概述
Java存在三种es的客户端
- Transport Client
- Java Low Level Rest Client
- Java High Level Rest Client
造成这种混乱的原因是es开始是没有Java版的客户端,但Java自己是可以简单的支持es的API,所以有了第一种客户端(Transport Client)。后来官方推出了第二种版本(Java Low Level Rest Client),但缺点也是显而易见的,因为从第一种版本迁移到第二版本工作量是比较的大的,官方还特意出一堆文档来提供参考。而第三种版本的客户端是兼容两种客户端的优点,他是在第二种版本的基础上进行了封装,也让代码迁移变得更方便,但依然存在缺点,小的版本更新频繁,经常出现莫名其妙的错误,我们尽量保持客户端和服务器相同的版本。lz这边的用的是es 6.6.2版本
整合
搭建springboot框架就不介绍了,直接看下依赖jar
org.elasticsearch.client
elasticsearch-rest-high-level-client
6.6.2
创建EsConfig类
import org.apache.http.HttpHost; import org.elasticsearch.client.RestClient; import org.elasticsearch.client.RestHighLevelClient; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; /** * * Description:es配置 * @author huangweicheng * @date 2020/3/19 */ @Configuration public class EsConfig { @Bean public RestHighLevelClient restHighLevelClient(){ RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( new HttpHost("10.105.9.119",9200,"http") ) ); return client; } }
接下去就很简单了,去调用客户端的API操作即可
查找
先看下在服务端的数据

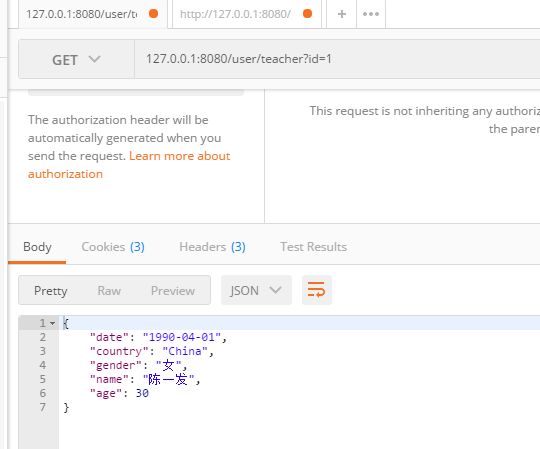
查询id为1的文档
@Autowired private RestHighLevelClient client; @GetMapping("/teacher") public ResponseEntity get(@RequestParam(value = "id",defaultValue = "") String id) throws IOException { try { if (id.isEmpty()){ return new ResponseEntity(HttpStatus.NOT_FOUND); } GetRequest request = new GetRequest("user","teacher",id); GetResponse result = client.get(request, RequestOptions.DEFAULT); if (!result.isExists()){ return new ResponseEntity(HttpStatus.NOT_FOUND); } return new ResponseEntity(result.getSource(),HttpStatus.OK); }catch (Exception e){ e.printStackTrace(); } return null; }
结果
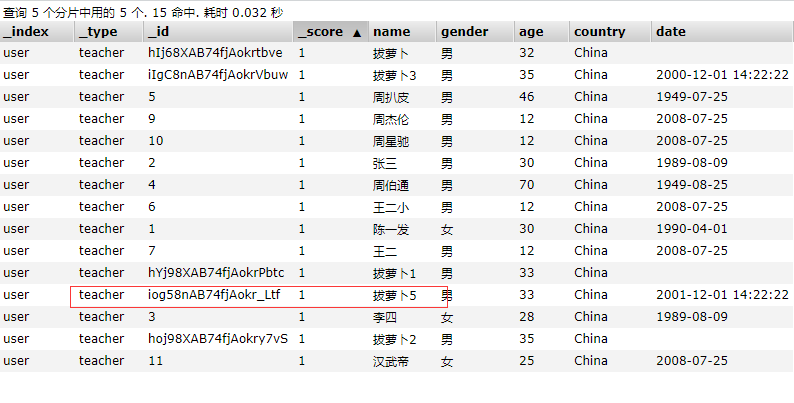
添加
@PostMapping("/add")
public ResponseEntity add(
@RequestParam String name,
@RequestParam String gender,
@RequestParam int age,
@RequestParam String country,
@RequestParam String date
) throws IOException {
XContentBuilder xContentBuilder = XContentFactory.jsonBuilder()
.startObject()
.field("name",name)
.field("gender",gender)
.field("age",age)
.field("country",country)
.field("date",date)
.endObject();
IndexRequest indexRequest = new IndexRequest("user","teacher");
indexRequest.source(xContentBuilder);
IndexResponse response = client.index(indexRequest,RequestOptions.DEFAULT);
return new ResponseEntity(response.getId(),HttpStatus.OK);
}
结果

