如果现在 Google 上搜深度学习,我们会发现深度学习的关注度从2012年到2017年上升了数十倍。尤其在中国,近两年几乎都在谈机器学习、人工智能。在深度学习这一块又拍云也进行了诸多的实践。
先介绍一下又拍云在人工智能方面的首个产品——又拍云内容识别服务。“内容识别”是又拍云“图像视觉”项目下的第一个产品,是基于人工智能、大数据分析而研发的新型信息安全解决方案,能实时处理多媒体内容(图片、视频、直播等),识别色情、广告、暴恐等多种信息,目前色情内容识别正确率已高达 99.7%,而且在不断提高中。
本文以又拍云内容识别服务为例,向大家展示又拍云在深度学习系统中的实践。
深度学习理论
在介绍深度学习之前,先简单介绍一下深度学习的基本理论知识。
深度学习—分类器与分类算法
1.分类器:常见的分类方式有垃圾邮件过滤、手写数字识别、图片分类、鉴黄等;
2.分类算法:深度学习算法有朴素按贝叶斯算法,以及基于 KNN、SVM 的算法和人工神经网络算法等;
从图 1 我们可以看到传统机器学习算法准确率前期会随着数据量的增长有所上身,但增长到一个点时就很难继续增长,而基于人工神经网络的模型随着数据量的增长,准确率会持续上升。
目前所处的互联网时代,数据积累相对比较容易,且拥有很大的数据积累量,非常适合机器深度学习。所以又拍云选用的分类器是人工神经网络。

△ 图1 传统机器学习 vs 人工神经网络
图 2 所示为人工神经网络示意图,人工神经网络由很多的层组成,每一层有很多节点,节点之间有边相连的,每条边都有一个权重。对于文本来说输入值是每一个字符,对于图片来说输入值就是每一个像素。

△ 图2 人工神经网络
人工神经网络通过前向传播对输入值,进行权值运算,最后一层层传下去得到最终输出预测的值。再通过反向传播,与真实值做对比修正前向传播的权值和偏置。

图3 反向传播
反向传播是如何更新参数 W 和 B 的?通过梯度下降的算法,运用梯度下降的算法可以找出一组 W 和 B,使得函数 C 最小,在样本上找到最优或者近似最优的 W 和 B ,之后使用 W 和 B 进行预测。

△ 图4 梯度下降
深度学习硬件&软件准备
在了解深度学习的基本知识之后,我们看下需要哪些硬件、软件工具。
硬件
下图表格是又拍云第一台深度学习训练机器的硬件配置:

软件
深度学习机器配置的操作系统,又拍云选择了 Ubuntu 16.04,框架选择 Caffe 和 Tensorflow,下文我们也主要介绍这两种框架。
Caffe 框架
Caffe 容易入门,性能优异,支持 python 和 C++ 接口,同时还有很多 model zoo,可以轻松找到语音识别、计算机图片识别、人脸识别等类型的深度学习模型。但是 Caffe 存在难以扩展,设计架构没有为扩展留好接口,只能单机运行且安装太复杂等缺点,并且 Caffe 每一个版本都需要重新编写 C++ 代码。
TensorFlow 框架
TensorFlow 支持 GPU、分布式(弥补了Caffe 不支持的缺点),拥有 TensorBoard 功能,可以训练整个可视化的过程,同时还有活跃的社区和完善的文档,并且功能强大、容易扩展。但是 TensorFlow 的模型没有 Caffe 直观,通过文本文件定义的 Caffe 不用编辑代码,而使用 TensorFlow 需要有编写能力和算法功底。
又拍云深度学习实践
什么是内容识别系统
内容识别:主要是指色情、广告、暴恐等图像、视频内容的智能鉴别;
内容识别系统原理:上传图片到样本管理平台,人工进行标注图片是不是性感图、色情图、广告图或者是暴恐图片,标注完成后将它放到线下处理平台训练,得出训练模型和结果,再将模型拿到线上进行智能鉴别。

△ 图5 又拍云图片鉴别系统原理
又拍云内容识别后台
图6是又拍云图片鉴黄控制台,用户将图片上传到又拍云鉴黄控制台后,就可以实现色情识别,不需要自己开发后台。
图7是又拍云人脸相似度识别后台,用户将摄像头、图片接入控制台后,系统会自动判断图片里面的人物。

