
- 作为辅助特征扩充现有模型。如 Turian 将词向量作为额外的特征加入到接近 state of the art 的方法中,进一步提高了命名实体识别和短语识别的效果。
tensorflow
TensorFlow™ 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等。TensorFlow 最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度神经网络方面的研究,但这个系统的通用性使其也可广泛用于其他计算领域。
什么是数据流图(Data Flow Graph)?
数据流图用“结点”(nodes)和“线”(edges)的有向图来描述数学计算。“节点” 一般用来表示施加的数学操作,但也可以表示数据输入(feed in)的起点/输出(push out)的终点,或者是读取/写入持久变量(persistent variable)的终点。“线”表示“节点”之间的输入/输出关系。这些数据“线”可以输运“size可动态调整”的多维数据数组,即“张量”(tensor)。张量从图中流过的直观图像是这个工具取名为“Tensorflow”的原因。一旦输入端的所有张量准备好,节点将被分配到各种计算设备完成异步并行地执行运算。
TensorFlow的特征
高度的灵活性
真正的可移植性(Portability)
将科研和产品联系在一起
自动求微分
多语言支持
性能最优化
tensorlayer
TensorLayer 是为研究人员和工程师设计的一款基于Google TensorFlow开发的深度学习与强化学习库。 它提供高级别的(Higher-Level)深度学习API,这样不仅可以加快研究人员的实验速度,也能够减少工程师在实际开发当中的重复工作。 TensorLayer非常易于修改和扩展,这使它可以同时用于机器学习的研究与应用。 此外,TensorLayer 提供了大量示例和教程来帮助初学者理解深度学习,并提供大量的官方例子程序方便开发者快速找到适合自己项目的例子。
RNN
循环神经网络(Recurrent Neural Networks,RNNs)已经在众多自然语言处理(Natural Language Processing, NLP)中取得了巨大成功以及广泛应用。RNNs已经被在实践中证明对NLP是非常成功的。如词向量表达、语句合法性检查、词性标注等。在RNNs中,目前使用最广泛最成功的模型便是LSTMs(Long Short-Term Memory,长短时记忆模型)模型