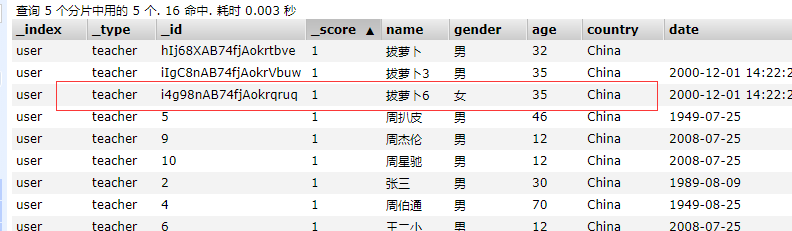
修改
@PutMapping("/update/teacher")
public ResponseEntity update(
@RequestParam(name = "id") String id,
@RequestParam(name = "name",required = false) String name,
@RequestParam(name = "gender",required = false) String gender
) throws IOException
{
UpdateRequest updateRequest = new UpdateRequest("user","teacher",id);
XContentBuilder xContentBuilder = XContentFactory.jsonBuilder()
.startObject()
.field("name",name)
.field("gender",gender)
.endObject();
updateRequest.doc(xContentBuilder);
UpdateResponse result = client.update(updateRequest,RequestOptions.DEFAULT);
return new ResponseEntity(result.getId(),HttpStatus.OK);
}

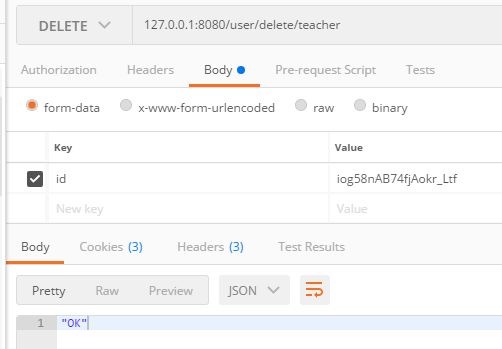
删除
将刚才添加的数据删除
@DeleteMapping("/delete/teacher")
public ResponseEntity delete(@RequestParam(name = "id") String id) throws IOException
{
DeleteRequest deleteRequest = new DeleteRequest("user","teacher",id);
DeleteResponse deleteResponse = client.delete(deleteRequest,RequestOptions.DEFAULT);
return new ResponseEntity(deleteResponse.status(),HttpStatus.OK);
}
以上就是springboot整合es后基本操作,下面是完整的伪代码
import com.alibaba.fastjson.annotation.JSONField; import org.elasticsearch.action.delete.DeleteRequest; import org.elasticsearch.action.delete.DeleteResponse; import org.elasticsearch.action.get.GetRequest; import org.elasticsearch.action.get.GetResponse; import org.elasticsearch.action.index.IndexRequest; import org.elasticsearch.action.index.IndexResponse; import org.elasticsearch.action.update.UpdateRequest; import org.elasticsearch.action.update.UpdateResponse; import org.elasticsearch.client.RequestOptions; import org.elasticsearch.client.RestHighLevelClient; import org.elasticsearch.common.xcontent.XContentBuilder; import org.elasticsearch.common.xcontent.XContentFactory; import org.elasticsearch.index.get.GetResult; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.format.annotation.DateTimeFormat; import org.springframework.http.HttpStatus; import org.springframework.http.ResponseEntity; import org.springframework.web.bind.annotation.*; import java.io.IOException; import java.util.Date; /** * * Description: * @author huangweicheng * @date 2020/3/19 */ @RestController @ResponseBody @RequestMapping("/user") public class UserController { @Autowired private RestHighLevelClient client; @GetMapping("/teacher") public ResponseEntity get(@RequestParam(value = "id",defaultValue = "") String id) throws IOException { try { if (id.isEmpty()){ return new ResponseEntity(HttpStatus.NOT_FOUND); } GetRequest request = new GetRequest("user","teacher",id); GetResponse result = client.get(request, RequestOptions.DEFAULT); if (!result.isExists()){ return new ResponseEntity(HttpStatus.NOT_FOUND); } return new ResponseEntity(result.getSource(),HttpStatus.OK); }catch (Exception e){ e.printStackTrace(); } return null; } @PostMapping("/add") public ResponseEntity add( @RequestParam String name, @RequestParam String gender, @RequestParam int age, @RequestParam String country, @RequestParam String date ) throws IOException { XContentBuilder xContentBuilder = XContentFactory.jsonBuilder() .startObject() .field("name",name) .field("gender",gender) .field("age",age) .field("country",country) .field("date",date) .endObject(); IndexRequest indexRequest = new IndexRequest("user","teacher"); indexRequest.source(xContentBuilder); IndexResponse response = client.index(indexRequest,RequestOptions.DEFAULT); return new ResponseEntity(response.getId(),HttpStatus.OK); } @DeleteMapping("/delete/teacher") public ResponseEntity delete(@RequestParam(name = "id") String id) throws IOException { DeleteRequest deleteRequest = new DeleteRequest("user","teacher",id); DeleteResponse deleteResponse = client.delete(deleteRequest,RequestOptions.DEFAULT); return new ResponseEntity(deleteResponse.status(),HttpStatus.OK); } @PutMapping("/update/teacher") public ResponseEntity update( @RequestParam(name = "id") String id, @RequestParam(name = "name",required = false) String name, @RequestParam(name = "gender",required = false) String gender ) throws IOException { UpdateRequest updateRequest = new UpdateRequest("user","teacher",id); XContentBuilder xContentBuilder = XContentFactory.jsonBuilder() .startObject() .field("name",name) .field("gender",gender) .endObject(); updateRequest.doc(xContentBuilder); UpdateResponse result = client.update(updateRequest,RequestOptions.DEFAULT); return new ResponseEntity(result.getId(),HttpStatus.OK); } }