△ 图6 图片鉴黄

△图7 人脸相似度识别
深度学习三要素:数据、模型、计算
数据
数据来源:主要通过对初始数据图片进行人工标注和机器标注。数据样本非常的重要,好的样本等于成功了一半。
模型
从 Caffe model zoo 找到适用模型之后主要针对两个文件进行修改调整:第一个文件是输入,比如说修改一下 data 文件,或将输入的地址改成刚刚定义的 TXT 文件;第二个是 solver 文件,对 baselr 参数进行调整。
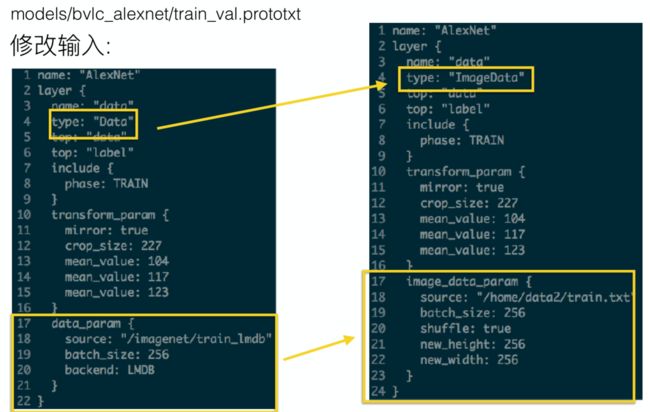
△ 图8 模型输入修改
调整完输入和 solver 文件就可以进行深度学习训练了。根据任务的大小,训练往往会花费几个小时、甚至几周。训练完之后 Caffe 会生成 model 文件,可以直接用 Caffe text 将模型的参数代入,对测试文件进行预测,并输出预测的结果。
计算
训练计算方式主要有命令行和 python 接口两种方式。上文提到的训练方式主要是以命令行的方式进行的。此外我们还可以通过 python 接口进行训练。
通过 python 接口进行预测的 Caffe 主体代码,在开始时定义 Caffe 的 net,这里需要指定模型,指定的参数文件。图9 中间一段代码是对输入的图片进行诸如将像素减去平均值这类的预处理。完成之后输入需要进行预测的图片,将图片的地址给它,调用前向传播,就可以得到一个输出,这里是不需要做反向传播,因为我们是进行预测而不是训练,最后可以把预测结果打印出来。

图9 python 接口
深度学习训练之外的要点
1.对模型进行二次调优
Fine-turning,中文翻译“微调”,如果我们只有几千张、几万张图片,很难训练优质的模型。训练优异的模型需要花费的长达几天、几周时间。我们想快速得到训练结果,可以对之前训练好的版本进行二次调优,在原有的文件 model 上进行二次训练,就把预训练的模型加在 Caffe 后面,Caffe 会使用后面的参数进行初始化。如果不指定的话,Caffe 的初始化是随机的。
当数据量增大后,我们会发现一台机器运行速度太慢,需要使用多台机器进行训练,但是 Caffe 只支持多 GPU 模式,不支持多机器联机模式,所以涉及到多机器训练时,我们可以选择 TensorFlow。
2.Data Augmentation
当图片数量达到一定数量级后,因为互联网里的图片都互相链接,难免相同,这带来了样本增长困难的问题。
Data Augmentation 算法通过对同一张图片进行旋转、缩放以及翻转等操作,将图10老鼠增强了很多倍。但是 Caffe 原生系统中是不支持数据增强的,这需要自己编写程序。

△ 图10 增加正样本数量
3.Mesos+Docker 部署
最后当参数和模型都设置训练完成之后,我们可以通过 Mesos+Docker 的模型将它部署到在线对外服务。
Mesos+Docker 部署有两个模式:CPU模式和GPU模式
CPU模式:
- 优点:简单、不受机器限制;
- 缺点:速度慢,单核处理一张图片需要250ms
- 适用于异步处理任务
GPU模式:
- 优点:速度快,性能是CPU的八倍
- 特性:mesos:--docker=nvidia-docker(使用 GPU 模式,必须在启动 mesos 时设置好这个参数)
- 适用于同步处理
总结
1.pilow-simd 规换 PIL:因为PIL不支持CPU的高级的指令,所以将 pilow-simd 替换的,性能大概能提高25%左右;
2.样本越多越好,样本越多训练出来的模型就越精准;
3.batch_size:这个值一次训练图片的数量,需要我们将数值能调到最大;
4.base_lr、 weight_decay 等参数需要进行多次重试,不断地调整设定。
上述就是又拍云深度学习的实践,主要涉及硬件、软件,以及框架选型,感兴趣的朋友可以自己尝试操作一下。
推荐阅读:
性感与色情有多远——你不知道的图片鉴黄那些事儿